

使用自动模型
本文通过文本分类任务演示了HuggingFace自动模型使用方法,既不需要手动计算loss,也不需要手动定义下游任务模型,通过阅读自动模型实现源码,提高NLP建模能力。
一.任务和数据集介绍
1.任务介绍
前面章节通过手动方式定义下游任务模型,HuggingFace也提供了一些常见的预定义下游任务模型,如下所示:
 说明:包括预测下一个词,文本填空,问答任务,文本摘要,文本分类,命名实体识别,翻译等。
说明:包括预测下一个词,文本填空,问答任务,文本摘要,文本分类,命名实体识别,翻译等。
2.数据集介绍
本文使用ChnSentiCorp数据集,不清楚的可以参考中文情感分类介绍。一些样例如下所示:
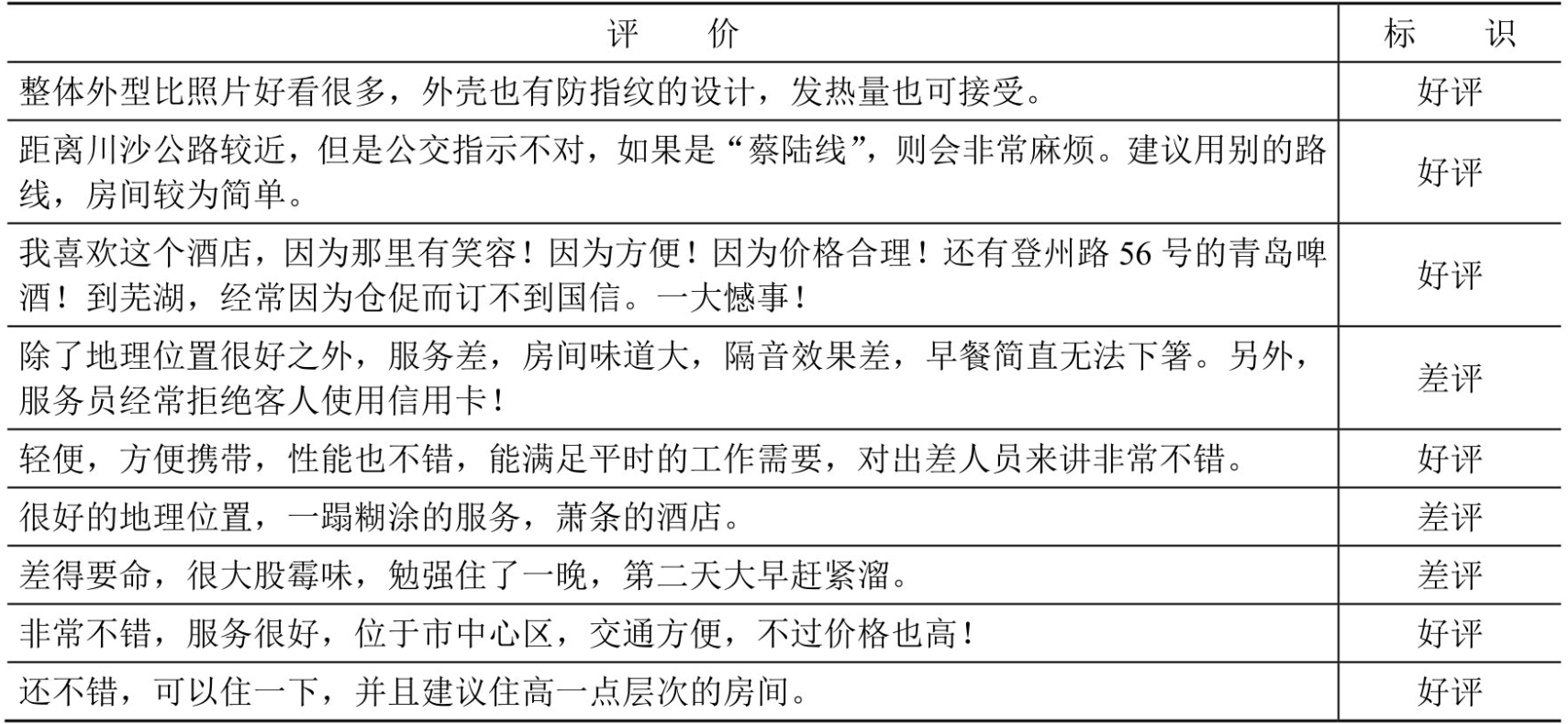
二.准备数据集
1.使用编码工具
def load_encode_tool(pretrained_model_name_or_path):
"""
加载编码工具
"""
tokenizer = BertTokenizer.from_pretrained(Path(f'{pretrained_model_name_or_path}'))
return tokenizer
if __name__ == '__main__':
# 测试编码工具
pretrained_model_name_or_path = r'L:/20230713_HuggingFaceModel/bert-base-chinese'
tokenizer = load_encode_tool(pretrained_model_name_or_path)
print(tokenizer)
输出结果如下所示:
BertTokenizer(name_or_path='L:\20230713_HuggingFaceModel\bert-base-chinese', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
2.定义数据集
直接使用HuggingFace数据集对象,如下所示:
def load_dataset_from_disk():
pretrained_model_name_or_path = r'L:\20230713_HuggingFaceModel\ChnSentiCorp'
dataset = load_from_disk(pretrained_model_name_or_path)
return dataset
if __name__ == '__main__':
# 加载数据集
dataset = load_dataset_from_disk()
print(dataset)
输出结果如下所示:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 9600
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
})
3.定义计算设备
# 定义计算设备
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
# print(device)
4.定义数据整理函数
def collate_fn(data):
