
利用Hugging Face中的模型进行句子相似性实践
Hugging Face是什么?它作为一个GitHub史上增长最快的AI项目,创始人将它的成功归功于弥补了科学与生产之间的鸿沟。什么意思呢?因为现在很多AI研究者写了大量的论文和开源了大量的代码,但是AI工程师又不能直接很好的使用,而Hugging Face将这些AI模型进行了更好的封装,满足了AI工程师的生产实践需要,大大降低了AI模型使用的门槛。Hugging Face已经共享了超100,000个预训练模型,10,000个数据集,涵盖了 NLP、计算机视觉、语音、时间序列、生物学、强化学习等领域,以帮助科学家和相关从业者更好地构建模型,并将其用于产品或工作流程。最近宣布融资1亿美元,这使其估值达到了20亿美元。
一.Hugging Face模型
模型页面包括各种AI任务,使用的深度学习框架,各种数据集,语言种类,许可证类型等。重点说下各种类型的任务如下:
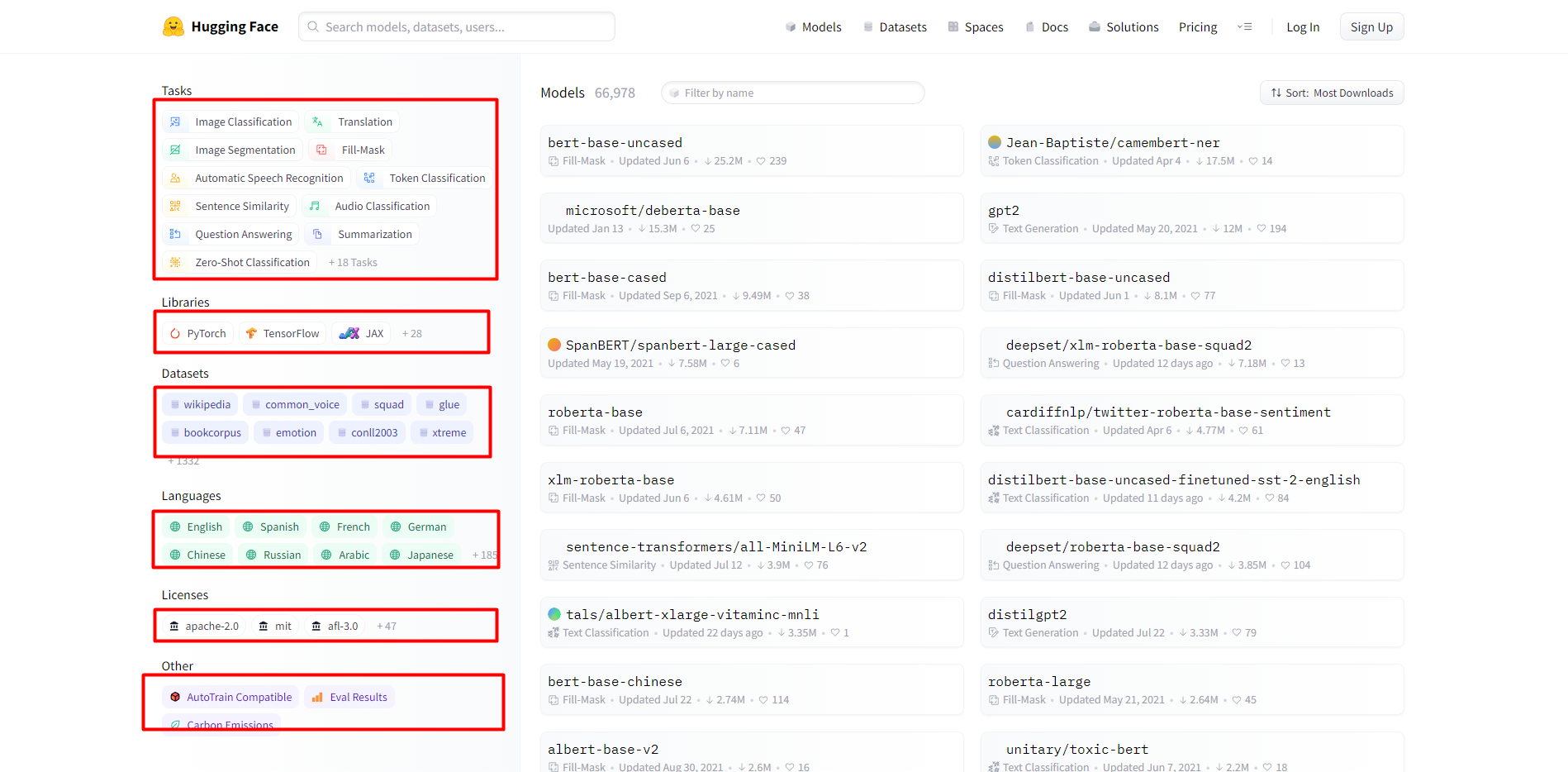
1.计算机视觉任务
Image Classification,Image Segmentation,Image-to-Image,Unconditional Image Generation,Object Detection
2.自然语言处理任务
Translation,Fill-Mask,Token Classification,Sentence Similarity,Question Answering,Summarization,Zero-Shot Classification,Text Classification,Text2Text Generation,Text Generation,Conversational,Table Question Answering
3.音频任务
