性能测试基本概念
1.1.什么是软件性能
1.1.1定义
用户角度:从客观的角度来说,事务的结束应该是系统返回所有的数据,相应时间应该是从用户操作开始到左右数据返回完成的整个耗时;
优化策略1:当少部分数据返回之后就立刻将数据呈现在用户面前,则用户感受到的响应时间就会远远小于实际的事务响应时间(这是在C/S结构的管理系统里面常用的一种技巧)
管理员角度:

开发者角度
1.1.2 Web前端性能
延伸:web前端的响应时间主要是浏览器的展现和浏览器端脚本(如JS脚本)执行所消耗的时间,严格上来说,这个时间并非与服务端性能毫无关系。例如,大多数Ajax应用都会使用JS从服务器获取数据,获取数据所需要消耗的时间明显依赖于服务端性能的。然而,大多数情况下,由于Ajax本身的异步机制,这些时间消耗并不构成前端响应时间的主要部分,因此在讨论web前端性能时,并不特别关注这部分时间。
注意⚠️:
Web应用的前端响应时间指浏览器的页面加载时间。
与服务性能不同,前端性能与兵法用户量的大小并无非常直接的关系
1.2.软件性能的几个专业术语
1.2.1响应时间
包含:前端响应时间,服务端响应时间,用户响应时间
服务端响应时间:应用系统从请求发出开始到客户端接收到最后一个字节所消耗的时间
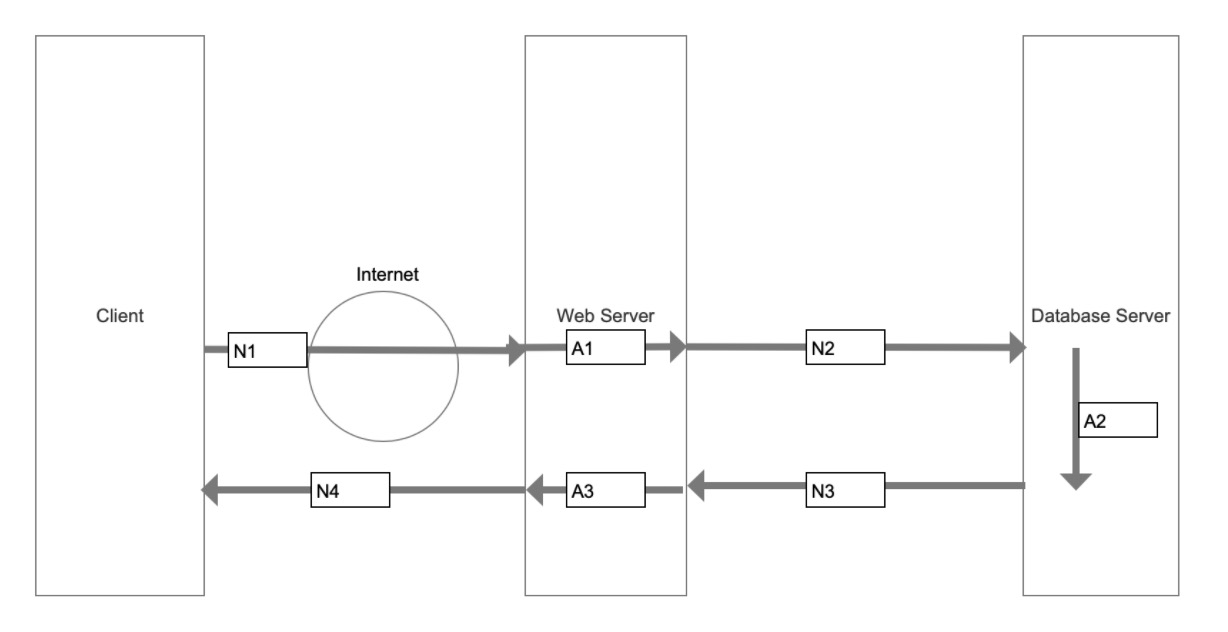
页面响应时间包括:
网络传输时间:(N1+N2+N3+N4)
应用延迟时间:(A1+A2+A3)
其中,应用延迟时间包括:数据库延迟时间(A2)和应用服务延迟时间(A1+A2)
注意⚠️:在进行性能测试时,合理的响应时间取决于实际的用户需求,而不能依据测试人员的设想来决定。
1.2.2用户并发数
业务并发用户数:在一个相当长的时间里,如果所有用户操作没有遇到性能阻碍,则可以说,该系统能够承受该数量的用户并发数;
服务并发数:在整个系统运行中,把系统运行划分成多个离散点,在每个离散点上,都有一个同时向服务端发送请求的客户数,如果能够找到运行过程中可能出现的服务最大可承受的并发访问数,则在该用户数下,服务器承受的压力最大,资源承受的压力最大,这种情况下可以通过并发测试发现系统中存在的并发引起的资源争用等问题。
估算并发用户数的公式:
C = nL / T (1-1)
^C ≈ C + 3√C (1-2)
在式(1-1)中,C是平均并发用户数,n是(用户从登陆进入系统到推出系统之间的时间段)的数量;L是(用户从登陆进入系统到推出系统之间的时间段)的平均长度:T指考察的时间段长度。例如,对一个典型的OA应用,考察的时间段长度应该为8个小时。
在式(1-2)则给出了并发用户数峰值的计算方式,其中,^C指并发用户数的峰值;C是式(1-1)中得到平均并发用户数。该公式是假设用户的(用户从登陆进入系统到推出系统之间的时间段)产生符合泊松分布而得到的。
