
SQL语言
SQL语言
SQL(Structured Query Language),结构化查询语言。是关系型数据库(RDBMS)的标准语言
不同关系型数据库都支持SQL语句,但为了加强SQL的语言能力,在标准SQL的基础上进行了不同的拓展
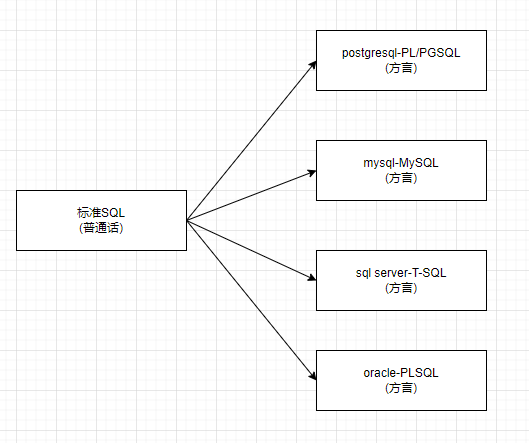
SQL的功能
| SQL功能 | 动词 |
|---|---|
| 数据查询(Data Query Language) DQL | SELECT |
| 数据定义(Data Definition Language) DDL | CREATE,DROP,ALTER |
| 数据操纵(Data Manipulation Language) DML | INSERT,UPDATE,DELETE |
| 数据控制(Data Control Language) DCL | GRANT,REVOKE |
| 事务控制(Transaction Control Language) TCL | COMMIT,ROLLBACK,SAVEPOINT |
SQL的基本规则
- 一个SQL语句以分号";"结尾 eg: select * from table;
- SQL语句不区分大小写
- 字段(一列):又称为属性,描述事物的特征
- 元组(一行):又称为记录,描述一个具体的事务
SQL语句
mysql相关的命令行语句
建议安装mysql数据库,进入数据库,敲一遍SQL语句,加深印象
# 连接mysql数据库 用户 密码
mysql -uroot -p123456
# 修改用户密码为123
update mysql.user set authentication_string=password('123') where user='root' and Host = 'localhost';
# 刷新权限
flush privileges;
# 查看所有数据库
show databases;
# 切换到数据库xx
use xx
# 查看数据中的所有表
show tables;
# 显示xx表的信息
describe xx;
# 查询xx表中的所有数据
select * from xx;
# 退出连接
exit;
注释语句
单行注释
使用"--"符号(双减号),"--"符合需要与注释内容用空格隔开
eg:
-- this is test
多行注释
使用"/* ... */"
eg:
/*
this is test
*/
DDL-数据定义语言
实现数据定义功能,可以对数据库用户、表、视图、索引进行定义、修改、撤销操作
1.操作数据库的用户(不常用)
# 创建数据库用户xx密码为xx
create user ’xx‘ identified by 'xx';
# 更换数据用户xx的密码为xx
alter user ‘xx’ identified by 'xx';
# 删除数据库用户xx
drop user ‘xx’;
2.操作数据库
# 创建数据库xx
create database xx;
# 创建数据库xx,如果不存在则创建
create database if not exists xx;
# 查看所有数据库
show databases;
# 查看xx数据库的定义信息
show create database xx;
# 修改xx数据库的字符集为utf8排序规则为utf8_general_ci
alter database xx character set utf8 collate utf8_general_ci;
#删除数据库xx
drop database xx;
3.操作表
创建表就需要对字段的数据类型、长度、属性进行定义,下面介绍一下mysql的数据类型与属性,其他数据库类似只是不同数据类型的名称有一些区别
常用数据类型
| 数值类型 | 字节 | 描述 |
|---|---|---|
| tinyint | 1个字节 | 十分小的数据 |
| smallint | 2个字节 | 较小的数据 |
| mediumint | 3个字节 | 中等大小数据 |
| int | 4个字节 | 标准的整数(常用) |
| bigint | 8个字节 | 较大的数据 |
| float | 4个字节 | 浮点数 |
| double | 8个字节 | 浮点数(常用) |
| decimal | 字符串形式的浮点数(用于金融计算) |
| 字符串类型 | 长度 | 描述 |
|---|---|---|
| char | 0-255 | 字符串固定大小 |
| varchar | 0-65535 | 可变字符串(常用) |
| tinytext | 2^8-1 | 微型文本 |
| text | 2^16-1 | 文本串 |
| 时间日期类型 | 描述 |
|---|---|
| date | YYYY-MM-DD 日期格式 |
| time | HH:mm:ss 时间格式 |
| datetime | YYYY-MM-DD HH:mm:ss 日期+时间格式(常用) |
| timestamp | 时间戳 1970.1.1到现在的毫秒数(常用) |
| year | 年份 |
属性
| mysql workbench中字符属性的含义 | 全称 | 含义 |
|---|---|---|
| PK | primary key | 主键 |
| NN | not null | 非空,不赋值会报错,相对的是NULL表示可以为空,默认是NULL |
