
Flink实战(1) - Apache Flink安装和示例程序的执行
在Windows上安装
- 从官方网站下载需要的二进制包
- 比如我下载的是flink-1.2.0-bin-hadoop2-scala_2.10.tgz,解压后进入bin目录
- 可以执行bat文件,也可以使用cygwin执行sh文件
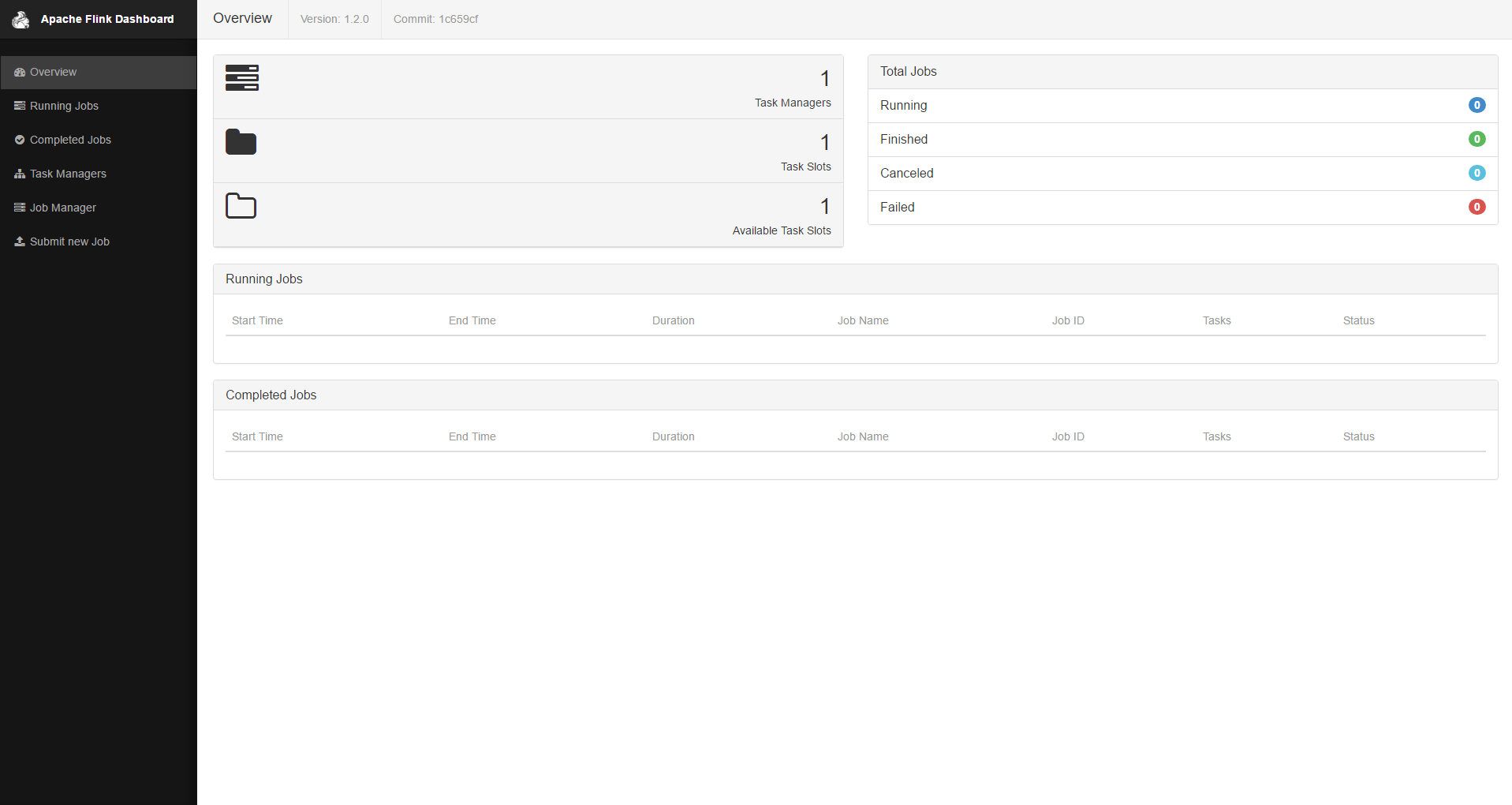
- 然后可以在浏览器中输入http://localhost:8081打开管理页面
创建和执行wordcount示例程序
使用idea新建一个Maven工程
我这里使用Intellij IDEA进行开发
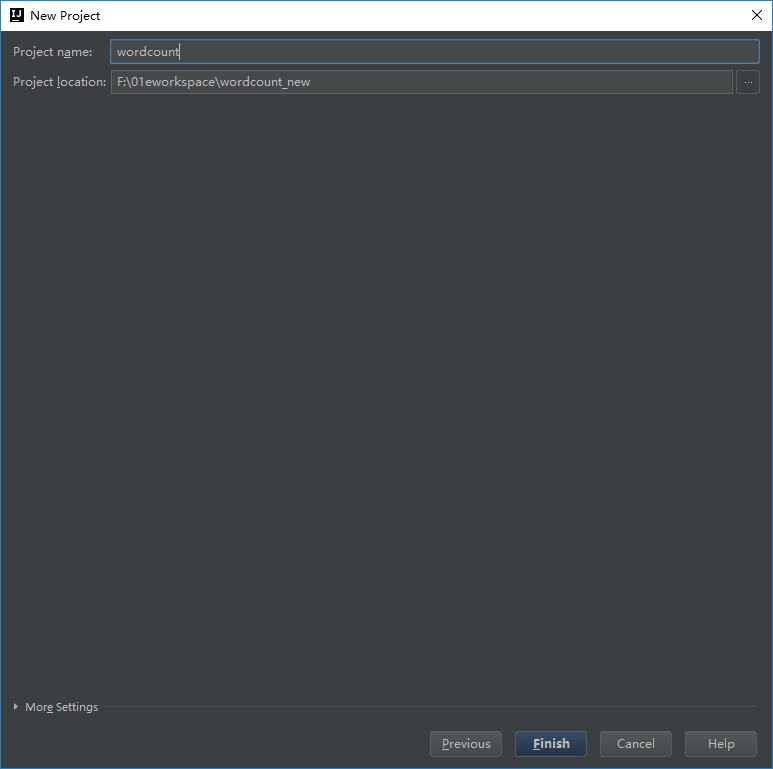
- 使用"new project"创建一个maven工程
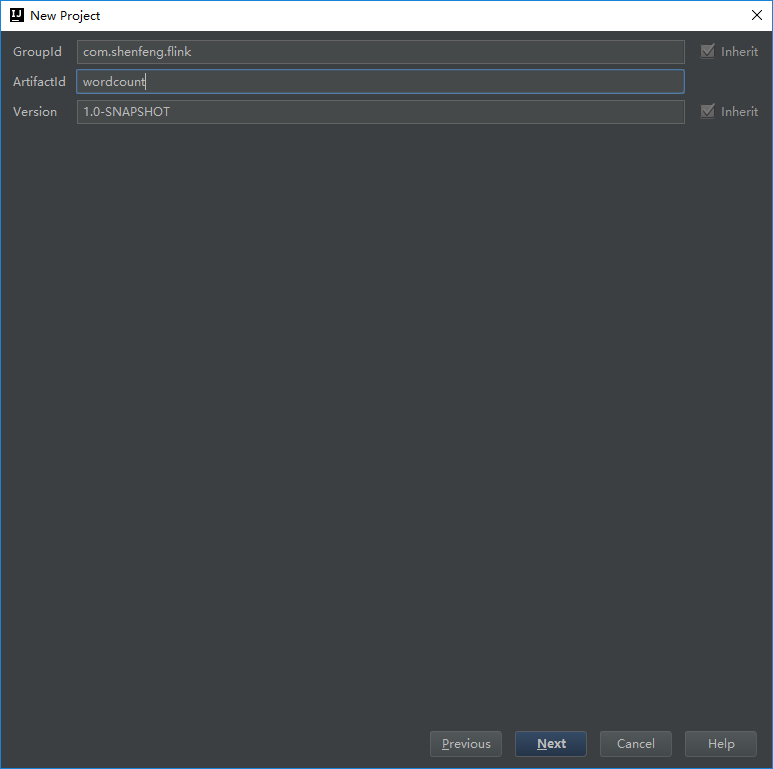
- 指定示例程序的groupId和artifactId