泊松分布就是描述某段时间内,事件具体的发生概率。
实例:假设有一个OA系统,该系统有3000个用户,平均每天大约有400个用户要访问该系统,对一个典型用户来说,一天只在8小时内使用该系统,且从登陆到退出该系统的平均时间为4小时。
则根据(1-1)和(1-2),可以得到:
C = 400 x 4/8 = 200
^C ≈ 200+ 3√200 = 242
例如,如果能够知道平均每个用户发出的请求数(假设u),则系统的总吞吐量可估算为u*C
精准的计算得到并发用户数的方法
1.以更细的时间粒度,进行考察
2.考虑典型的业务场景
考虑安装AWStats(日志观察工具)
1.2.3吞吐量
吞吐量:直接体现软件系统的承载能力,是指单位时间内系统处理的客户请求数量。
吞吐量的重要性:
对于交互式应用,用户直接的体验是‘响应时间’,通过‘并发用户数’和‘响应时间’可以确定系统的性能测试规划;但是对于非交互式应用,用'吞吐量'来描述用户对于系统的期望更加合理。
对于交互式应用来说,吞吐量指标反映的是服务承受的压力。在容量规划的测试中,吞吐量是一个重点关注的指标,因为他能够说明系统级别负载的能力。
针对性地对吞吐量设计测试,有助于尽快定位到性能测试瓶颈所在的位置。
延伸:在大部分性能测试工具的统计中,单击数(Hits)是指客户端发出的http请求的数量
作为性能测试时的主要关注指标,吞吐量和并发数之间存在一定的联系,在没有遇到性能瓶颈时,吞吐量可以采用如下公式计算:
F = N(VU)*R / T
其中,F表示吞吐量;N(VU)表示VU(虚拟用户)的个数;R表示每个VU发出的请求(单击)数量;T表示性能测试所需要的时间。但如果遇到了性能测试瓶颈,吞吐量和VU就不再符合公式给出的关系。
注意⚠️:吞吐量的瓶颈必须依据实际业务情况,其中:
并发用户数需要真实的用户个数
并发持续时间需要实际活动时长
这些都会影响到最终的性能测试瓶颈定位
例如:
对同一个应用进行2次不同的性能测试,测试A采用100个并发,每个VU间隔1秒发出一个请求;测试B采用1000个并发,每个VU间隔10秒发出一个请求。对于测试A的吞吐量(pages/sec)为1001/1 = 100;对于测试B,吞吐量(pages/sec)为10001/10 = 100,二者相同。但是从测试结果上来看,执行测试A时,应用在50pages/sec出现性能瓶颈,而测试B则在25pages/sec出现瓶颈。
问题:
1.为什么同一个应用,吞吐量相同的情况下,测试出来两种性能瓶颈?
2.为什么输出的2种性能瓶颈,关系是测试A = 2*测试B
3.那个性能瓶颈是真实的性能瓶颈?