sents = [i['text'] for i in data]
labels = [i['label'] for i in data]
#编码
data = tokenizer.batch_encode_plus(batch_text_or_text_pairs=sents, # 输入文本
truncation=True, # 是否截断
padding=True, # 是否填充
max_length=512, # 最大长度
return_tensors='pt') # 返回的类型
#转移到计算设备
for k, v in data.items():
data[k] = v.to(device)
data['labels'] = torch.LongTensor(labels).to(device)
return data
5.定义数据集加载器
# 数据集加载器
loader = torch.utils.data.DataLoader(dataset=dataset['train'], batch_size=16, collate_fn=collate_fn, shuffle=True, drop_last=True)
print(len(loader))
# 查看数据样例
for i, data in enumerate(loader):
break
for k, v in data.items():
print(k, v.shape)
输出结果如下所示:
600
input_ids torch.Size([16, 200])
token_type_ids torch.Size([16, 200])
attention_mask torch.Size([16, 200])
labels torch.Size([16])
三.加载自动模型
使用HuggingFace的AutoModelForSequenceClassification工具类加载自动模型,来实现文本分类任务,代码如下:
# 加载预训练模型
model = AutoModelForSequenceClassification.from_pretrained(Path(f'{pretrained_model_name_or_path}'), num_labels=2)
model.to(device)
print(sum(i.numel() for i in model.parameters()) / 10000)
四.训练和测试
1.训练
需要说明自动模型本身包括loss计算,因此在train()中就不再需要手工计算loss,如下所示:
def train():
# 定义优化器
optimizer = AdamW(model.parameters(), lr=5e-4)
# 定义学习率调节器
scheduler = get_scheduler(name='linear', # 调节器名称
num_warmup_steps=0, # 预热步数
num_training_steps=len(loader), # 训练步数
optimizer=optimizer) # 优化器
# 将模型切换到训练模式
model.train()
# 按批次遍历训练集中的数据
for i, data in enumerate(loader):
