MySQL命令(SQL语句)
1.mysql登陆
完整登陆命令:
mysql -u root -p xxxxx -h 127.0.0.1 -P 23306
语法:mysql -u 用户名 -p 密码 -h mysql服务器的IP地址 -P 使用的端口号
非完整登陆命令:
mysql -u root -p 回车(回车后再输入密码)
mysql -u root -p xxxxx -h 127.0.0.1 回车(回车后再输入密码)
2.SQL语句:
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE
子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件>
2 .数据操纵语言DML
数据操纵语言DML主要有三种形式:
1) 插入:INSERT
2) 更新:UPDATE
3) 删除:DELETE
3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象-----表、视图、
索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER
| | | | |
表 视图 索引 同义词 簇
DDL操作是隐性提交的!不能rollback
4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制
数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1) GRANT:授权。
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
回滚---ROLLBACK
回滚命令使数据库状态回到上次最后提交的状态。其格式为:
SQL>ROLLBACK;
3) COMMIT [WORK]:提交。
在数据库的插入、删除和修改操作时,只有当事务在提交到数据
库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看
到所做的事情,别人只有在最后提交完成后才可以看到。
提交数据有三种类型:显式提交、隐式提交及自动提交。下面分
别说明这三种类型。
(1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL>COMMIT;
(2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,
EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。
(3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,
系统将自动进行提交,这就是自动提交。其格式为:
SQL>SET AUTOCOMMIT ON;
注意:
①进入mysql后所有命令必须以分号(;)结尾
②如果你要查一些数据时显示乱,屏幕宽度不够展不开,你就在命令结尾加\G最后不要加分号,这样显示就会清晰了.
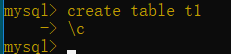
③如果输错命令想退出来不执行,就输入\c回车即可,如下图
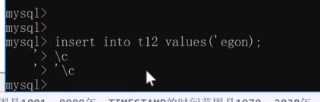
④如果少写一个引号,直接\c是退不出来的,需要先写'再写\c就行了如下图
3.查看本数据库版本与编码集
进入数据库后输入\s

4.数据库的增删改查
数据库的增删改查说白了其实就是文件夹的增删改查
增
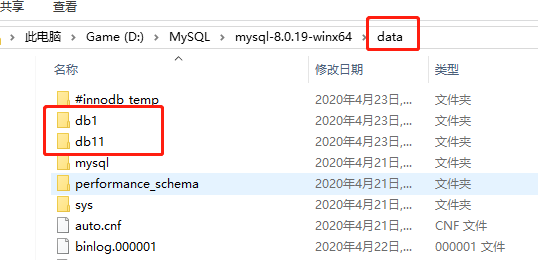
create database db1 charset utf8;(这里在创建库时指定了编码集)
create database db11; (不指定编码集也可)
此时就在你安装数据库的文件夹下的data文件中新增了两个文件夹(db1和db11)
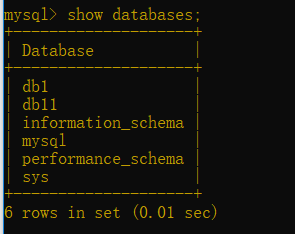
查看所有数据库时,有数据库安装时自带的数据库也一并显示出来了
查
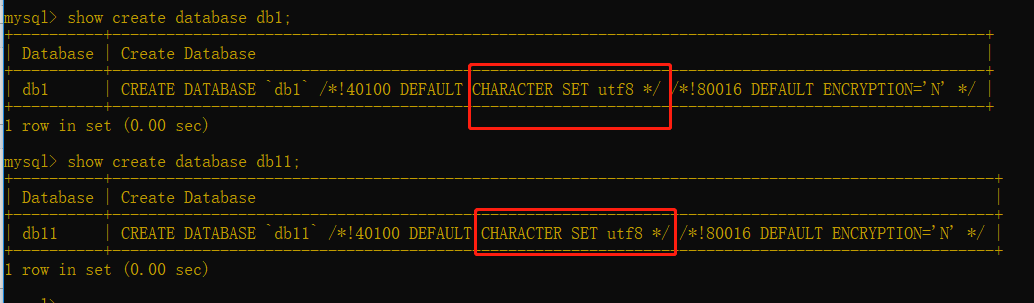
show create database db1;(查看刚建的数据库的配置)
show databases;(查看所有数据库--库名)
查看当前所在的数据库:select database();
由于你my.ini文件中配置制定了编码集,所以不指定编码集的数据库db11也是utf8.