| UQ | unique | 唯一 |
| BIN | binary | 二进制 |
| UN | unsigned | 无符号整数,不能为负数 |
| ZF | zero fill | 用0填充不足位数 eg: int(3) 5 --005 |
| AK | auto increment | 自增,必须是整数类型,默认+1,可以自定义 |
| Default | 默认值 |
操作
# 创建user表
create table user(
id int(5) NOT NULL,
name varchar(45) NOT NULL,
pwd varchar(45) default '123456',
PRIMARY KEY (id)
);
注:
default 当此数据没有其他值时默认为xx
关于设置字段自增,默认开始值为1,每条记录递增1 不同数据库的自增语法有些区别,这里就不添加自增属性了
# 查看此数据库的所有表
show tables;
# 查看user表结构
desc user;
# 查看创建user表的信息
show create table user;
# 修改user表明为user1
alter table user rename to user1;
# 为user表新增一个字段grade
alter table user add grade int(5) NOT NULL;
# 为user表删除一个字段grade
alter table user drop grade;
# 删除user表
drop table user;
# 如果存在user表则删除
drop table if exists user;
# 清除user表内数据,不删除表本身
truncate table user;
操作索引
在不读取整个表的情况下,索引使数据库应用程序可以更快的查找数据
作用
- 加快查询速度
- 保证行的唯一性
操作
# 在user表上创建简单的索引index_name,对应的字段为name,允许使用重复的值
create index index_name on user (name);
# 在user表上创建唯一索引index_id(唯一索引表示两个行不能拥有相同索引值),对应的字段为id
create unique index index_id on user (id);
# 删除索引不同数据库的删除有所不同,这里仅以mysql的删除索引命令为例子:删除user表中的index_id索引
alter table user drop index index_id;
DML-数据操纵语言
实现对数据的更新功能,主要包括插入数据(insert)、更新数据(update)、数据删除(delete)
插入数据(insert)
# 向user表插入一行记录(包含所有字段)
insert into user (id,name,pwd) values (1,'小明','123');
# 向user表插入一行记录(包含所有字段,另一种写法:不加字段但值对应字段的顺序必须一致,不建议这样写)
insert into user values (2,'小智','111');
# 向user表插入一行记录(添加部分字段,非空字段是必须填写的不然会报错)
insert into user (id,name) values (3,'小张');
注:
字符类型的字段值需要用单引号括起来''
更新数据(update)
# 更新user表中所有行的name字段为xx(不带条件子句where)
update user set name = 'xx';
# 更新user表中id为1的行name字段为xx(带条件子句where)
update user set name = 'xx' where id = 1;
删除数据(delete)
# 删除user表中所有记录
delete from user;
# 删除user表中name字段是xx的记录
delete from user where name = 'xx';
DQL-数据查询语言
实现对数据查询的功能,主要包含基本查询、条件查询、聚合函数、分组查询、排序查询、分页查询、模糊查询、多表联查等等
查询语句的基本格式
select 字段列表
from 表名列表
where 条件列表
group by 分组字段列表
having 分组后的条件列表
order by 排序字段列表
limit 分页参数;
创建student表并插入数据方便查询
# 创建学生表
create table student(
id int(5) NOT NULL,
name varchar(45) NOT NULL,
sex varchar(45),
age int(3),
score double,
PRIMARY KEY (id)
);
# 插入5条学生记录
insert into student (id,name,sex,age,score) values
(1,'小明','男',14,85.6),
(2,'小红','女',12,75.6),
(3,'小智','男',11,68.3),
(4,'小刚','男',13,75.0),
(5,'小霞','女',15,80.2);
基本查询
select 字段列表 from 表名列表;
# 查询student表中所有记录
select * from student;
# 查询student表中id,name,score字段的记录
select id,name,score from student;
