
Java集合
Java集合
本文中引入的源码为JDK11
什么是Java集合
Java集合(Java集合类)是java数据结构的实现。Java集合类是java.util包中重要内容,它允许以各种方式将元素分组,并定义了各种使这些元素更容易操作的方法。Java集合类是Java将一些基本的和使用频率极高的基础类进行封装和增强后再以一个类的形式提供。
Java集合类是用来存放某类对象的(不能存放基本数据类型数据)。集合类有一个共同特定,就是它们只容纳对象(实际上是对象名,即指向地址的指针)。不同的集合类有不同的功能和特点,适合不同的场景。
Java集合框架
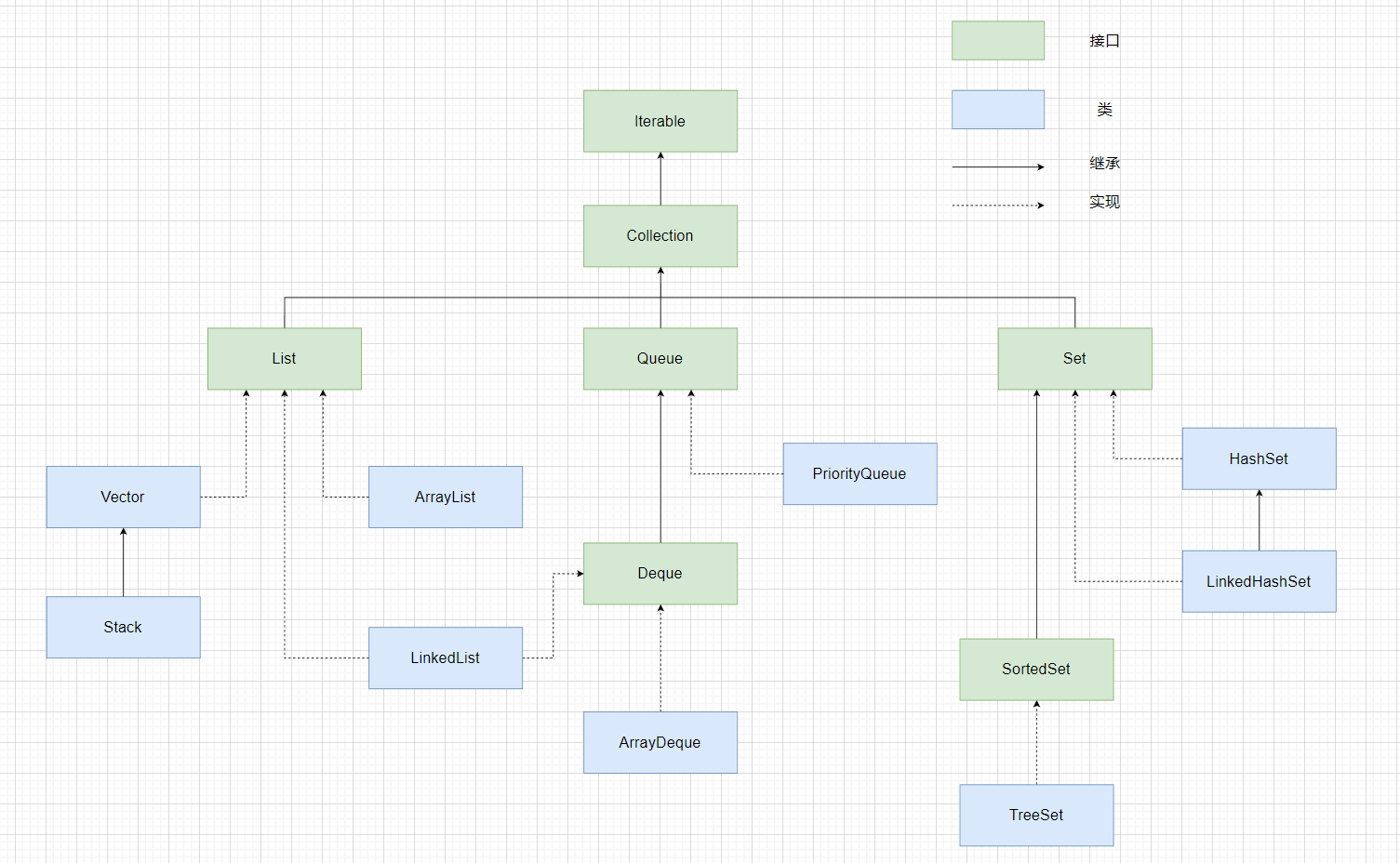
Java集合大致可以分为两大类:Collection和Map
Collection接口:存放单一元素
Map接口:存放key-value键值对
Collection的框架
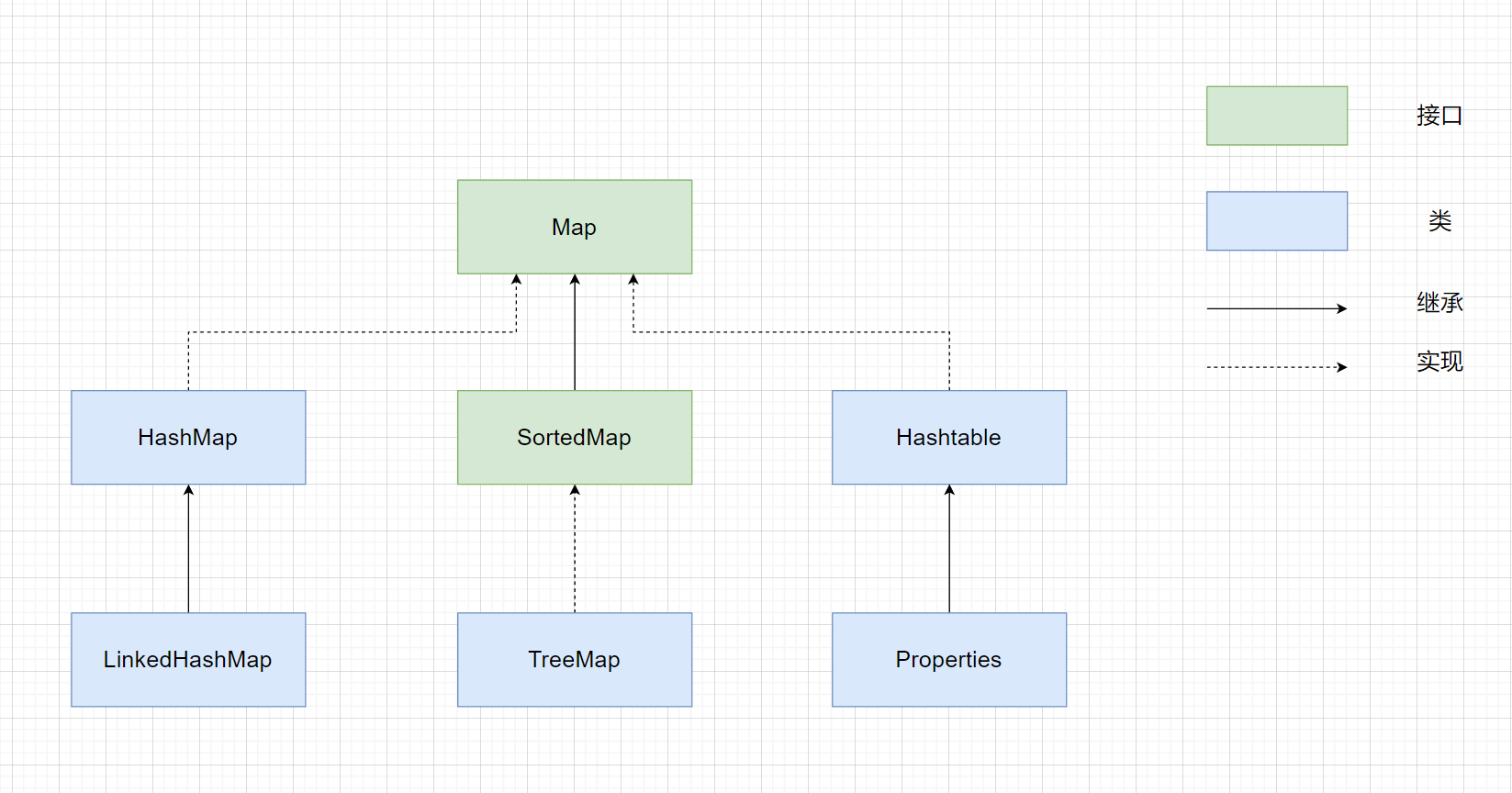
Map的框架
Collection接口
单列集合,用来存放单一对象
collection常用方法
Collection接口中定义了很多常用的方法,这些方法会继承到子接口以及实现类中
新增操作:
boolean add(E e);
添加一个元素到集合中,元素的数据类型必须为Object
boolean addAll(Collection<? extends E> c);
将指定集合的所有元素添加到此集合中
删除操作:
boolean remove(Object o);
删除指定元素的单一实例
boolean retainAll(Collection<?> c);
删除指定集合中的所有元素
void clear();
清空此集合中的所有元素
查询操作:
int size();
返回集合中的元素个数
boolean isEmpty();
判断集合中是否包含元素
boolean contains(Object o);
判断集合中是否包含指定的元素
boolean containsAll(Collection<?> c);
判断集合中是否包含指定集合中的所有元素
遍历操作:
Iterator<E> iterator();
返回此集合中元素的迭代器
迭代器遍历与foreach循环遍历
创建一个集合
List<String> list = new ArrayList(1<<2);
list.add("a");
list.add("b");
list.add("c");
遍历器遍历
Iterator<String> iterator = arrayList.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
foreach遍历(JDK 5新特性,增强for循环,建议使用此种方式进行集合的遍历)
for (String s : arrayList) {
System.out.println(s);
}
List接口
List集合类中元素有序,且可以重复。集合中的每个元素都有其对应的顺序索引
List的三种实现类
List的实现类
- ArrayList
- LinkedList
- Vector
| 底层 | 查询速度 | 增删速度 | 线程安全 | 扩容倍数 | |
|---|---|---|---|---|---|
| ArrayList | 数组 | 快 | 慢 | 不安全 | 无参构造默认为0,第一次容器扩大到10,第二次开始1.5倍扩容 |
| LinkedList | 数组 | 慢 | 快 | 不安全 | 无参构造默认为0,当超过容量时2倍扩容 |
| Vector | 链表 | 快 | 慢 | 安全 | 链表,不存在扩容 |
ArrayList类
1.本质上,ArrayList是一个对象引用的变长数组。ArrayList内部维护了一个Object类型的数组。elementData(修饰属性为transient,表示属性不会被序列化)
对应源码:
transient Object[] elementData;
2.当创建ArrayList对象时,如果使用的是无参构造,则初始elementData的容量为0,如果是有参构造,则elementData为指定大小。
对应源码:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