改
alter database db1 charset gbk;(将数据库db1的编码集改为gbk了)
切换数据库
use +数据库名+;
删
drop database db1;(删除数据库db1)
5.数据库中表的增删改查
表的增删改查可以看做是对文件的增删改查
增加表时你需要先进入一个数据库(use +数据库名+;),增加表时就在你进入的数据库中新增表
增
create table t1(id int,name char); 新增表t1,表中有两个字段id和name,id是整形,name是字符串
查
show create table t1;(查看该表具体信息)
如果没进入数据库你想直接查就在对应的表名前加数据库名.
show create table db1.t1;
show tables;查看当前数据库下所有表名
desc t1;查看某表中所有字段以及字段的属性(desc是describe的缩写)
select id from n; 查询表n中id字段的所有内容
select * from n;查询表n中所有内容
改
alter table t1 modify name char(6);(将name字段属性改为字符串,宽度改为6,默认宽度是1)modify是固定写法
alter table t1 change name NAME char(7);(修改字段名name改为NAME,并且宽度改为7)change是固定写法新的名字NAME后面必须接新字段的属性,否则报错,你可以是新的属性也可以是原来的属性.
修改表名:
alter table ttt rename xxx;将ttt表名改为xxx
增加字段:
alter table xxx add n char(10) ; 在xxx表中增加一个n字段,数据类型为char长度为10
alter table xxx add n char(10) first; 将n字段添加到第一个字段位置
alter table xxx add n char(10) after id; 将n字段添加到id字段位置的后面
删
drop table t1;删除表t1
删除字段:
alter table xxx drop n ;删除xxx表中n字段
复制表格(可以在同数据库但是不要重名,也可以在不同数据库可以重名,)
①既复制表结构,又要数据:
create table t1 select host,user from mysql.user; (就是把你查到的某个表的数据select...,直接在创建表格时直接写在后面就行了,写在了表名后面)
create table t1 select * from db1.ttt;
②只要表结构,不要数据:
法一:就是在后面加个不成立的条件,让他查不到对应的数据就行了,查到的内容为空就只剩表结构了
create table t1 select host,user from mysql.user where 1>2;
法二:like
create table t5 like t2;这样就把t2的表结构复制过来创建了t5
6.行记录(表中内容)的增删改查
增
insert into t1(id,name) values(1,'egon1'),(2,'egon2'),(3,'egon3');(新增了3条行记录,id为1,name为egon1...)into可以省略
insert into t1 values(1,'egon1'),(2,'egon2'),(3,'egon3');不写字段,默认就按照所有字段来插入
查
select id,name from db1.ttt;(查看ti表中id和name两个字段)这里吧数据库db1也加上了,其实你在db1数据库下就不用了写db1,直接写表名字即可
select * from db1.ttt;查询t1表下所有字段

查询某个字段中数据的长度
select char_length(name) from t4; 查询t4表中name字段的内容的长度.