# 查询student表中id,name,score字段的记录并给name取一个别名'姓名'
select id,name as '姓名',score from student;
注:
as :取别名,可以给字段、表取别名
# 查询student表中sex字段去除重复的记录
select distinct sex from student;
常用函数与聚合函数
select 聚合函数(字段) from 表名列表;
常用函数
-- 数学运算函数
# x的绝对值
select abs(x);
# x向上取整
select ceiling(x);
# x向下取整
select floor(x);
# 返回一个0-1之间的随机数
select rand();
# 判断x的符号 零:0,负数:-1,正数:1
select sign(x);
-- 字符串函数
# 计算字符串长度
select char_length('abc');
# 拼接字符串
select concat('a','b','c');
# 小写字母
select lower('Abc');
# 大写字母
select upper('Abc');
# 返回第一次出现子串的索引
select instr('hello','he');
# 替换出现的指定字符串
select replace('abc','b','ee');
# 反转
select reverse('abc');
-- 时间和日期函数
# 获取当前日期 YYYY-MM-DD
select current_date();
# 获取当前时间 YYYY-MM-DD HH:mm:ss
select now();
# 获取本地时间
select localtime();
# 获取系统时间
select sysdate();
# 获取某一段时间
select year(now());
select month(now());
select day(now());
select hour(now());
select minute(now());
select second(now());
-- 系统信息函数
# 系统用户
select system_user();
# 系统版本
select version();
聚合函数
| 函数名称 | 描述 |
|---|---|
| count() | 计算格式 |
| sum() | 计算和 |
| avg() | 计算平均值 |
| max() | 计算最大值 |
| min() | 计算最小值 |
# 计算student表中所有学生成绩的和、平均值、最大值、最小值、个数
select sum(score) as 'sum',avg(score) as 'avg',max(score) as 'max',min(score) as 'min',count(score) as 'count' from student;
条件查询(where)
select 字段列表 from 表名列表 where 条件列表
运算符
| 比较运算符 | 描述 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| != | 不等于 |
| between ... and ... | 确定范围内(包含边界) |
| in(..) | 在确定集合中 |
| like xx | 模糊查询('_'表示匹配单个字符,'%'表示匹配任意个字符) |
| is null | 为空 |
| 逻辑运算符 | 描述 |
|---|---|
| and / && | 与 |
| or / || | 或 |
| not / ! | 非 |
# 查询student表中id大于等于2的所有记录
select * from student where id >=2;
# 查询student表中id在2-4范围内的所有记录
select * from student where id between 2 and 4;
# 查询student表中id在(1,3,5)集合内的所有记录
select * from student where id in (1,3,5);
# 查询student表中name中是’_红‘的所有记录;
select * from student where name like '_红';
# 查询student表中id>2且score >70的所有记录;
select * from student where id >2 and score >70;
# 查询student表中 id>3 或 score>80的所有记录;
select * from student where id >3 or score >80;
# 查询student表中 id !=3的所有记录
select * from student where id !=3;
分组查询(group by)
select 字段列表 from 表名列表 where 条件列表 group by 分组列表 having 分组后的条件列表
where与having的区别
- where是分组之前进行过滤,不满足where条件不参与分组。不能对聚合函数进行判断
- having是分组之后对结果进行过滤。可以对聚合函数进行判断
# 按照性别分组,分别查询男女同学的平均成绩
select sex, avg(score) from student group by sex;