# print(i, data)
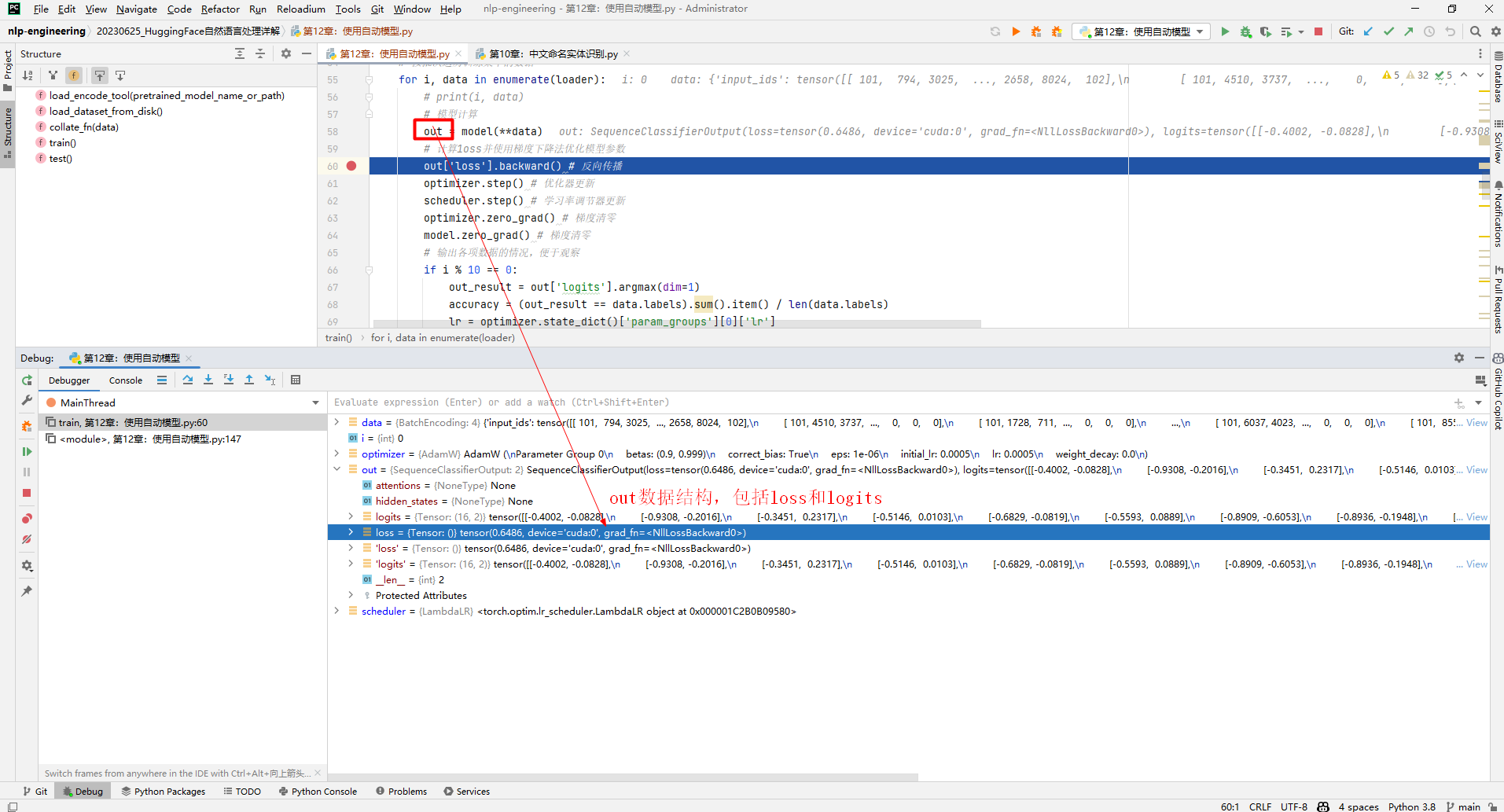
# 模型计算
out = model(**data)
# 计算1oss并使用梯度下降法优化模型参数
out['loss'].backward() # 反向传播
optimizer.step() # 优化器更新
scheduler.step() # 学习率调节器更新
optimizer.zero_grad() # 梯度清零
model.zero_grad() # 梯度清零
# 输出各项数据的情况,便于观察
if i % 10 == 0:
out_result = out['logits'].argmax(dim=1)
accuracy = (out_result == data.labels).sum().item() / len(data.labels)
lr = optimizer.state_dict()['param_groups'][0]['lr']
print(i, out['loss'].item(), lr, accuracy)
其中,out数据结构如下所示:
2.测试
def test():
# 定义测试数据集加载器
loader_test = torch.utils.data.DataLoader(dataset=dataset['test'],
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True)
# 将下游任务模型切换到运行模式
model.eval()
correct = 0
total = 0
# 按批次遍历测试集中的数据
for i, data in enumerate(loader_test):
# 计算5个批次即可,不需要全部遍历
if i == 5:
break
print(i)
# 计算
with torch.no_grad():
out = model(**data)
# 统计正确率
out = out['logits'].argmax(dim=1)
correct += (out == data.labels).sum().item()
total += len(data.labels)
print(correct / total)
五.深入自动模型源代码
1.加载配置文件过程
在执行AutoModelForSequenceClassification.from_pretrained(Path(f'{pretrained_model_name_or_path}'), num_labels=2)时,实际上调用了AutoConfig.from_pretrained(),该函数返回的config对象内容如下所示:
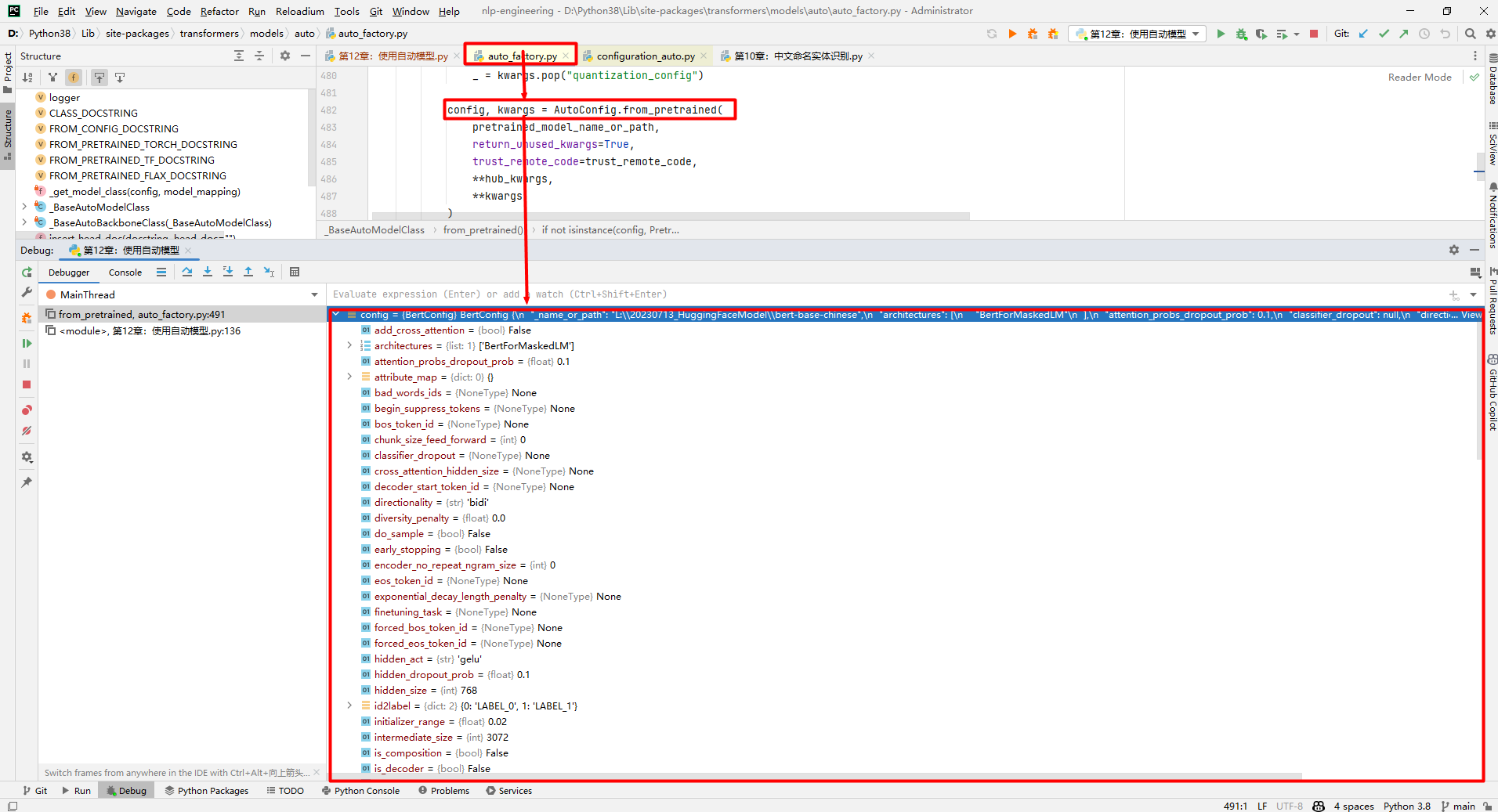 config对象如下所示:
config对象如下所示:
BertConfig {
"_name_or_path": "L:\\20230713_HuggingFaceModel\\bert-base-chinese",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.32.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