改
update db1.t1 set name='wwe';将t1表中所有name字段全部写成wwe
update db1.t1 set name='ALEX' where id=2;将id等于2的name字段改成ALEX
删
delete from t1;(将所有记录全部删,表变成空表)这个不会清空自增长的计数,delete一般都会与where连用,来固定删除某行记录.
truncate t1 ;会清空自增长的计数,再插入行记录时id会从1开始
delete from t1 where id=2;(只删除id=2的记录)
7.存储引擎
存储引擎就是表的类型
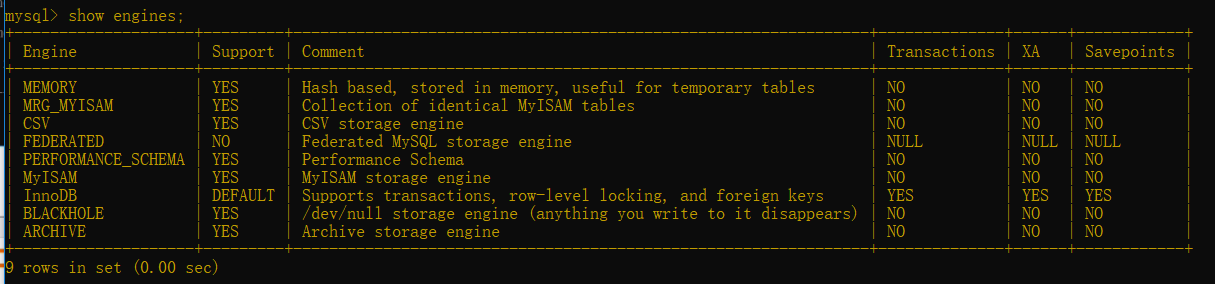
查看支持的所有存储引擎
show engines;
或show engines\G 查的比较详细(有\G时不加分号结尾)
创建表时指定存储引擎:
create table t1(id int)engine=innodb;不指定默认就是innodb
8.单表查询:
单表查询条件顺序:
书写顺序如下:
select distinct 字段1,字段2,字段3 from 库.表
①where 条件
②group by 分组条件
③having 过滤
④order by 排序字段
⑤limit n;
distinct是去重
运行顺序:
①from 库.表(找不到表的话就不运行了)
②where
③group by
④having
⑤distinct 字段1,字段2,字段3 (如果写了distinct就先去重,再order by),这里运行的是select后面的内容,就是你要显示的字段内容
⑥order by
⑦limit in
执行顺序写成函数形式:
def from(db,table): f=open(r'%s\%s' %(db,table)) return f def where(condition,f): for line in f: if condition: yield line def group(lines): pass def having(group_res): pass def distinct(having_res): pass def order(distinct_res): pass def limit(order_res) pass #开始执行 def select(): f=from('db1','t1') lines=where('id>3',f) group_res=group(lines) having_res=having(group_res) distinct_res=distinct(having_res) order_res=order(distinct_res) res=limit(order_res) print(res) return res
①where(条件):会把整个表格全部查一遍
注:where用不了聚合函数,因为他是在分组(group by)之前运行
这两句是一个意思:(between,in)
①
select name,salary from employee where salary >= 20000 and salary <= 30000;
select name,salary from employee where salary between 20000 and 30000;
②
select name,salary from employee where salary < 20000 or salary > 30000;
select name,salary from employee where salary not between 20000 and 30000;
③
select * from employee where age = 73 or age = 81 or age = 28;
select * from employee where age in (73,81,28);
select * from employee where post_comment is Null; 某字段为空,不能写成=' '
select * from employee where post_comment is not Null; 某字段不为空
like模糊匹配:
select * from employee where name like "jin%"; 以jin开头的都算上
select * from employee where name like "jin___";一个下划线代表一个字符,不管你写的是啥,他只匹配字符数量够了就行,例如:jinxxx可以,但是jinqwer就不行,多了一个字符.