# 按照性别分组,分别查询男女同学的平均成绩,低于70分的不参与分组
select sex, avg(score) from student where score >70 group by sex;
# 按照性别分组,分别查询男女同学的平均成绩,低于70分的不参与分组,分组之后查找分数大于80的记录
select sex, avg(score) from student where score >70 group by sex having avg(score) > 80;
排序查询(order by)
select 字段列表 from 表名列表 where 条件列表 group by 分组列表 having 分组后的条件列表 order by 排序字段列表
排序方式
- 升序:asc(当不写排序方式时默认按照升序排序)
- 降序:desc
# 查询所有学生记录按照成绩降序排序
select * from student order by score desc;
# 查询所有学生记录按照成绩降序排序,如果出现成绩相同按照id升序排序
select * from student order by score desc, id asc;
分页查询(limit)
select 字段列表 from 表名列表 where 条件列表 group by 分组列表 having 分组后的条件列表 order by 排序字段列表 limit 分页参数
分页查询是数据库的方言,不同数据库的分页语法有所不同
limit 起始索引,每页显示的条数
起始索引 = (查询页面-1)*每页显示的条数
# 查询student表第一页的记录(每页记录2条) (1-1)*2 =0
select * from student limit 0,10;
# 查询student表第二页的记录(每页记录2条) (2-1)*2 = 2
select * from student limit 2,2;
# 查询student表第二页的记录(每页记录3条) (3-1)*2 = 4
select * from student limit 4,2;
内外连接查询(join)
join用于把两个表或多个表的行结合起来,相关用法有7种
select 字段列表 from table1 join table2 on 判断列表 where 条件列表
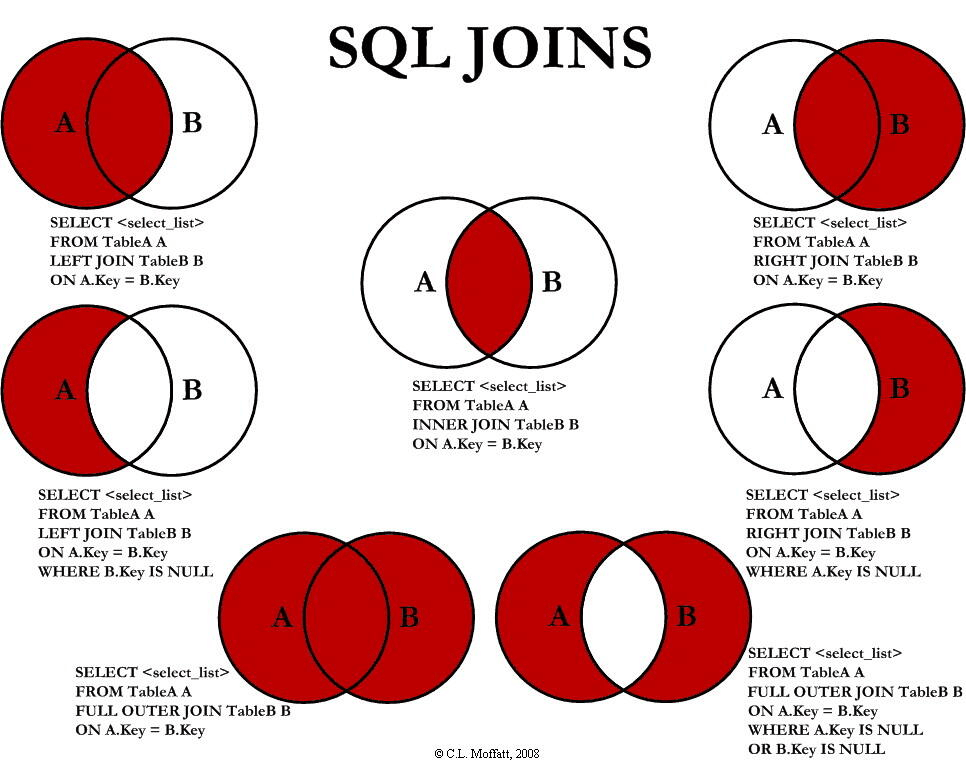
| 操作 | 描述 |
|---|---|
| inner join | 显示符合条件的记录(默认的join表示inner join) |
| left join | 显示符合条件的记录以及左边表不符合条件的记录,不符合条件的右边数据会显示null |
| right join | 显示符合条件的记录以及右边表不符合条件的记录,不符合条件的左边数据会显示null |
| full join | 显示符合条件的记录以及左右边表不符合条件的记录,不符合的条件的数据会显示null(mysql不支持此语法) |
创建一张班级表并插入数据方便多表联查
# 创建班级表 id为学生id,name为班级名称
create table class(
id int(5) NOT NULL,
name varchar(45) NOT NULL,
PRIMARY KEY (id)
);
# 插入8条班级记录
insert into class (id,name) values
(1,'A班'),
(2,'B班'),
(3,'A班'),
(4,'C班'),
(5,'B班'),
(6,'A班'),
(7,'C班'),
(8,'B班');
# 插入2条学生记录
insert into student (id,name,sex,age,score) values
(11,'小刘','男',14,85.6),
(12,'小李','女',12,75.6);
# 查询学生表的id,name 连接班级表的id,name,连接条件是两个id相同(内连接)
select student.id,student.name,class.id,class.name from student join class on student.id = class.id;
# 查询学生表的id,name 连接班级表的id,name,连接条件是两个id相同,显示左表的所有数据以及交集(左外连接)
select student.id,student.name,class.id,class.name from student left join class on student.id = class.id;
# 查询学生表的id,name 连接班级表的id,name,连接条件是两个id相同,显示右表的所有数据以及交集(右外连接)
select student.id,student.name,class.id,class.name from student right join class on student.id = class.id;
嵌套查询
查询语句中包含子查询语句就是嵌套查询,不常用,可读性差
查找学生表中成绩最高的学生信息
select * from student where score = (select max(score) from student);
DCL-数据控制语言
数据库中的数据库由多个用户共享,为保证数据库的安全,SQL语言提供了数据控制语句(DCL)对数据库进行统一的控制管理