Automatic Speech Recognition,Audio Classification,Text-to-Speech,Audio-to-Audio,Voice Activity Detection
4.多模态任务
Feature Extraction,Text-to-Image,Visual Question Answering,Image-to-Text
5.Tabular任务
Tabular Classification,Tabular Regression
6.强化学习任务
Reinforcement Learning
二.Hugging Face文档
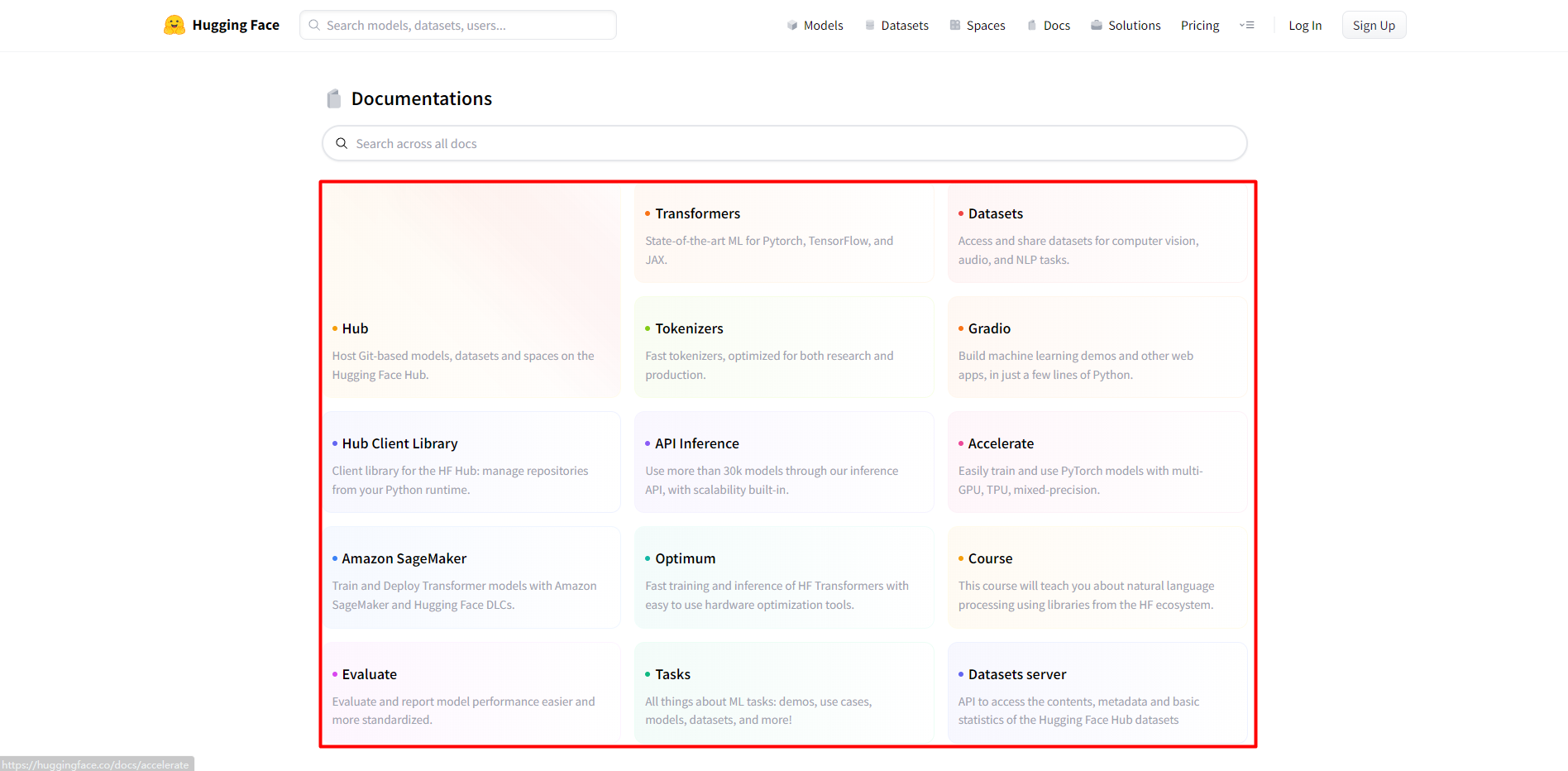
1.Hub:在Hugging Face Hub上托管基于Git的模型、数据集和空间。
2.Transformers:Pytorch、TensorFlow和JAX的最新ML。
3.Datasets:访问和共享CV、Audio和NLP任务的数据集。
4.Tokenizers:快速tokenizers,针对研究和生产进行了优化。
5.Gradio:用几行Python构建机器学习演示和其它Web应用程序。
6.Hub Client Library:HF Hub的客户端库:从Python运行时管理存储库。
7.API Inference:通过推理API可以使用超过30k个模型,并且内置可伸缩性。
8.Accelerate:使用multi-GPU,TPU,混合精度容易的训练和使用PyTorch模型。
9.Amazon SageMaker:使用Amazon SageMaker和Hugging Face DLCs训练和部署Transformer模型。
10.Optimum:容易的使用硬件优化工具,来实现HF Transformers的快速训练和推理。
11.Course:这个课程教你使用HF生态系统的类库来解决NLP问题。
12.Evaluate:更加容易和标准化的评估和报告模型的性能。