- 指定示例程序的工程名和路径
-
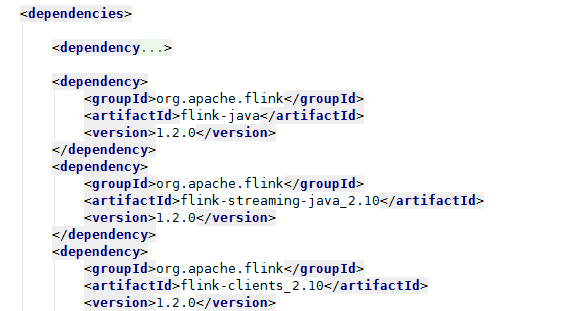
在pom.xml添加依赖关系,更新后IDEA会自动下载jar包至本地仓库 (由于markdown解析问题,换成图片)
-
创建一个wordcountexample类文件
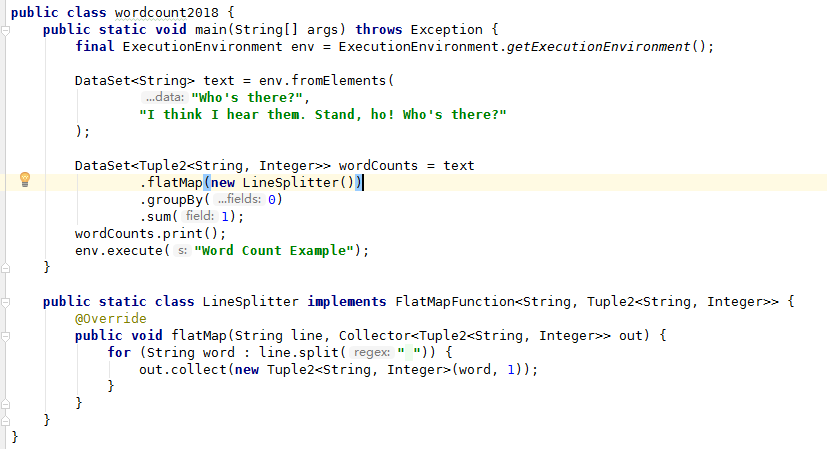
示例程序解读
- 基本同标准的Java程序类似,并且含有一个main()方法。每个程序基本由以下5个部分组成:
- 获取一个
ExecutionEnvironment - 载入或者创建初始输入数据
- 指定数据变换的方式
- 制定计算后的数据输出位置
- 程序执行
- 对照上面的
WordCountExample:
-
获取一个
ExecutionEnvironment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); -
初始数据:
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
- 变换方式:
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
- 输出方式
wordCounts.print();
- 程序执行
env.execute("Word Count Example");
本地执行
- 直接使用菜单栏上的
Build进行编译,使用Run执行程序 - 若直接按照样例执行,可能出现以下错误:
Exception in thread "main" java.lang.RuntimeException: No new data sinks have been defined since the last execution. The last execution refers to the latest call to 'execute()', 'count()', 'collect()', or 'print()'.