(1)_name_or_path=bert-base-chinese:模型名字。
(2)attention_probs_DropOut_prob=0.1:注意力层DropOut的比例。
(3)hidden_act=gelu:隐藏层的激活函数。
(4)hidden_DropOut_prob=0.1:隐藏层DropOut的比例。
(5)hidden_size=768:隐藏层神经元的数量。
(6)layer_norm_eps=1e-12:标准化层的eps参数。
(7)max_position_embeddings=512:句子的最大长度。
(8)model_type=bert:模型类型。
(9)num_attention_heads=12:注意力层的头数量。
(10)num_hidden_layers=12:隐藏层层数。
(11)pad_token_id=0:PAD的编号。
(12)pooler_fc_size=768:池化层的神经元数量。
(13)pooler_num_attention_heads=12:池化层的注意力头数。
(14)pooler_num_fc_layers=3:池化层的全连接神经网络层数。
(15)vocab_size=21128:字典的大小。
2.初始化模型过程
BertForSequenceClassification类构造函数包括一个BERT模型和全连接神经网络,基本思路为通过BERT提取特征,通过全连接神经网络进行分类,如下所示:
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.config = config
self.bert = BertModel(config)
classifier_dropout = (
config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob
)
self.dropout = nn.Dropout(classifier_dropout)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Initialize weights and apply final processing
self.post_init()
通过forward()函数可证明以上推测,根据问题类型为regression(MSELoss()损失函数)、single_label_classification(CrossEntropyLoss()损失函数)和multi_label_classification(BCEWithLogitsLoss()损失函数)选择损失函数。
参考文献:
[1]HuggingFace自然语言处理详解:基于BERT中文模型的任务实战
[2]https://github.com/ai408/nlp-engineering/blob/main/20230625_HuggingFace自然语言处理详解/第12章:使用自动模型.py


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)