3.当ArryList对象添加元素时,如果添加后元素的长度小于10,则扩容到10,反正则扩容到元素的长度。第二次扩容则扩容到之前容量的1.5倍。
对应源码:
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
4.ArrayList线程不安全,ArrayList类中对于元素的增删改查操作的方法没有加锁。
LinkedList类
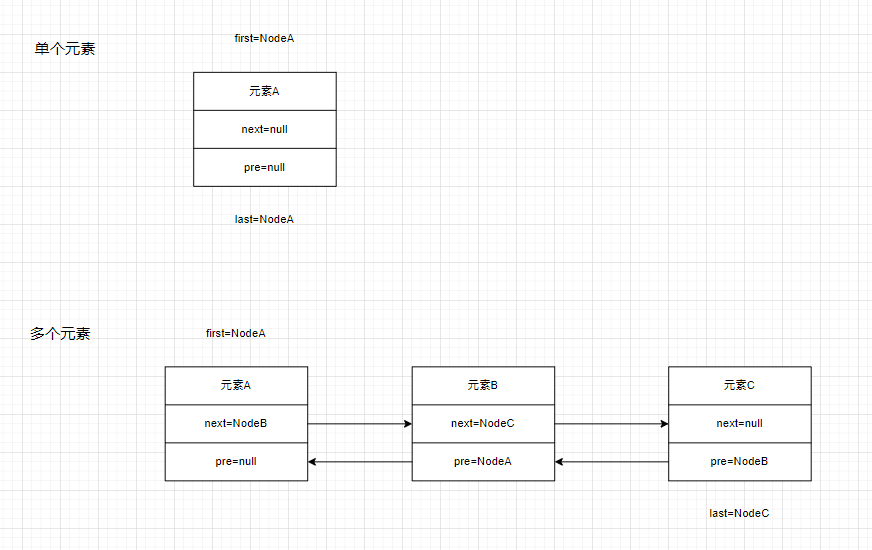
1.LinkedList本质上是一个双向链表,维护了两个属性first和last,分别指向上一个结点与下一个结点。这两个属性是一个静态内部类Node,包含item(元素本身),next(下一个结点,Node类),prev(上一个结点,Node类)。
对应源码:
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
2.如果LinkedList中只有一个元素,则LinkedList的first与last属性均为该元素,对应Node类中的next与prev属性均为null。
3.LinkedList同样线程不安全,因为对于元素增删改查操作的方法没有加锁。
Vector类
1.Vector类与ArrayList类类似,本质上都是一个可变长的对象数组,内部维护着一个对象数组elementData。
对应源码:
protected Object[] elementData;
2.当创建ArrayList对象时,如果使用的是无参构造,则初始elementData的容量为10,如果是有参构造,则elementData为指定大小。还有额外的属性capacityIncrement配置,用来控制当Vector需要扩容时,自动增大的量为capacityIncrement。如果capacityIncrement小于等于零则扩容到之前容量的2倍。
对应源码:
public Vector() {
this(10);
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity <= 0) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
3.Vector线程安全,因为对元素增删改查操作的方法是加锁的(synchronized)。
对应源码:
public synchronized void addElement(E obj) {
modCount++;
add(obj, elementData, elementCount);
}
Queue接口
一种为在处理前保存元素而设计的集合,队列(Queue)通常以先进先出FIFO的方式对元素排序。除此之外还有优先级队列(根据提供的比较器对元素排序)、后进先出队列(堆栈)。每个Queue实现都必须指定其排序属性。
Deque接口
支持两端插入与移除元素的线性集合。Deque接口的常见实现类为ArrayDeque和LinkedList。虽然Deque接口的大多数实现类是对存储的元素数量没有限制,但Deque接口本身是支持对存储元素数据限制。
ArrayDeque类
Deque接口的可变长数组实现类。没有做容量限制。线程不安全。禁止使用null元素。ArrayDeque作为堆栈时使用效率比Stack快,作为队列时使用效率比LinkedList快
1.之前提到LinkedList是双端队列的链表实现,而ArrayDeque则是双端队列的数组实现。ArrayDeque内部维护一个对象数组elements来存储元素,head属性指向首端第一个有效元素的索引指针,tail属性指向尾部第一个可以插入元素的索引指针。
对应源码:
transient Object[] elements;
transient int head;
transient int tail;
2.当ArrayDeque创建对象,如果使用无参构造,会默认创建一个容量为16的对象数组。如果使用有参构造,则根据指定的大小构建对象数组。
对应源码:
public ArrayDeque() {
elements = new Object[16];
}
public ArrayDeque(int numElements) {
elements =
new Object[(numElements < 1) ? 1 :
(numElements == Integer.MAX_VALUE) ? Integer.MAX_VALUE :
numElements + 1];