13.Tasks:关于机器学习任务的一切:演示,使用例子,模型,数据集和更多。
14.Datasets server:访问Hugging Face Hub数据集的内容、metadata和基本统计。
三.huggingface/transformers源码
这个库Transformers主要是关于Pytorch、TensorFlow和JAX的机器学习最新进展。Transformers提供了数以千计的预训练模型,支持100多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨让最先进的AI技术人人易用。源码结构如下:
四.选择句子相似性模型
1.安装transformers库
通过pip命令安装transformers库:
pip install transformers
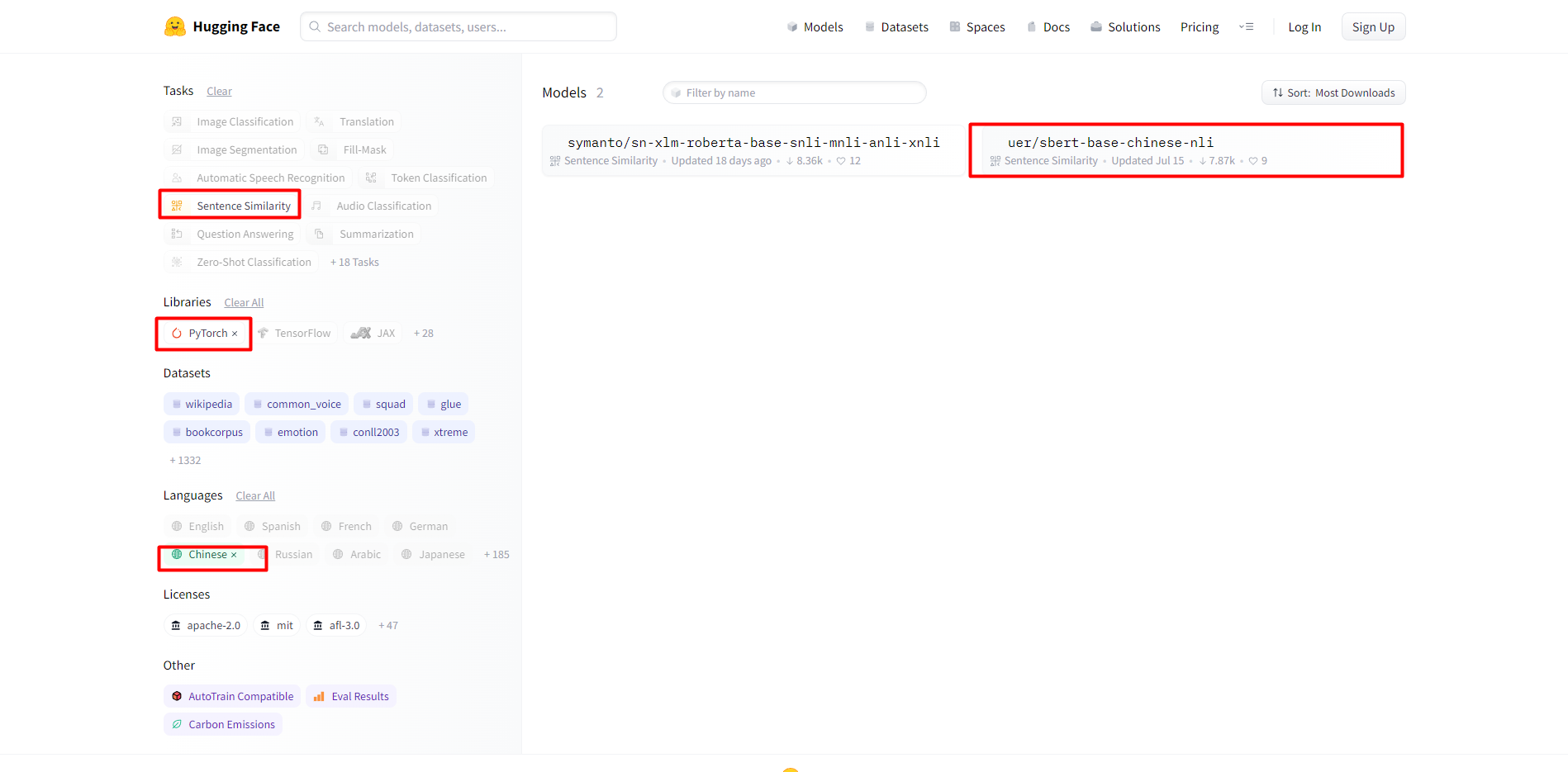
2.选择模型
任务选择句子相似性,类库选择PyTorch,语言选择中文:
3.模型信息介绍
这个页面主要对模型描述,训练数据,训练过程,在线演示等进行了介绍:
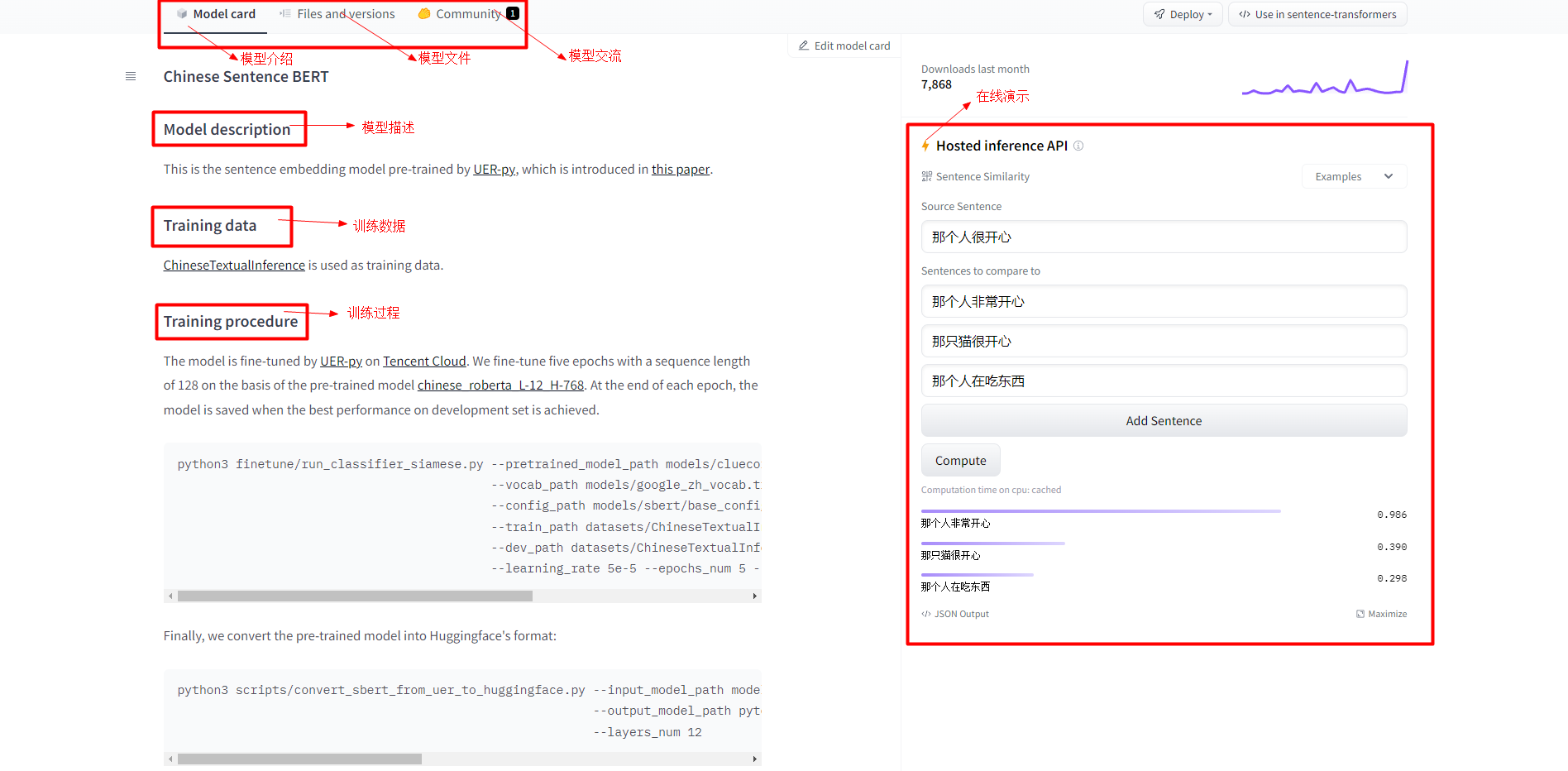
这是通过UER-py项目预训练的句子嵌入模型[9][10],训练数据使用的[11],在预训练模型chinese_roberta_L-12_H-768的基础上微调了5个epochs,序列长度为128。在每个epoch结束时,保存在development set上性能最好的模型。微调脚本如下:
python3 finetune/run_classifier_siamese.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--config_path models/sbert/base_config.json \