举例说明:用户数是一堵墙上的砖头,时间是我们从开始抽砖头到最终抽完的耗时。我们是从下面开始抽出来砖头,用户数越大,我们越是难以抽出砖头,约定的时间很难完成。这种难易程度就可以抽象成性能的瓶颈
1.2.4性能计数器(资源利用率)
性能计数器:是描述服务器或操作系统性能的一些数据指标。
性能计数器的作用:
计数器在性能测试中发挥着监控和分析的的关键作用,尤其是在分析系统的可拓展性,进行性能瓶颈定位时,对计数器去值得分析非常关键。
注意⚠️:单一计数器只能体现系统的某一个方面,对性能测试结果的分析必须是基于多个不同的计数器。
在性能测试中常用资源利用率进行横向的对比,例如,在进行测试时发现,资源A的使用率接近100%,而其他资源的使用率都处于比较低的水平,则可以很清楚的知道,资源A很可能是系统的一个性能瓶颈。当然,资源利用率在更通常的情况下需要结合响应时间变化曲线,系统负载曲线等各种指标进行分析。
1.2.5思考时间(休眠时间)
思考时间:从业务的角度来说,该时间指的是用户在进行操作时,每个请求之间的间隔时间。从测试的角度,在测试脚本中,思考时间体现为脚本中两个请求语句之间的间隔时间
其实,思考时间与迭代次数,并发用户数和吞吐量之间存在一定的关系。吞吐量是VU数量N(VU),每个用户发出请求数R和时间T的函数,其中的R又可以用时间T和用户的思考时间T(s):
R = T / T(s)
吞吐量与N(VU)成正比,与T(s)成反比。
注意⚠️:计算思考时间的一般方法:
1.首先计算出系统的并发用户数
2.统计数系统平均的吞吐量
3.统计出平均每用户发出的请求数量
4.依据以上的公式计算思考时间
‘0思考时间’:从业务的角度上考虑,思考时间用于更加真实的模拟用户操作,设置思考时间为0,基本上不具有实际的业务含义,这时是模拟一种尽可能大的压力,一研究系统在巨大的压力下的表现
如果了解系统在压力下的性能水平或系统承受压力的能力。
1.3.软件性能测试方法论
1.3.1 SEI负载测试计划过程
SEI负载测试计划过程是一个关注于负载测试计划的方法,其目标是产生清晰、易理解、可验证的负载测试计划。SEI负载测试计划过程中包括6个关注的区域:目标、用户、用例、生产环境、测试环境和测试场景。
SEI负载测试计划过程将上述6个区域作为负载测试计划需要重点关注和考虑的内容,其重点关注以下几个方面的内容:
1.生产环境和测试环境的不同
由于负载测试环境和实际的生产环境存在一定的差异,因此,在测试环境上对应用系统进行的负载测试结果很可能不能准确反映该应用系统在生产环境上世纪性能表现,为了规避这个风险,必须仔细设计测试环境。
2.用户分析
用户是对被测应用系统性能表现最关注和受影响最大的对象,因此,必须通过对用户行为的分析,依据用户行为模型建立用例和场景。
3.用例
用例是用户使用某种顺序和操作方式对业务过程进行实现的过程,对负载测试来说,用例的作用主要在于分析和分解出关键的业务,判断每个业务发生的频度、业务出现性能问题的风险等。
1.3.2 RBI方法
RBI方法是Empirix公司提出的一种用于快速识别系统性能瓶颈的方法。该方法基于以下一些事实:
(1)发现的80%系统的性能瓶颈都是由吞吐量制约。
(2)并发用户数和吞吐量瓶颈之间存在一定的关联。
(3)采用吞吐量测试可以更快速地定位问题。
RBI方法首先访问服务器上的‘小页面’和‘简单应用’,从应用服务器、网络等基础的层次上去了解系统吞吐量表现;其次选择不同的场景,设定不同的用户并发数,使其吞吐量保持基本一致的增长趋势,通过不断增加并发用户数和吞吐量,观察系统的性能表现。
在确定具体的性能瓶颈时,RBI将性能瓶颈的定位按照一种'自上而下‘的分析方式进行分析,首先确定是由吞吐量引发的性能表现限制,然后从网络、数据库、应用服务器和代码本身4个环节确定系统性能具体的瓶颈.