}
3.ArrayDeque进行扩容,当数组容量小于64时,扩容2个,反之则扩容之前容量的2倍。当head属性大于tail属性或者head属性等于tail属性且head指向的元素不为空的情况下,进行段复制,保证tail与head之间有存放的空间。
对应源码:
private void grow(int needed) {
// overflow-conscious code
final int oldCapacity = elements.length;
int newCapacity;
// Double capacity if small; else grow by 50%
int jump = (oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1);
if (jump < needed
|| (newCapacity = (oldCapacity + jump)) - MAX_ARRAY_SIZE > 0)
newCapacity = newCapacity(needed, jump);
final Object[] es = elements = Arrays.copyOf(elements, newCapacity);
// Exceptionally, here tail == head needs to be disambiguated
if (tail < head || (tail == head && es[head] != null)) {
// wrap around; slide first leg forward to end of array
int newSpace = newCapacity - oldCapacity;
System.arraycopy(es, head,
es, head + newSpace,
oldCapacity - head);
for (int i = head, to = (head += newSpace); i < to; i++)
es[i] = null;
}
}
4.ArrayDeque线程不安全(增删改查方法不加锁),不允许存储null元素。
对应源码:
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
final Object[] es = elements;
es[head = dec(head, es.length)] = e;
if (head == tail)
grow(1);
}
ArrayDeque常用方法
双端队列方法
插入元素
void addFirst(E e) 在数组头部添加元素
void addLast(E e) 在数组尾部添加元素
删除元素
E removeFirst() 删除数组第一个元素,并返回删除元素的值
E removeLast() 删除数组最后一个元素,并返回删除元素的值
获取元素
E getFirst() 获取数组第一个元素
E getLast() 获取数组最后一个元素
单端队列方法
boolean add(E e) 在数组尾部添加元素
E remove() 删除数组中第一个元素,并返回该元素的值
E poll() 删除数组中第一个元素,并返回该元素的值
boolean offer(E e) 在数组尾部添加元素,并返回是否成功
E element() 获取数组中第一个元素
E peek() 获取数组中第一个元素
堆栈方法
void push(E e) 在栈顶添加一个元素
E pop() 移除栈顶元素,并返回移除元素的值
Set接口
不包含重复元素的集合,最多包含一个null元素。元素没有特定的顺序。该接口是对数学集合的抽象。
HashSet类
Hashset的底层是HashMap,讲HashSet的底层原理相当于在讲HashMap的底层原理
1.HashSet的底层是HashMap,HashMap的底层是数组+链表+红黑树。构建一个HashSet对象相当于新建一个HashMap。HashSet添加一个元素等同于在HashMap中添加一个元素,元素的值实际上是作为key,HashSet有一个PRESENT的静态常量,作为value
对应源码:
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
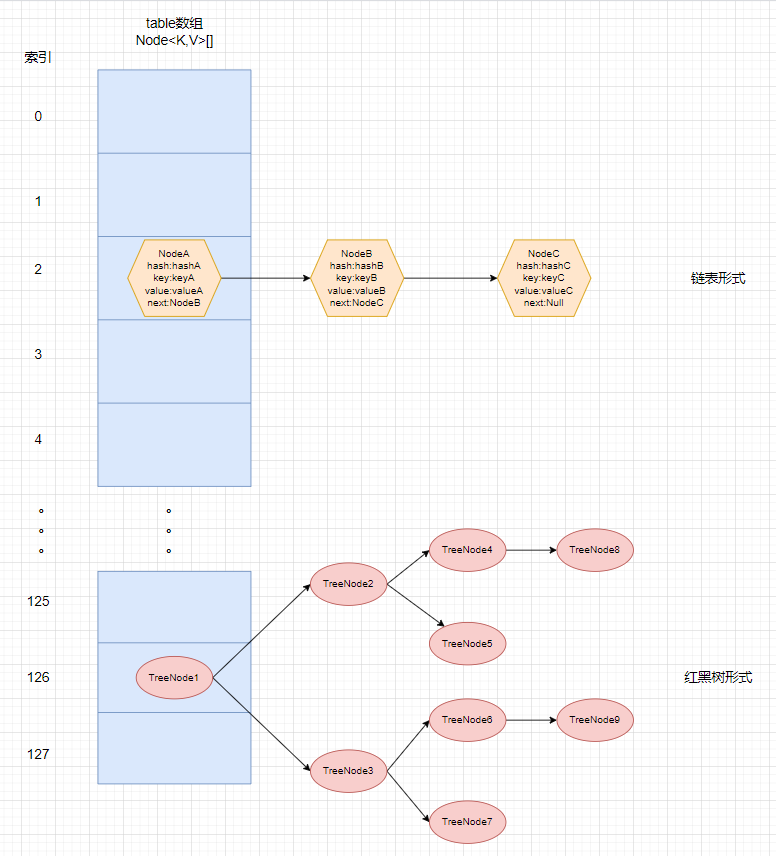