--train_path datasets/ChineseTextualInference/train.tsv \
--dev_path datasets/ChineseTextualInference/dev.tsv \
--learning_rate 5e-5 --epochs_num 5 --batch_size 64
最后把预训练模型转换为Huggingface的格式:
python3 scripts/convert_sbert_from_uer_to_huggingface.py --input_model_path models/finetuned_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
4.模型文件介绍
主要介绍了训练好的AI模型都有哪些文件组成:
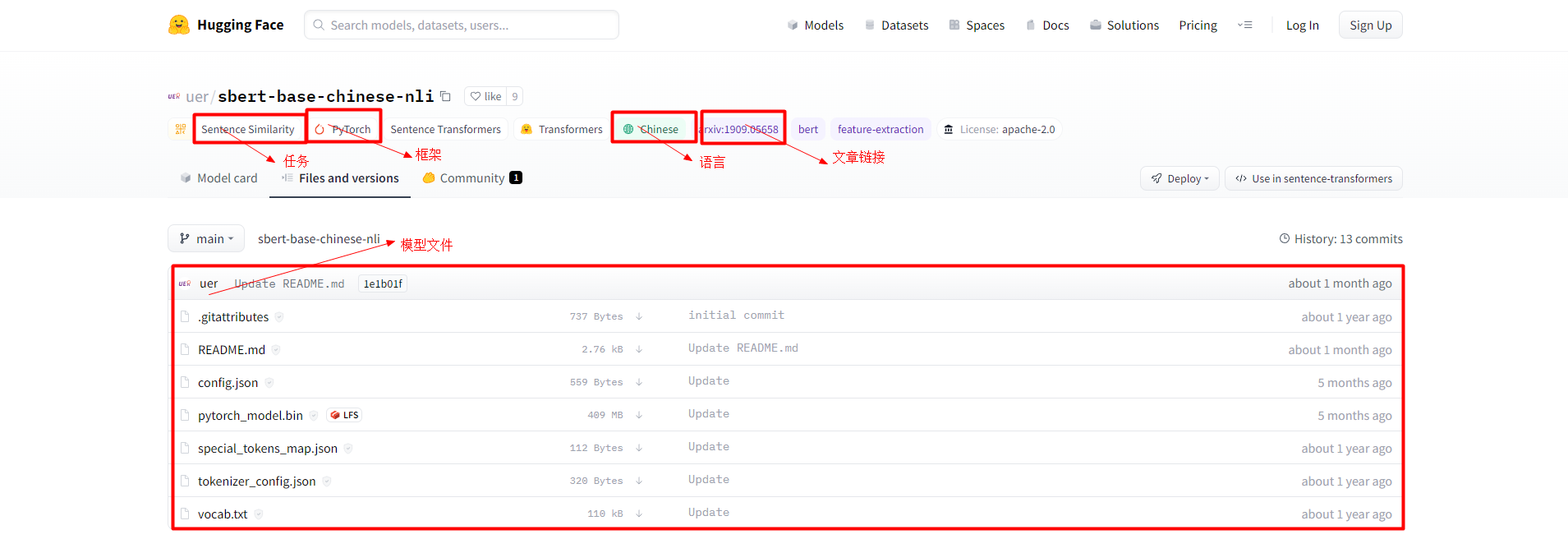
说明:主要就是模型权重文件,各种配置文件,以及词汇表等组成。
五.计算句子相似性实践
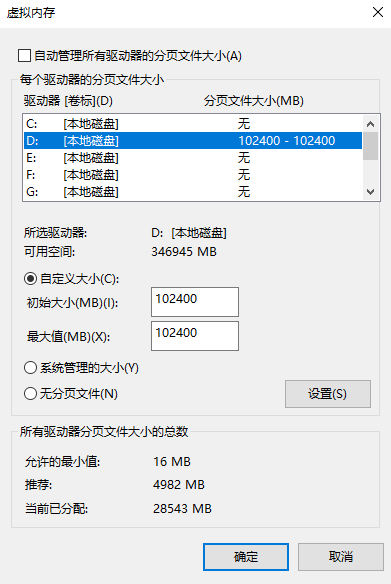
1.可能会遇到的问题
遇到的问题:页面文件太小,无法完成操作。解决方案如下所示:
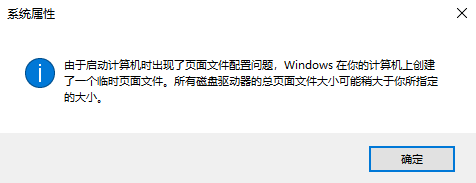
重启系统后会遇到一个系统属性提示的问题,由于不影响使用,暂时先不处理:
2.相关变体
(1)bert-base-uncased:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在小写的英文文本上进行训练而得到。
(2)bert-large-uncased:编码器具有24个隐层,输出1024维张量,16个自注意力头,共340M参数量,在小写的英文文本上进行训练而得到。