②group by(分组):
在group by之后都可用聚合函数
先设置:set global sql_mode="ONLY_FULL_GROUP_BY"; 设置严格模式,然后exit退出再进
注意:
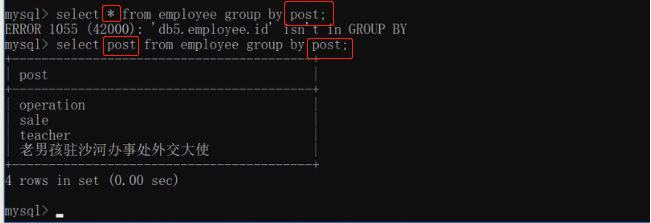
①分组之后,只能取分组的字段,以及每个组聚合结果,就是设置之前你分组时候可以用*获取内容,设置后,只能取你分组的字段或者聚合的字段,别的字段拿不到,写了就报错.
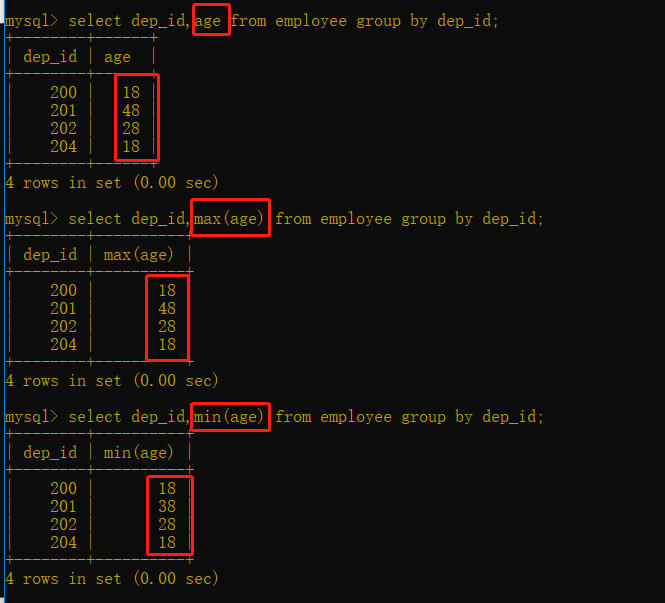
②分组之后,你可以取其他字段,但是这个字段一定是分组后该组最上面的一行数据,如果你要取,最好用聚合函数来取,max,min,avg等
③不要用unique的字段来分组,因为全是不一样的,分不分没区别
设置之前:

设置之后
聚合函数:
max 最大值
min 最小值
avg 求平均数
sum 求总和
count 求数量(多少行记录)
select post,count(id) as emp_count from employee group by post;
select post,max(salary) as emp_count from employee group by post;
select post,min(salary) as emp_count from employee group by post;
select post,avg(salary) as emp_count from employee group by post;
select post,sum(age) as emp_count from employee group by post;
没有group by则默认整体算作一组
select max(salary) from employee;
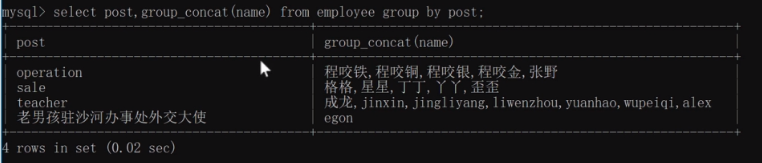
拼接group_concat:
#group_concat
select post,group_concat(name) from employee group by post;将name字段内容按照post字段进行分类,并写在post分类之后
定义显示格式:(拼接字符串)用concat
select concat ('姓名:' ,name, ' 性别:',sex) as info ,concat('年薪:',salary*12) as annual_salary from employee;
显示如下:

另一种:
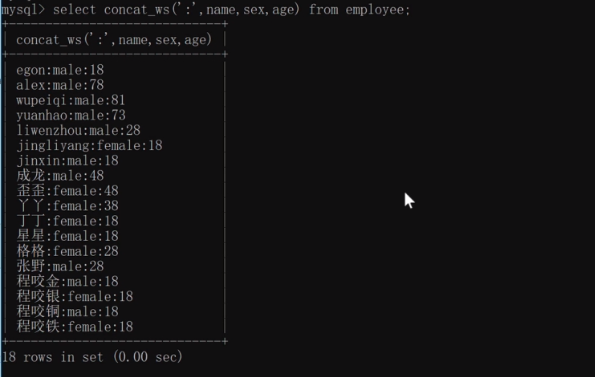
select concat(name,':',sex,':'age) from employee;

换一种写法:用concat_ws他会在两个字段中间都加入相同的内容
select concat_ws(':',name,sex,age) from employee;
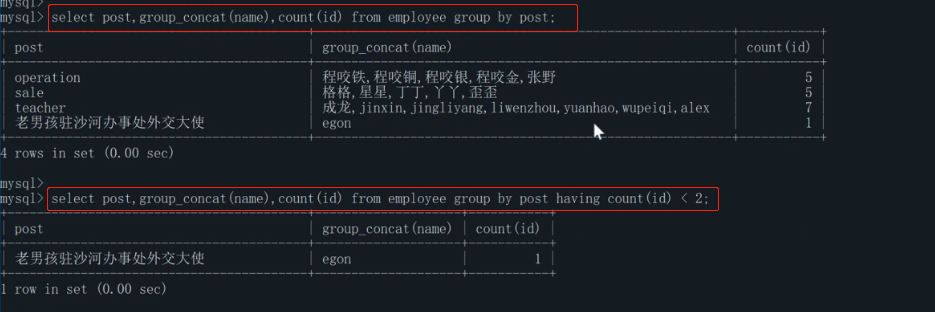
③having(过滤):
查询各岗位包含员工个数小于2的岗位名、岗位内包含用功名字、个数
过滤后:
select post,group_concat(name),count(id) from employee group by post having count(id) < 2;
过滤前:
select post,group_concat(name),count(id) from employee group by post;
④order by(排序):
默认是升序(asc)
降序:desc
select * from employee order by age asc; #升序
select * from employee order by age desc; #降序
select * from employee order by age asc,id desc; #先按照age升序排,如果age相同则按照id降序排
⑤limit(限制显示条数):
用法一(显示条数):
select * from employee limit 3;只看前三条
select * from employee order by salary desc limit 1;我要看薪资最高的那个人,先倒序按照薪资排序,然后只取第一条

用法二(分页,分段取):
但是实际工作不会仅仅用limit来做分页,这样取每次还都是从第一条开始数,只是取的时候按照对应的数字去取,很麻烦.
select * from employee limit 0,5;第一行开始取,一共取5行记录,取得id是从1-5,你如果写1,5,那取的id就是2-6
select * from employee limit 5,5;
select * from employee limit 10,5;
select * from employee limit 15,5;
注意:
limit后如果有两个数字并且用逗号隔开,第一个数字表示从第几行数据开始,但是不取这一行,从他下一行开始取,第二个数字表示向下取几行.