2.HashMap的底层是数组+链表+红黑树。HashMap包含一个链表静态内部类Node<K,V>,一个红黑树静态内部类TreeNode<K,V>。使用对象数组table来存储元素。默认情况下当一个链表上的元素个数达到8个且数组table容量到达64个后会对将该链表转换成红黑树。
对应源码:
// 默认的初始容量为1X2X2X2X2=16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 默认的加载因子0.75,用来计算扩容临界值=当前容器容量x加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表转变成二叉树形式的链表元素数
static final int TREEIFY_THRESHOLD = 8;
// 链表转换成二叉树形式的最小容量数
static final int MIN_TREEIFY_CAPACITY = 64;
// Node类,包含hash属性、key属性、value属性、next属性。其中next用来链接下一个元素
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
// Node数组
transient Node<K,V>[] table;
// 扩容临界值
int threshold;
// 加载因子用来计算扩容临界值threshold
final float loadFactor;
//TreeNode类,由于包含很多方法,这里只展示构造方法,包含parent、left、right、prev属性用来链接元素,red属性用来判断红树还是黑树
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}
3.在HashSet新增一个元素,元素的值会作为HashMap的key存入。HashMap根据key值生成hash值(hash值^hash值>>>16),再根据hash值与数组容量转换成索引值((数组容量-1)&hash),如果数组下的索引值没有元素则直接存入,反之则判断此索引下的元素的是否相同(比较hash值、key值、value值),如果相同则重复不进行插入,如果不同则遍历此元素下的链表或红黑树,如果存在相同元素则不进行插入,如果不存在则插入元素。如果插入成功,则会计算元素个数是否达到临界值,达到则进行扩容,扩容到原来的2倍。
对应源码:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
LinkedHashSet类
LinkedHashSet是HashSet的子类。底层是一个LinkedHashMap,LinkedHashMap是HashMap的子类,因此LinkedHashSet的底层原理(同样是LinkedHashMap的底层原理)是哈希表(数组+链表+红黑树)+双向链表。由于它维护了一个双向链表,贯穿所有条目,因此具有可预测的迭代顺序(插入顺序)。
1.LinkedHashSet是HashSet的子类,具有HashSet的map属性。LinkedHashSet的构造方法是调用父类的构造方法,创建一个LinkedHashMap。默认无参构造时的容量为16,加载因子为0.75。
对应源码:
LinkedHashSet类:
public LinkedHashSet() {
super(16, .75f, true);
}
HashSet类:
private transient HashMap<E,Object> map;
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
2.由于LinkedHashSet初始化会创建一个LinkedHashMap,因此需要了解LinkedHashMap的底层原理。LinkedHashMap是HashMap的子类,具有HashMap的属性table(对象数组)、Node类(链表)、TreeNode类(红黑树)。除此之外,LinkedHashMap有自己的Entry类(链表)、以及head属性(双向链表头)、tail属性(双向链表尾)。
对应源码:
LinkedHashMap类:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