管理用户
# 创建用户
create user '用户名'@'主机名' identified by '密码';
注:
主机名:指定用户在哪个主机上可以登陆,本地用户为localhost,任意远程主机登陆可以使用通配符%
mysql创建的用户可以在mysql库中user表中查看用户
# 创建demo用户可以在任意主机上登陆mysql服务器,密码为123
create user 'demo'@'%' identified by '123';
# 删除用户
drop user '用户名'@'主机名';
# 删除demo用户
drop user 'demo'@'%';
授权与撤销权限
新用户创建后是没有权限的,需要授权才能操作数据库
# 授权
grant 权限1,权限2... on 数据库名.表名 to '用户名'@'主机名';
注:
权限: 有create、alter、alter、select、insert、update等等权限,授予全部权限则使用all
数据库名.表名 :此用户可以操作的具体数据库名与表名,如果授予全部库与表的操作则使用*.*
# 给demo用户分配对test数据库中所有表的创建表、修改表、插入记录、更新记录、删除记录、查询记录的权限
grant create,alter,insert,update,delete,select on test.* to 'demo'@'%';
# 查看权限
# 查看demo用户的权限
show grants for 'demo'@'%';
# 撤销权限
revoke 权限1,权限2... on 数据库名.表名 to '用户名'@'主机名';
# 收回demo用户对test数据库中所有表的所有权限
revoke all on test.* from 'demo'@'%';
TCL-事务控制语言
事务:一个或一组sql语句组件一个执行单元,此执行单元要么全部执行,要么全部不执行
事务的ACID原则
1.原子性(Atomicity)
事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
2.一致性(Consistency)
数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
3.隔离性(Isolation)
并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
4.持久性(Durability)
一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
事务的类别
- 隐式事务:没有明显的开启与结束标记,例如insert语句
- 显式事务: 有明显的开启与结束标记,例如 begin commit语句
显示事务的用法
mysql默认是开启事务自动提交
# 开启自动提交
set autocommit = 1;
# 关闭自动提交,如果手动处理事务就需要关闭
set autocommit = 0;
# 开启事务 标记一个事物的开始,从这个之后的sql都在同一个事务内
begin 或者 start transaction
# 执行sql
insert xx
delete xx
# 提交 一个事务结束
commit
# 回滚 如果在commit之前使用会回到begin标记之前的样子
rollback
# 设置一个事物的保存点
savepoint 保存点名
# 回滚到保存点
rollback to savepoint 保存点名
# 撤销保存点
release savepoint 保存点名
4种事务隔离级别
| 隔离级别 | 描述 |
|---|---|
| read uncommitted(读未提交的数据) | 允许事务读取未被其他事务提交的变更(脏读、不可重复读、幻读问题都会出现) |
| read commited(读已提交的数据) | 只允许事务读取已经被其他事务提交的变更(可以避免脏读) |
| repeatable read(可重复读) | 确保事务可以多次从一个字段中读取相同的值,在这个事务持续期间,禁止其他事务对这个字段进行更新(可以避免脏读、不可重复读) |
| serializable(串行化) | 确保事务可以从一个表中读取相同的行,在这个事务持续期间,禁止其他事务对该表进行插入、更新、删除操作,避免所有并发但性能低(可以避免脏读、不可重复读、幻读) |
mysql支持4种事务隔离级别,mysql默认事务级别为repeatable read(可重复读)
隔离导致的3种问题
- 脏读:事务A读取了事务B更新的数据,之后事务B进行了回滚操作,那么事务A读取到的数据是脏数据
- 不可重复读:事务A多次读取同一数据,事务B在事务A多次读取过程中对数据进行了更新并提交,导致事务A多次读取到同一数据的结果不一致
- 幻读:事务A将学生表的成绩从具体分数改为ABC等级,但在修改过程中事务B插入了一条成绩是具体分数的记录,当事务A提交后发现还有一条记录没有改过来,好像出现了幻觉。
不可重复读与幻读的区别:
不可重复读的重点在修改,多次读取同一条记录发现某些字段的值被修改
幻读的重点在新增或删除,修改完数据后发现某些记录没有被修改
参考网址
https://blog.csdn.net/weixin_43294936/article/details/123268223

 浙公网安备 33010602011771号
浙公网安备 33010602011771号