(3)bert-base-cased:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在不区分大小写的英文文本上进行训练而得到。
(4)bert-large-cased:编码器具有24个隐层,输出1024维张量,16个自注意力头,共340M参数量,在不区分大小写的英文文本上进行训练而得到。
(5)bert-base-multilingual-cased(新的推荐):编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在104种语言文本上进行训练而得到。
(6)bert-large-multilingual-uncased(原始的不推荐):编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在102种语言文本上进行训练而得到。
(7)bert-base-chinese:编码器具有12个隐层,输出768维张量,12个自注意力头,共110M参数量,在简体和繁体中文文本上进行训练而得到。
说明:uncased是在预处理的时候都变成了小写,而cased是保留大小写。
3.常用操作
print(tokenizer.vocab) # 词汇表
print(tokenizer.tokenize("你好,世界!")) #分词,只能输入字符串
print(tokenizer.convert_tokens_to_ids(['你', '好', ',', '世', '界', '!'])) #将词转换成id
print(tokenizer.convert_ids_to_tokens([872, 1962, 8024, 686, 4518, 8013])) #将id转换成词
结果输出如下所示:
['你', '好', ',', '世', '界', '!']
[872, 1962, 8024, 686, 4518, 8013]
['你', '好', ',', '世', '界', '!']