3.LinkedHashSet的新增元素和HashSet一样,同样是调用HashMap的put方法,不同的是LinkedHashSet对应的时LinkedHashMap,LinkedHashMap对newNode、newTreeNode方法进行了重写,在插入元素后会更新双向链表的指向:head属性(双向链表头)、tail属性(双向链表尾)、Entry类的before属性(链表前一个),after属性(链表后一个)
对应源码:
HashMap类:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
LinkedHashMap类:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<>(hash, key, value, next);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
4.LinkedHashMap的扩容机制与HashMap一样,没有对扩容方法做重写
TreeSet类
TreeSet是NavigableSet的子类。底层是一个TreeMap。TreeMap的底层原理是红黑树,使用元素的自然顺序或者在创建集合是提供的比较器(Comparator)对元素进行排序。
1.TreeSet的底层是TreeMap,其内部维护着一个m属性(用于构建TreeMap),一个静态常量PRESENT作为存入TreeMap的value值。
对应源码:
TreeSet类:
private static final Object PRESENT = new Object();
private transient NavigableMap<E,Object> m;
public TreeSet() {
this(new TreeMap<>());
}
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
TreeMap类:
private final Comparator<? super K> comparator;
public TreeMap() {
comparator = null;
}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2.TreeMap的底层原理是红黑树,内部维护一个比较器comparator,一个静态内部类Entry(红黑树)-包含key属性、value属性、left属性(左子结点)、right(右子结点)、parent(父节点),一个根节点root。
对应源码:
TreeMap类:
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
//静态类中包含很多方法,这里只展示构造方法
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
}
3.当TreeSet类新增一个元素时,会作为TreeMap的key值存入,TreeMap会先判断根节点root属性是否为空,如果为空则此元素作为根节点存入集合。之后会根据默认比较器或者自定义比较器对key值进行比较(比较器对两个key值进行比较,返回1时是第二个key小于第一个key,返回0时是两个key相等,返回-1时是第二个key大于第一个key),从根节点开始进行比较,如果根节点key值大于该元素的key则继续比较根节点左子节点的key值,如果根节点key值小于该元素的key值则继续比较根节点右子节点的key值,如果相同则不添加直接返回,以此类推找到此元素的父节点。找个父节点后再根据比较器的结果,将元素放入左子节点或优子节点或key相同直接返回。
对应源码:
TreeMap类:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
Map接口
双列集合,存放键值对-Entry<K,V>。Map不能包含重复的键(key),每个键(key)最多只能映射到一个值(value)。
Map常用方法
新增操作:
V put(K key, V value);
添加一组键值对
void putAll(Map<? extends K, ? extends V> m);
添加多组键值对
删除操作:
V remove(Object key);
移除键为key的键值对,并返回key映射的value值
void clear();
清空所有键值对
查询操作:
int size();
返回Map中的键值对个数