9.简单查询:
select name,salary*12 from employee; 在查询时可以进行运算,一个月工资,乘12就变成了年薪
select name,salary*12 as nianxin from employee; 在显示时就会将salary的字段名改为nianxin
10.正则匹配:
select * from employee where name like 'jin%'; (like是模糊匹配)
select * from employee where name regexp '^jin'; (regexp启用正则,^表示以xxx为开头的)
select * from employee where name regexp '^jin.*(g|n)$'; (以jin开头,并且以g或者是n结尾的,中间字符不限制的)
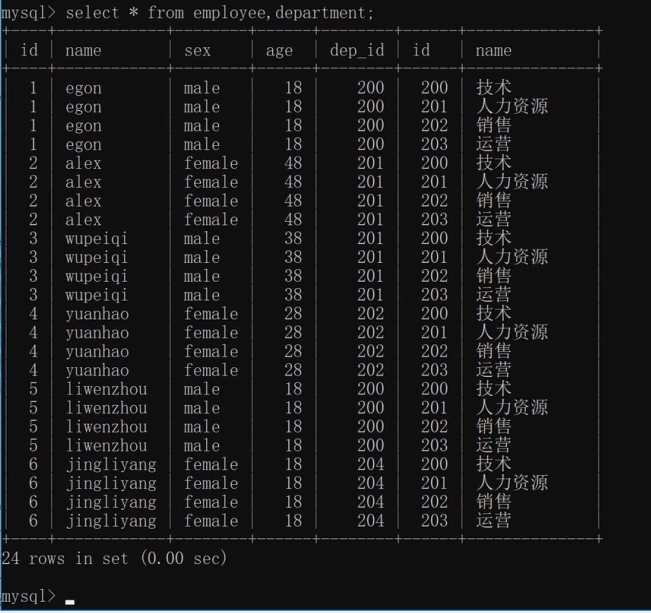
11.连表查询:
from后直接写俩表名用逗号隔开,会出现很多重复字段,笛卡尔积,第一张表所有行记录都会跟第二张表每一条行记录做对应关系

1.内连接:只取两张表的共同部分
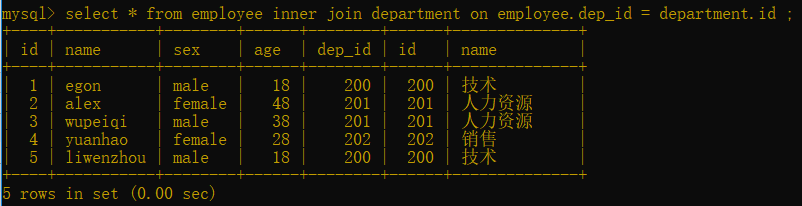
语法: select * from 表一 inner join 表二 on 表一.字段 = 表二.字段;
select * from employee inner join department on employee.dep_id = department.id ;
2.左连接:在内连接的基础上保留左表的记录
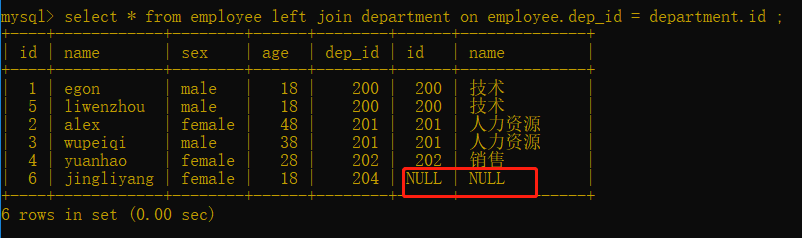
语法: select * from 表一 left join 表二 on 表一.字段 = 表二.字段;
select * from employee left join department on employee.dep_id = department.id ;
以左表为主,如果右表中没有与之对应的内容就写NULL
3.右连接:在内连接的基础上保留右表的记录(与左连接差不多)
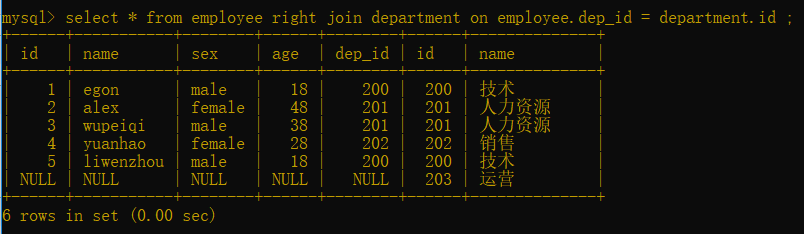
语法: select * from 表一 right join 表二 on 表一.字段 = 表二.字段;
select * from employee right join department on employee.dep_id = department.id ;
以右表为主,如果左表中没有与之对应的内容就写NULL
4.全外连接:在内连接的基础上保留左右两表没有对应关系的记录
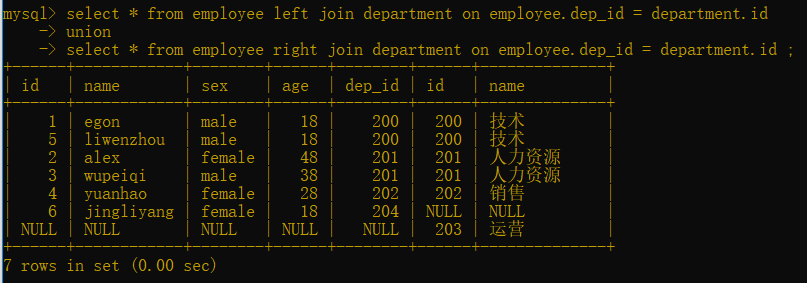
错误写法:mysql中没有full
select * from employee full join department on employee.dep_id = department.id ;
正确写法:用union连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id ;
查一下:
平均年龄大于30岁的部门名和平均年龄
select department.name as bumen ,avg(age) as pingjunnianling from employee inner join department on employee.dep_id = department.id
group by department.name
having avg(age)>30;

注:select语句关键字定义顺序
SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
select语句关键字执行顺序:
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
12.子查询:
1:子查询是将一个查询语句嵌套在另一个查询语句中。 2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 4:还可以包含比较运算符:= 、 !=、> 、<等
①带IN关键字的子查询
#查询平均年龄在25岁以上的部门名 select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25); #查看技术部员工姓名 select name from employee where dep_id in (select id from department where name='技术'); #查看不足1人的部门名(子查询得到的是有人的部门id) select name from department where id not in (select distinct dep_id from employee);