4.相似性计算
通过如下代码,得到相似性结果为[0.9864919 0.39011386 0.29779416],和在线演示得到的结果是一致的。代码如下:
from transformers import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity
import torch
model = BertModel.from_pretrained("./sbert-base-chinese-nli")
tokenizer = BertTokenizer.from_pretrained("./sbert-base-chinese-nli")
sentences = [
"那个人很开心",
"那个人非常开心",
"那只猫很开心",
"那个人在吃东西"
]
# 初始化字典来存储
tokens = {'input_ids': [], 'attention_mask': []}
for sentence in sentences:
# 编码每个句子并添加到字典
new_tokens = tokenizer.encode_plus(sentence, max_length=15, truncation=True, padding='max_length', return_tensors='pt')
tokens['input_ids'].append(new_tokens['input_ids'][0])
tokens['attention_mask'].append(new_tokens['attention_mask'][0])
# 将张量列表重新格式化为一个张量
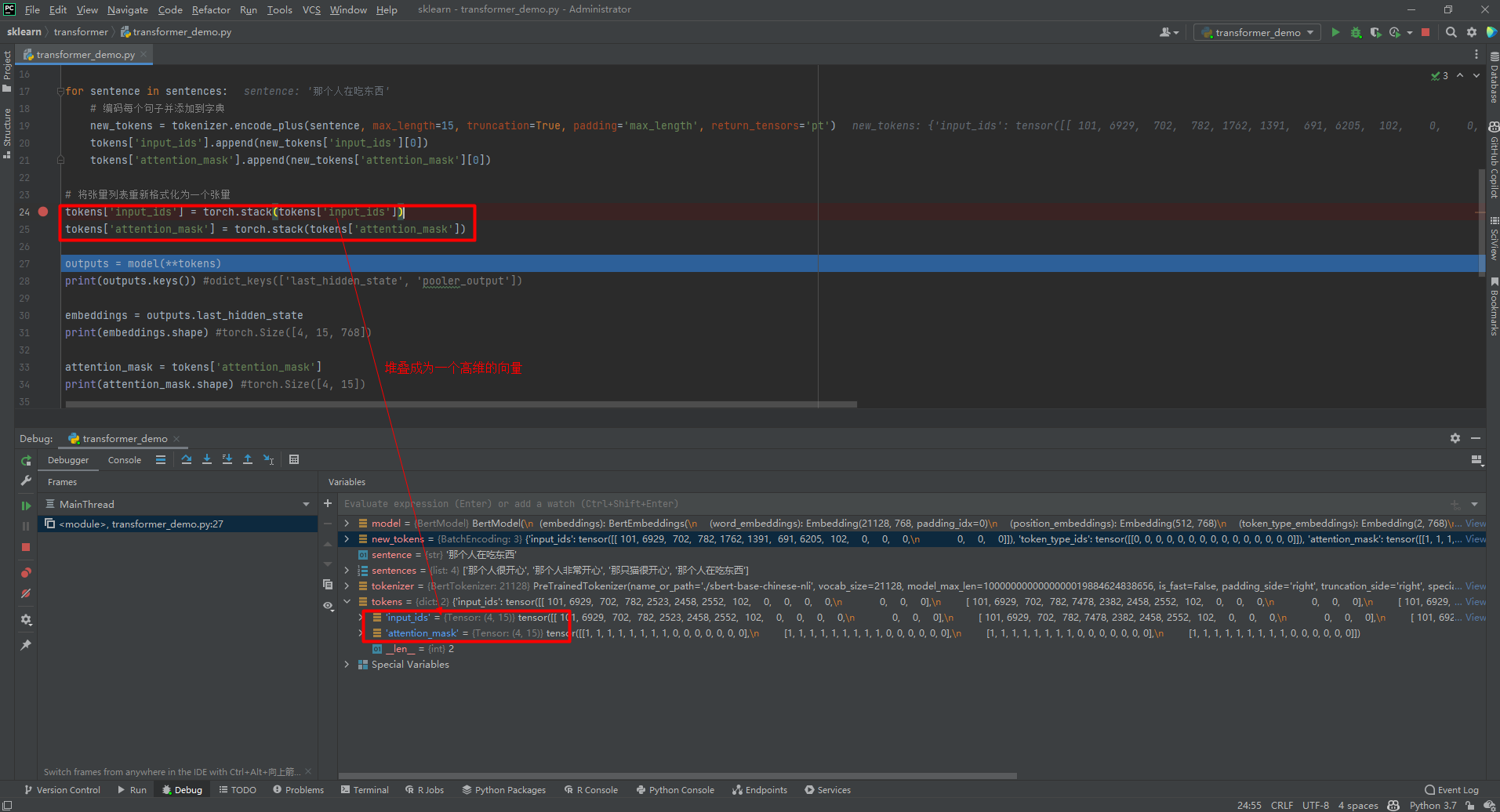
tokens['input_ids'] = torch.stack(tokens['input_ids'])
tokens['attention_mask'] = torch.stack(tokens['attention_mask'])
outputs = model(**tokens)
# print(outputs.keys()) #odict_keys(['last_hidden_state', 'pooler_output'])
embeddings = outputs.last_hidden_state
# print(embeddings.shape) #torch.Size([4, 15, 768])
attention_mask = tokens['attention_mask']
# print(attention_mask.shape) #torch.Size([4, 15])
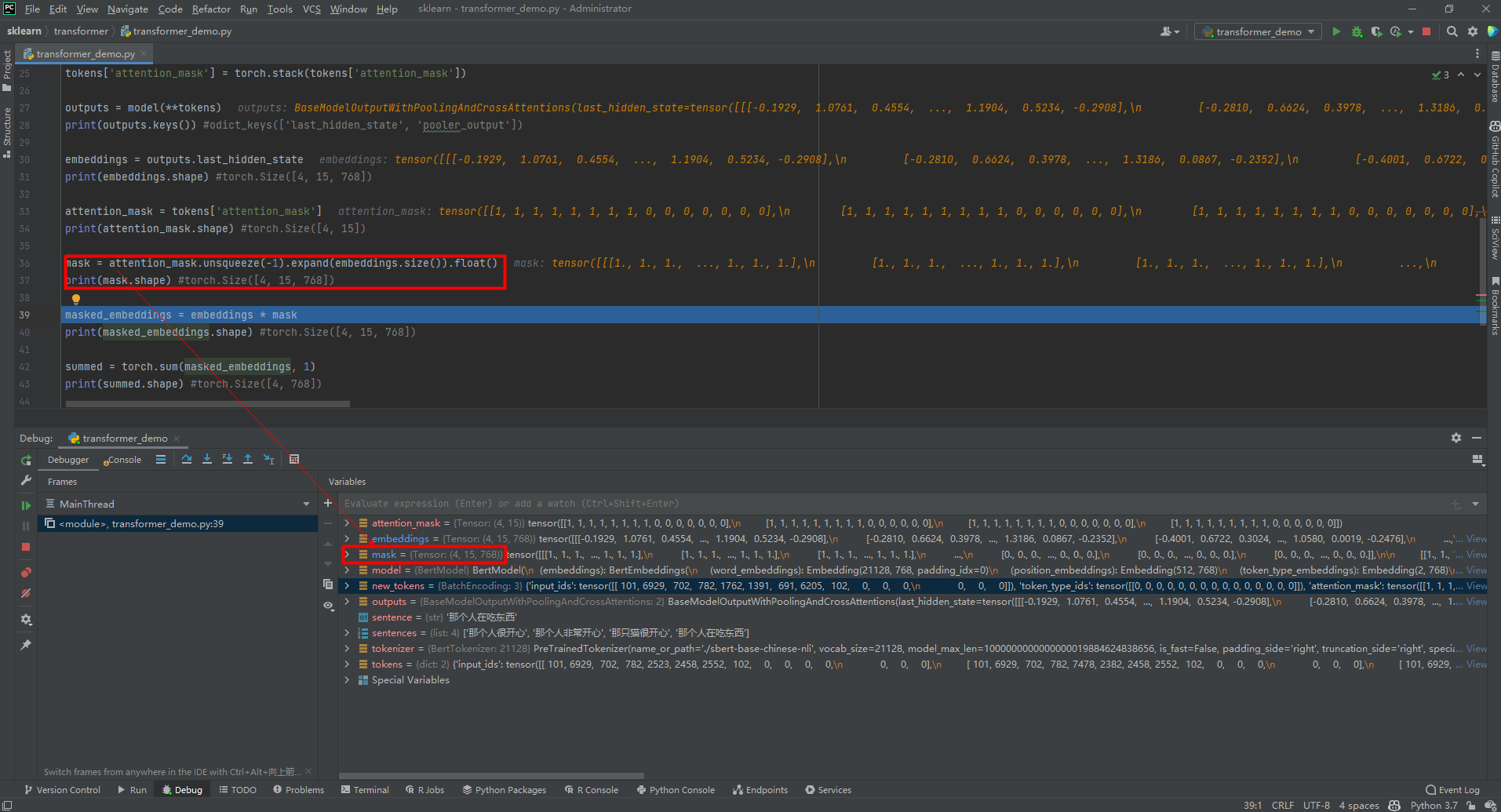
mask = attention_mask.unsqueeze(-1).expand(embeddings.size()).float()
# print(mask.shape) #torch.Size([4, 15, 768])
masked_embeddings = embeddings * mask
# print(masked_embeddings.shape) #torch.Size([4, 15, 768])
summed = torch.sum(masked_embeddings, 1)