boolean isEmpty();
判断Map中是否包含键值对
V get(Object key);
返回指定key映射的value值,如果没有则返回null
default V getOrDefault(Object key, V defaultValue)
返回指定key映射的value值,如果没有则返回默认的defaultvalue值
遍历操作:
Set<K> keySet();
返回Map中所有key元素的集合
Collection<V> values();
返回Map中所有value元素的集合
Set<Map.Entry<K, V>> entrySet();
返回Map中的所有键值对的集合
Map遍历
由于Map本身没有继承Iterable(迭代器),不能直接使用迭代器。需要借助自身方法,转换为Set形式进行使用
创建一个HashMap
Map<String, Object> map = new HashMap<>();
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
迭代器遍历
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> entry = iterator.next();
ystem.out.println("key:" + entry.getKey() + ",value:" + entry.getValue());
}
foreach遍历
for (Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println("key:" + entry.getKey() + ",value:" + entry.getValue());
}
HashMap类
基于哈希表(数组+链表+红黑树)的实现类,继承Map接口,具体底层实现可以参考上文的HashSet类,因为HashSet类的底层是HashMap。
LinkedHashMap类
基于哈希表(数组+链表+红黑树)和双向链表的实现类,继承HashMap实现类和Map接口,具体底层实现可以参考上文的LinkedHashSet类,因为LinkedHashSet类的底层是LinkedHashMap。
TreeMap类
基于红黑树的实现类,继承NavigableMap接口,具体底层实现可以参考上文的TreeSet类,因为TreeSet类的底层是TreeMap。
HashTable类
基于哈希表(数组+链表)的实现类,继承Map接口。不允许键值为null
1.HashTalbe的底层是数组+链表,内部维护着一个静态类Entry<K,V>,其内部包含hash属性,key属性,value属性,next属性(用来链接下一个Entry类)。除此还维护着对象数组(对象类型为Entry)table,count属性(记录键值对个数),threshold(扩容临界值),loadFactor(加载因子)
对应源码:
HashTable类:
//由于Entry类中包含很多方法,这里只展示构造方法
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
private transient Entry<?,?>[] table;
private transient int count;
private int threshold;
private float loadFactor;
2.当创建一个HashTable对象时,如果是无参构造时会默认构建一个容量为11对象数组,加载因子为0.75。扩容临界值=数组容量X加载因子。如果是有参构造则会根据参数创建对应容器的对象数组。
对应源码:
HashTable类:
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
3.当HashTable新增一个键值对时,会对value做为空判断,确保value值不为空。之后根据key值生成hash值,通过哈希值与对象数组的长度得到索引值((hash & 0x7FFFFFFF)%tab.length)。遍历对应索引值中链表的每一个键值对,如果存在hash与key属性相同的情况则直接返回value值。如果不存在的话则该键值对作为链表的头部插入。
对应源码:
HashTable类:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