②带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<> #查询大于所有人平均年龄的员工名与年龄 mysql> select name,age from emp where age > (select avg(age) from emp); +---------+------+ | name | age | +---------+------+ | alex | 48 | | wupeiqi | 38 | +---------+------+ rows in set (0.00 sec) #查询大于部门内平均年龄的员工名、年龄 select t1.name,t1.age from emp t1 inner join (select dep_id,avg(age) avg_age from emp group by dep_id) t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age;
③带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。
而是返回一个真假值。True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
#department表中存在dept_id=203,Ture mysql> select * from employee -> where exists -> (select id from department where id=200); +----+------------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------------+--------+------+--------+ | 1 | egon | male | 18 | 200 | | 2 | alex | female | 48 | 201 | | 3 | wupeiqi | male | 38 | 201 | | 4 | yuanhao | female | 28 | 202 | | 5 | liwenzhou | male | 18 | 200 | | 6 | jingliyang | female | 18 | 204 | +----+------------+--------+------+--------+ #department表中存在dept_id=205,False mysql> select * from employee -> where exists -> (select id from department where id=204); Empty set (0.00 sec)
特殊用法(as):
select * from
(select id,name from employee) as t1;
这里是将查询到的内容赋值给t1当做一个表格,再从这张表查询相关内容
新建个远程账号,并且赋予权限:

13.存储过程
利用存储过程插入多条记录.
存储过程(类似函数) 1.准备表 create table s1( id int, name varchar(20), gender char(6), email varchar(50) ); 2.创建存储过程,插入多条记录 delimiter $$ #声明存储过程结束符号为$$ create procedure auto_insert1() #创建存储过程,procedure为关键字不能变,auto_insert1为自定义的存储过程的名字 BEGIN #开始,关键字 declare i int default 1; #声明一个数字变量i默认值为1 while(i<=1000)do insert into s1 values(i,'egon','male',concat('egon',i,'@163.com')); set i=i+1; end while; END$$ #结束关键字加自己定义的结束符号来结束存储过程 delimiter ; #重新声明 ; 为结束符号,将自己定义的$$取消 3.查看存储过程 show create procedure auto_insert1\G 4.调用存储过程 call auto_insert1(); #在mysql中调用 cursor.callproc('auto_insert1') #在python的pymysql模块中使用 5.查看列表的内容 select * from s1;