# print(summed.shape) #torch.Size([4, 768])
summed_mask = torch.clamp(mask.sum(1), min=1e-9)
# print(summed_mask.shape) #torch.Size([4, 768])
mean_pooled = summed / summed_mask
# print(mean_pooled.shape) #torch.Size([4, 768])
mean_pooled = mean_pooled.detach().numpy()
result = cosine_similarity([mean_pooled[0]], mean_pooled[1:])
# print(result) #[[0.9864919 0.39011386 0.29779416]]
输出结果如下所示:
odict_keys(['last_hidden_state', 'pooler_output'])
torch.Size([4, 15, 768])
torch.Size([4, 15])
torch.Size([4, 15, 768])
torch.Size([4, 15, 768])
torch.Size([4, 768])
torch.Size([4, 768])
torch.Size([4, 768])
[[0.9864919 0.39011386 0.29779416]]
5.部分代码理解
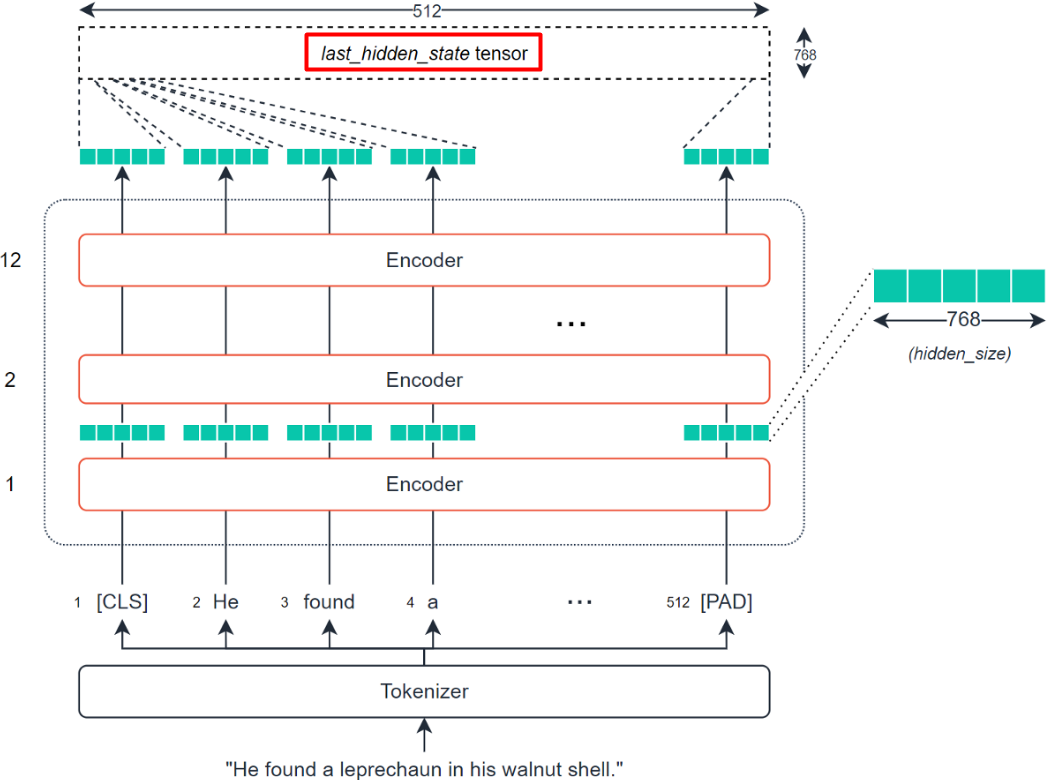
理解上述代码最重要的就是理解从last_hidden_state到mean_pooled的计算过程,即通过BERT模型提取输入句子的tensor,转换为可计算句子相似性的vector的过程。BERT模型提取输入句子的tensor得到last_hidden_state的过程如下:
(1)torch.stack()函数
(2)unsqueeze()和expand()函数
unsqueeze()表示扩充一个维度,expand()扩充为指定的维度,比如扩充为[4, 15, 768]。如下:
(3)torch.clamp()函数
| min, if x_i < min
y_i = | x_i, if min <= x_i <= max
| max, if x_i > max
参考文献:
[1]Huggingface Transformer教程:http://fancyerii.github.io/2021/05/11/huggingface-transformers-1/
[2]huggingface transformers的trainer使用指南:https://zhuanlan.zhihu.com/p/358525654
[3]Hugging Face博客:https://huggingface.co/blog
[4]Hugging Face GitHub:https://github.com/huggingface
[5]How to generate text: using different decoding methods for language generation with Transformers:https://huggingface.co/blog/how-to-generate