- 参照此文,原因是print()方法自动会调用execute()方法,造成错误,所以注释掉
env.execute()即可
上传flink后台运行
-
首先build jar包,注意将META-INF目录放在src/main/java/resource目录下,否则可能出现找不到main class的问题
-
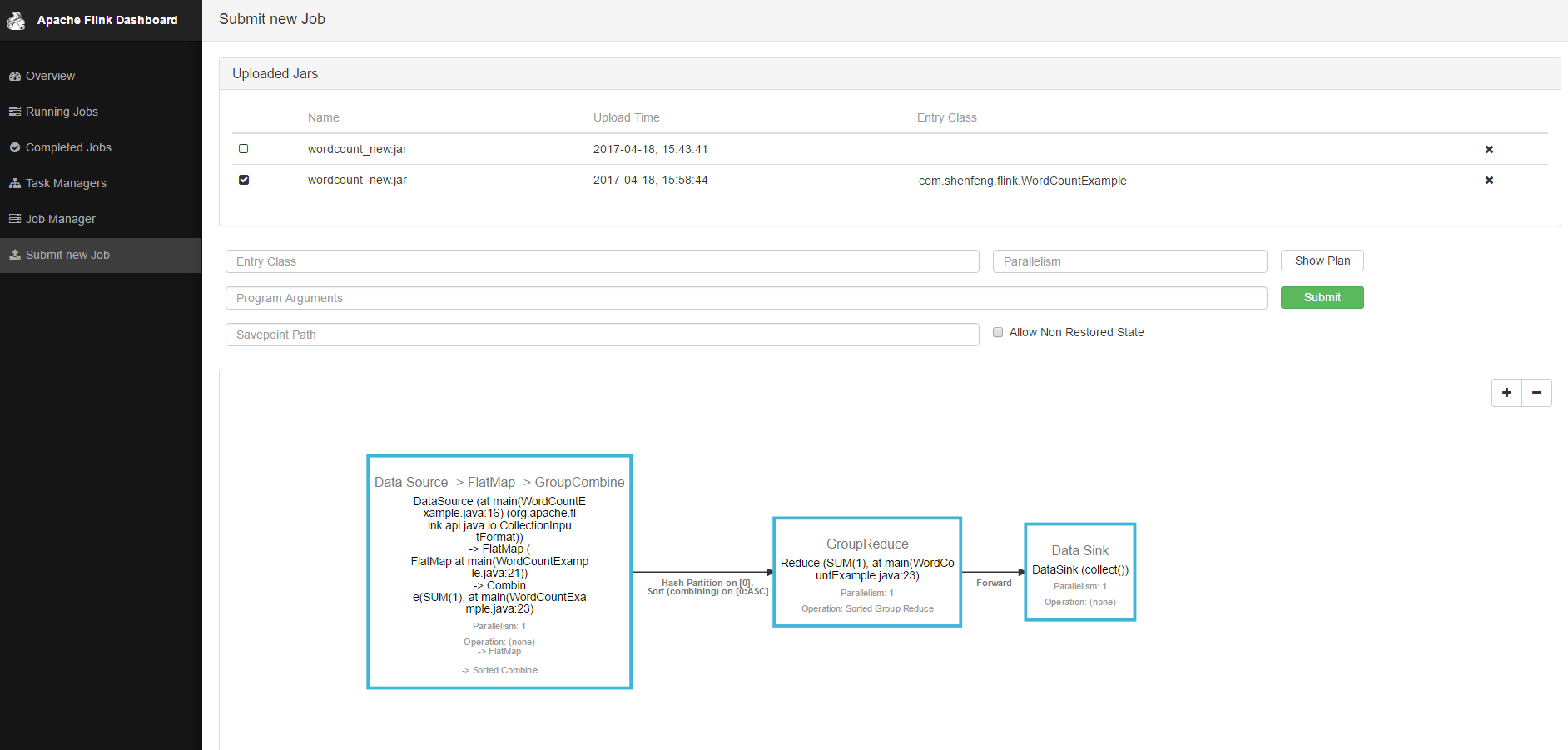
将jar包上传至flink后台
-
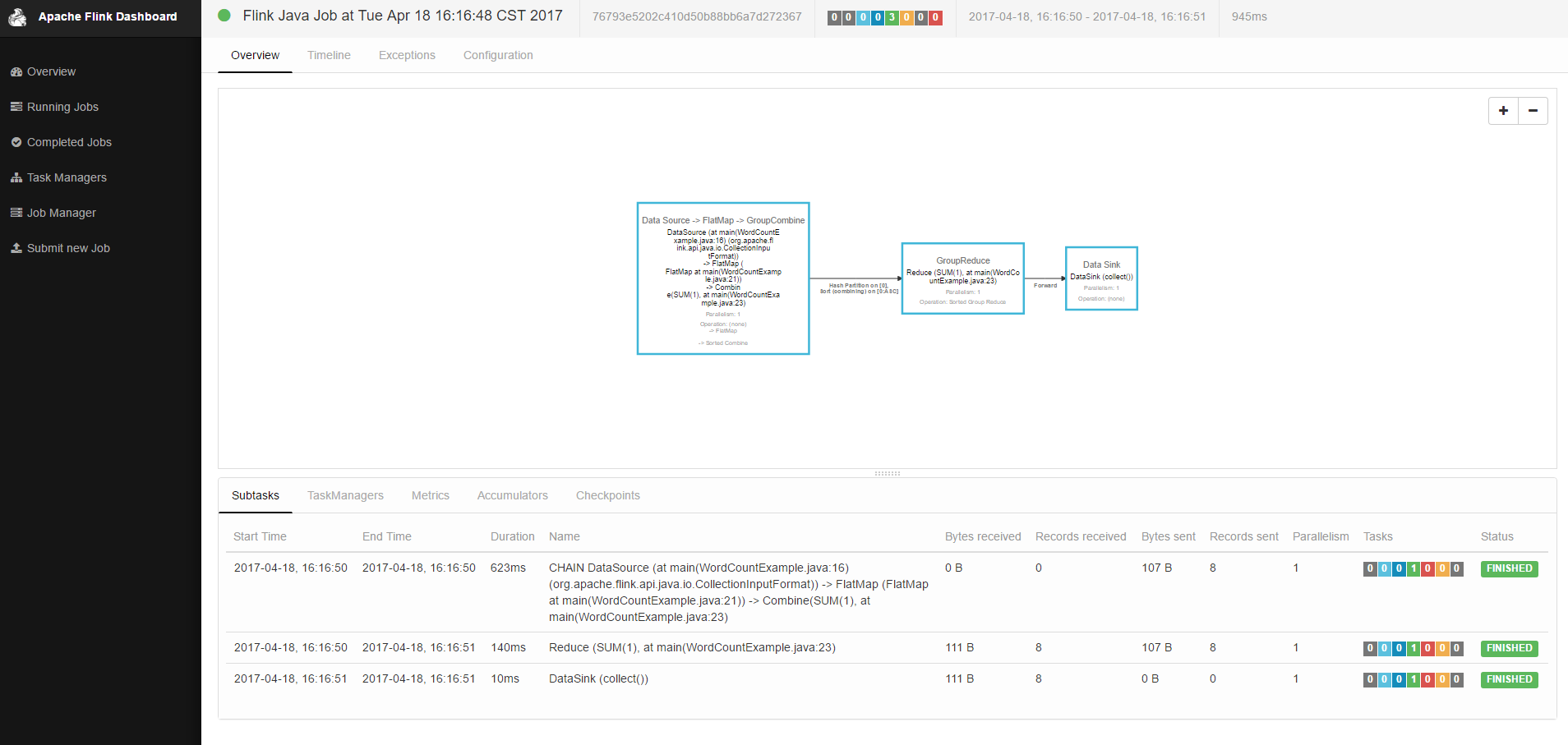
点击提交之后,可以将任务提交给后台执行,执行完成后可以看到执行统计信息。
--EOF--


 浙公网安备 33010602011771号
浙公网安备 33010602011771号