【Python3】字符解码与编码
编码种类:
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系,
- Unicode 2-4字节,已经收录136690个字符,并还在一直不断扩张中...
Unicode 起到了2个作用:
- 直接支持全球所有语言,每个国家都可以不用再使用自己之前的旧编码了,用unicode就可以了。
- unicode包含了跟全球所有国家编码的映射关系
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的。
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符,优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符
总结:UTF是为unicode编码设计的一种 在存储和传输时节省空间的编码方案。
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。存到硬盘时以何种编码存在,再从硬盘读出来时,就必须以何种编码读,否则乱码
编码的转换
虽然有了unicode 和 utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
- 让美国人的电脑上都装上gbk编码
- 把你的软件编码以utf-8编码
第1种方法几乎不可能实现,第2种方法比较简单。 但是也只能是针对新开发的软件。 如果你之前开发的软件就是以gbk编码的,上百万行代码可能已经写出去了,重新编码成utf-8格式也会费很大力气。
所以 , 针对已经用gbk开发完毕的项目,以上2种方案都不能轻松的让项目在美国人电脑上正常显示,难道没有别的办法了么?
有, unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,你写的是gbk的“好好学习”,unicode能自动知道它在unicode中的“好好学习”的编码是什么,这意味着,无论以什么编码存储的数据
,只要软件把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那gbk软件放到美国电脑 上,加载到内存里,变成了unicode,中文就可以正常展示
unicode与gbk的映射表 http://www.unicode.org/charts/
Python3的执行过程:
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明,默认文件编码是utf-8
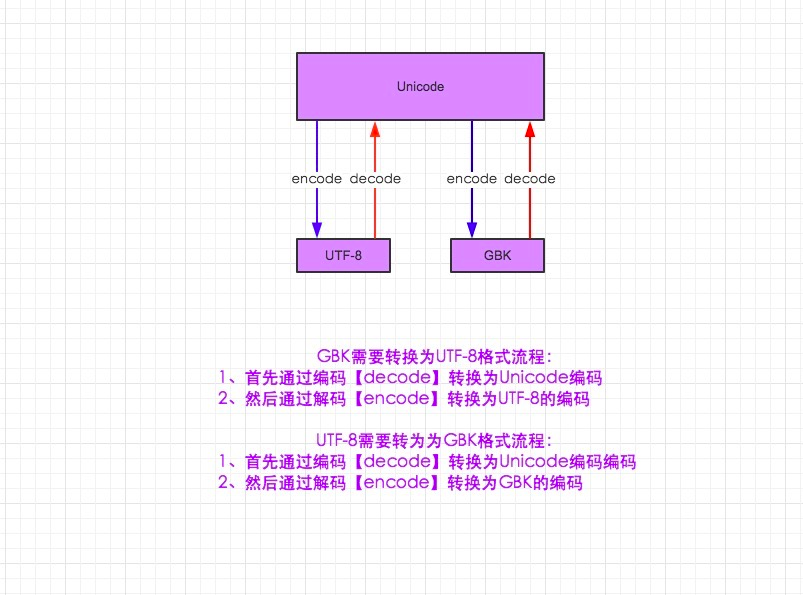
str=u'好好学习天天向上' #加u表示unicode,默认也是unicode
utf-8_to _gbk = str.decode('utf-8').encode('gbk')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号