modCount++;
}
4.当元素的个数大于等于扩容临界值时,则进行扩容,扩容至原来的2倍+1,原理是创建一块新的空间,旧的数据重写计算索引值存入新空间中。
对应源码:
HashTable类:
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
5.HashTable是线程安全的,因为针对键值对的增删改查操作都是加锁的。
Properties类
Properties类表示一组持久的属性。这些属性可以保存到流中,也可以从流中加载。属性列表中每个键和映射的值均为字符串类型。Properties继承HashTable类,所以可以使用put方法存入键值对,但建议使用setProperty方法存入
1.Properties类继承Hashtable类,但Properties类没有将键值对存入Hashtable的属性中,而是存储在内部的map属性(ConcurrentHashMap)中。创建一个Properties对象时,无参构造默认容量为8,有参构造则根据参数设置容量大小。
对应源码:
Properties类:
private transient volatile ConcurrentHashMap<Object, Object> map;
protected volatile Properties defaults;
public Properties() {
this(null, 8);
}
public Properties(int initialCapacity) {
this(null, initialCapacity);
}
private Properties(Properties defaults, int initialCapacity) {
// use package-private constructor to
// initialize unused fields with dummy values
super((Void) null);
map = new ConcurrentHashMap<>(initialCapacity);
this.defaults = defaults;
// Ensure writes can't be reordered
UNSAFE.storeFence();
}
2.ConcurrentHashMap类继承ConcurrentMap接口,是一个提供线程安全和原子性保证的Map。底层原理与HashMap类似,都是数组+链表+红黑树的数据结构,但ConcurrentHashMap保证了线程安全(volatile+synchronized),存入键值对不允许为空。
对应源码:
ConcurrentHashMap类:
//Node还有很多方法,这里只展示构造方法
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val) {
this.hash = hash;
this.key = key;
this.val = val;
}
Node(int hash, K key, V val, Node<K,V> next) {
this(hash, key, val);
this.next = next;
}
}
//volatile关键词,保证内存可见性,禁止指令重排
transient volatile Node<K,V>[] table;
private transient volatile Node<K,V>[] nextTable;
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
3.Properties类的常用方法
public synchronized void load(Reader reader) throws IOException
public synchronized void load(InputStream inStream) throws IOException
从输入流中读取属性列表
public synchronized Object setProperty(String key, String value)
设置属性
public String getProperty(String key)
获取对应的属性值
public String getProperty(String key, String defaultValue)
