数据仓库知识点梳理(2)
接着上一篇文章介绍了数据仓库的发展历史和基本概念,本文将着重介绍数据仓库的主流建模方式——维度建模。
01 业务分析与维度建模
常见的业务分析过程,包含对分析对象的定性分析和定量分析。维度建模在确定一个主题后,会将数据存储在事实表和维度表。对比下这两个分类,非常巧合的,在维度模型里面维度表存放的是分析主题的属性,对应于定性分析;而事实表中存放的是属性组合下的数量度量,对应于定量分析。
以分析销售主题为例,对于销售可量化的数据如销售金额、销售数量等可以量化的数据是存在事情表中。对销售有影响的属性如,地区、产品、时间等。
同时,每个主要的影响因子维度下,存在多种不同的粒度,比如地区可以按照省、市、区进行划分;时间可以按照季度、月度甚至节假日等进行划分。在分析业务时,可以使用鱼骨图将这些因子罗列起来。下图为使用鱼骨图做的销售主题的归因或者相关分析。
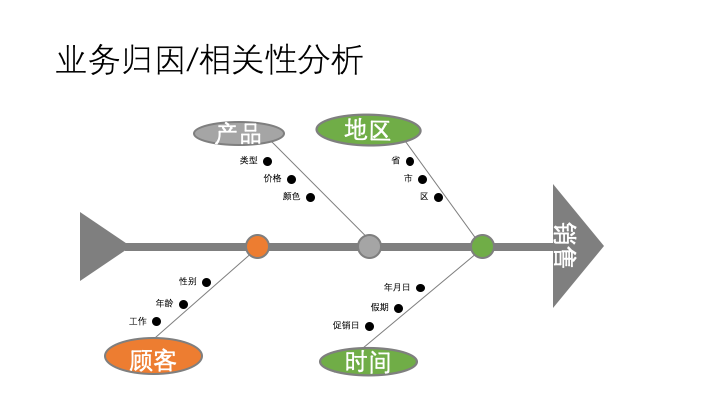
02 事实表和维度表
上文中已经提到事实表中存放定量数据,按照Kimball在《The Data Warehouse Toolkit, 3rd Edition》的定义:在维度模型中,事实表存放业务事件的测度(perfromance measurement)结果。事件的测试,对于销售事件来说,常规的如金额、商品件数等。在维度模型下,获取的测度值需要在各个维度的最小粒度下获取。例如在产品维度上,原始系统数据一个订单上可能包含多个不同的产品,但因为若在产品维度上需要维持到SKU的粒度, 我们就需要对原始订单进行SKU拆分之后接入到事实表。
事实表中的每一行数据必须保持在相同的粒度,否则就会重复数据。现实事件的每一次测度和事实表中的每一行记录是一一对应的,如下图所示。
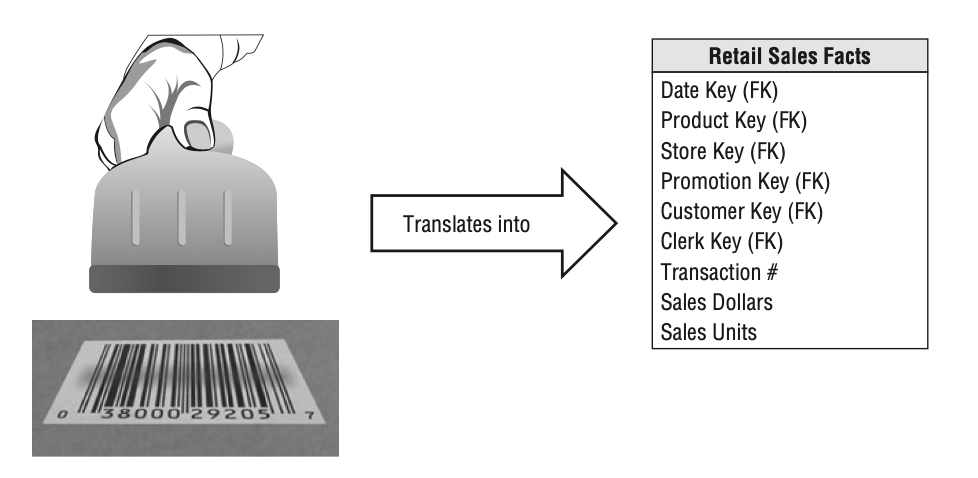
从上图的事实表中,可以看到其字段主要分为3种类型,包括用于每行记录的主键、关联维度表的外键以及测度结果值(如销售任务)。
记录的主键,在上图中为单次交易的流水号,作为每条记录的唯一标识。
事实表中的外键,用于关联维度表中的主键。通过外键关联,可以获取每条事实记录的维度在不同粒度下的值。并且,事实表的外键数量肯定是大于等于两个的。因为只有一个维度的情况下,在一行记录上给出所有的维度粒度即可,不需要再进行2次关联。
测度结果值(通常都为数字类型),可以分成3种类型:可加总型(additive),半加总型(semi-additive)和非加总型(non-additive)。其中,可加总型是指类似于销售金额、销售件数等可以在所有维度都进行累加的值。半加总型是指类似于账户余额等可以在客户维度累加,但是不能在时间维度上累加的值。非加总型是指如件单价等在任何维度上累加都不存在实际意义的值。
维度表中存储的是与测度事件相关的文本描述信息,用于说明每一条事件记录的“who, what, where, when, how, and why“。与事实表相比,维度表的行数相对要少很多,但是字段数量相对要多(与描述的属性粒度相关)。
维度表中的每一个描述字段或者说「属性」是进行业务分析时作为查询约束、分组和数据标签的基础。维度属性值一般使用含义明确的文本方式表示,这样受众可以更好地理解数据处理的报表和分析结果。如果因为属性文本过大等情况,采用数值编码方式存储的属性在生成查询结果或报表时需要对数值编码进行解释。
03 星型模型
在建立分析主题的事实表和维度表之后,通过外键关系便可以将事实表和维度表关联起来。关联之后的ER图,呈放射状,称之为「星型模型」,如下图所示。
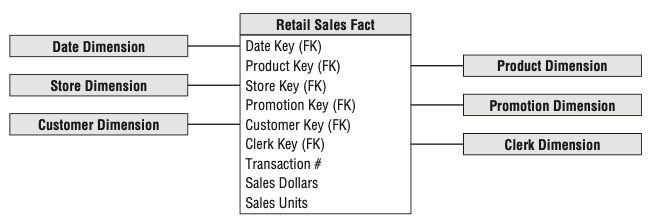
相对于关系数据库中的范式设计,维度设计中的星型模型不用考虑复杂的程序流程,是一种业务分析人员友好的数据组织方式。同时,在分组聚合时有更好的查询性能,具有较好的扩展性——支持增加维度和事实测度结果值。
04 总结
本文从业务分析的归因/相关性分析的方式,引入了维度建模,两者具有相同分析路径。然后介绍了维度建模的基础——事实表和维度表,以及关联之后得到星型模型。
欢迎扫描二维码关注公众号



 浙公网安备 33010602011771号
浙公网安备 33010602011771号