[6]深度学习理论与实战:提高篇:http://fancyerii.github.io/2019/03/14/dl-book/
[7]Pytorch-Transformers:https://huggingface.co/transformers/v1.2.0/
[8]huggingface/transformers:https://github.com/huggingface/transformers
[9]dbiir/UER-py:https://github.com/dbiir/UER-py/
[10]UER: An Open-Source Toolkit for Pre-training Models:https://arxiv.org/abs/1909.05658
[11]liuhuanyong/ChineseTextualInference:https://github.com/liuhuanyong/ChineseTextualInference/
[12]HuggingFace Transformers最新版本源码解读(一):https://zhuanlan.zhihu.com/p/360988428
[13]HuggingFace Transformers最新版本源码解读(二):https://zhuanlan.zhihu.com/p/363014957
[14]如何评价微软提出的BEIT-3:通过多路Transformer实现多模态统一建模:https://www.zhihu.com/question/549621097/answer/2641895293
[15]google-research/bert:https://github.com/google-research/bert
[16]教育类数据集汇总:https://aistudio.baidu.com/aistudio/projectdetail/3435637
[17]UKPLab/sentence-transformers:https://github.com/UKPLab/sentence-transformers
[18]SentenceTransformers Documentation:https://www.sbert.net/index.html
[19]Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks:https://arxiv.org/abs/1908.10084
[20]Sentence-BERT: 一种能快速计算句子相似度的孪生网络:https://www.cnblogs.com/gczr/p/12874409.html
[21]jamescalam/transformers:https://github.com/jamescalam/transformers/blob/main/course/similarity/03_calculating_similarity.ipynb
吾爱DotNet
 专注于.NET领域的技术分享
专注于.NET领域的技术分享
人工智能干货推荐
 专注于人工智能领域的技术分享
专注于人工智能领域的技术分享

 浙公网安备 33010602011771号
浙公网安备 33010602011771号