获取对应的属性值,如果不存在则取默认值
eg: 在项目路径下存放一个配置文件test.properties,使用Properties类来加载配置文件属性列表,获取其中的属性值
配置文件内容:
services.test.port=8080
services.test.server-name=test
services.test.mysql.user-name=mysqld
services.test.mysql.user-password=123456
代码:
Properties properties = new Properties();
FileInputStream fileInputStream = new FileInputStream(System.getProperty("user.dir") + File.separator + "test.properties");
properties.load(fileInputStream);
fileInputStream.close();
System.out.println(properties.getProperty("services.test.mysql.user-password"));
Collections工具类
操作集合的工具类,Collections提供了一系列静态方法对集合元素进行排序、查询、修改等操作
常用的静态类:
private static class EmptySet<E>
构建一个空的Set
private static class EmptyList<E>
构建一个空的List
private static class EmptyMap<K,V>
构建一个空的Map
private static class SingletonSet<E>
构建一个单一的Set
private static class SingletonList<E>
构建一个单一的List
private static class SingletonMap<K,V>
构建一个单一的Map
常用的静态方法:
排序操作:
public static void reverse(List<?> list)
反转List中的元素
public static void shuffle(List<?> list)
对List中的元素随机排序
public static <T extends Comparable<? super T>> void sort(List<T> list)
根据元素的自然顺序进行排序(升序)
public static <T> void sort(List<T> list, Comparator<? super T> c)
根据指定的Comparator(比较器)进行排序
public static void swap(List<?> list, int i, int j)
对指定索引的两个元素进行交换
查找操作:
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
根据元素的自然顺序,返回集合中最大的元素
public static <T> T max(Collection<? extends T> coll, Comparator<? super T> comp)
根据指定的Comparator(比较器),返回集合中最大的元素
public static <T extends Object & Comparable<? super T>> T min(Collection<? extends T> coll)
根据元素的自然顺序,返回集合中最小的元素
public static <T> T min(Collection<? extends T> coll, Comparator<? super T> comp)
根据指定的Comparator(比较器),返回集合中最小的元素
public static int frequency(Collection<?> c, Object o)
返回集合中指定元素出现的次数
参考资料
https://www.bilibili.com/video/BV1YA411T76k/
https://blog.csdn.net/ningmengshuxiawo/article/details/118736070

 浙公网安备 33010602011771号
浙公网安备 33010602011771号