1.3.3.性能下降曲线分析法
性能下降曲线世纪上是描述性能随着用户数的增加出现下降趋势的曲线。
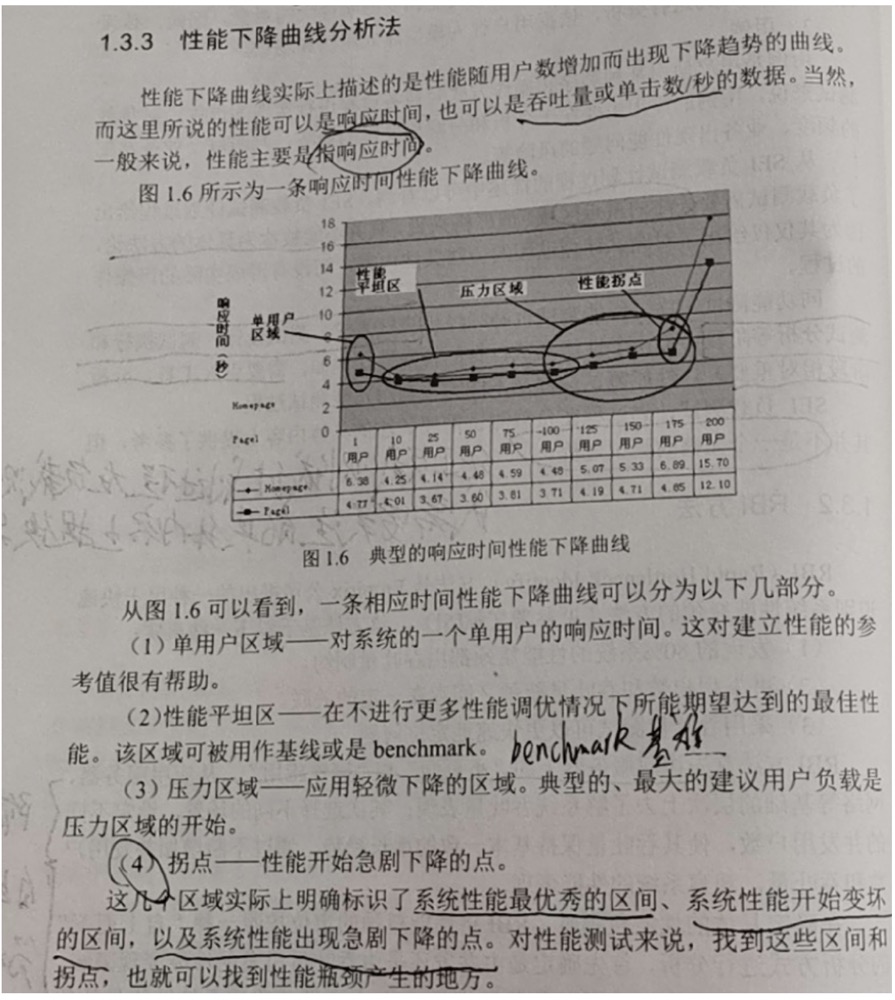
因此,对性能下降曲线分析法来说,主要关注的是性能下降曲线上的各个区间和相应的拐点,通过识别不同的区间和拐点,为性能瓶颈识别和性能调优提供依据。
1.3.4LoadRunner的性能测试过程
LoadRunner性能测试过程分为测试计划、测试设计、创建VU脚本、运行测试场景和分析结果6个步骤。
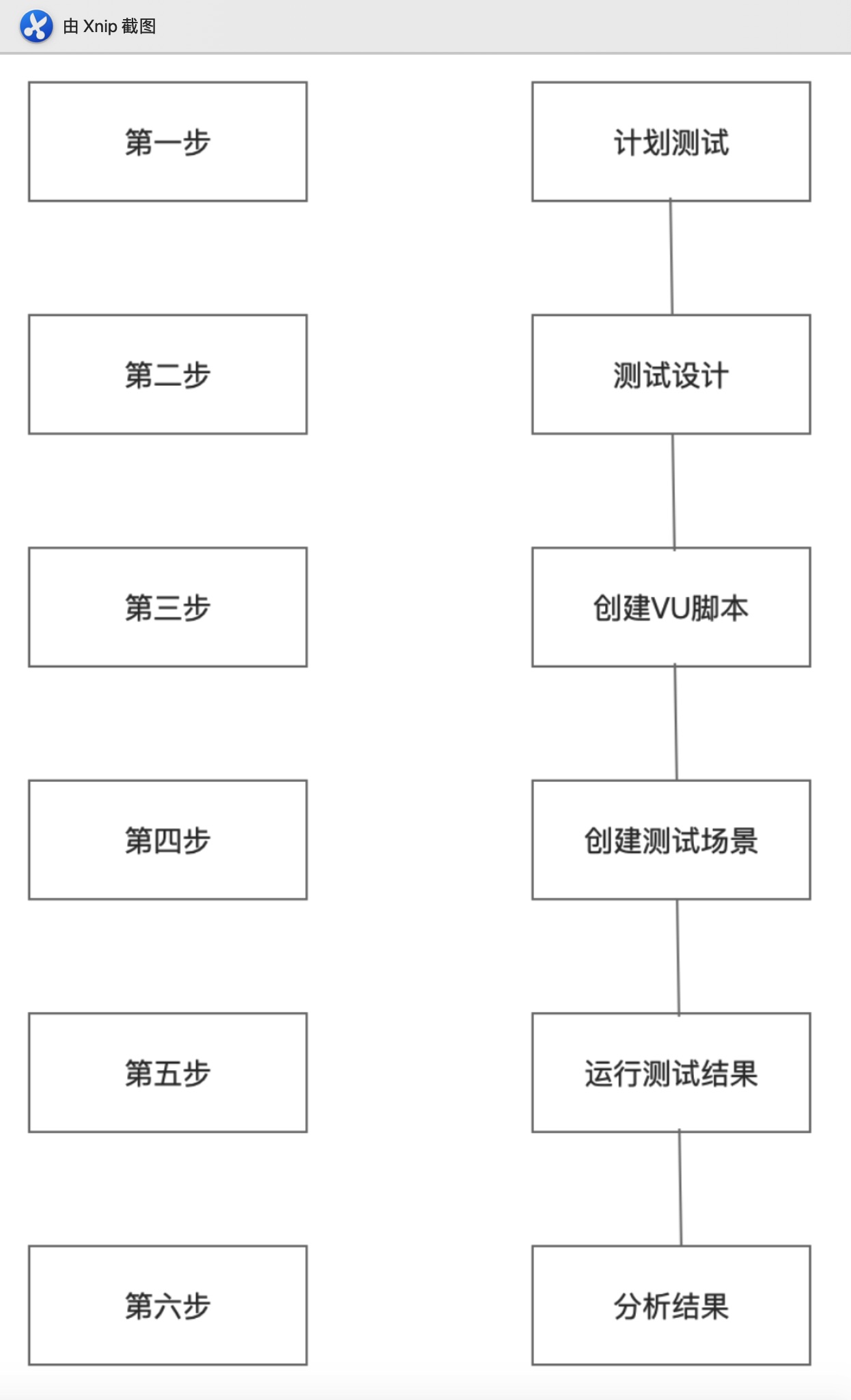
计划测试阶段:进行测试需求收集、典型场景的确定;
测试设计阶段:主要进行测试用例设计;
创建VU脚本阶段:主要根据设计的用例创建脚本;
创建测试场景阶段:主要进行测试场景的设计和设置;包括监控指标的设定;
运行测试场景阶段:主要对一创建的测试场景进行执行,收集响应数据;
分析结果阶段:主要进行结果的分析和报告工作。
1.3.5 Segue的性能测试
Segue的性能测试过程是一个不断try-check的过程。

1.3.6 敏捷性能测试
敏捷性能测试包含以下特点:
1.每个迭代目标中包含明确的性能目标
敏捷开发中性能测试和其他类型测试一样,需要以迭代为单位组织和管理性能测试,因此需要再每个迭代目标中明确定义迭代结束时可被验证的性能目标。由于一个迭代交付的产品并不一定具有完备的功能,因此在迭代目标中包含的性能目标并非完全建立在端到端响应时间上。
迭代目标中的性能目标可能是基于端到端的,也可能是基于接口的,甚至可能是面向具体的函数的。以下都是在迭代周期中可接受的性能描述:
=>在吞吐量为40QPS的情况下,X页面的服务响应时间小于5秒。
=>模块B能够每秒处理来自模块A的1000个请求
=>Employee从服务端获取给定employee信息的方法耗时不超过100毫秒
只有确定了每个迭代的性能目标,才有可能在每个迭代中安排合理的性能测试。需要采用相同的方式对迭代中的性能目标进行管理。
2.建立不同层次的性能测试
迭代目标中性能测试具有不同层次。这些性能目标可能是端到端,也可能是基于接口的,还可能是面向具体函数的。敏捷测试中可以使用不同的方法进行验证。
与单元测试一样,函数级别的性能测试对环境依赖性较小,对其他模块函数也不存在较强的依赖性,因此可以很容易地放置在持续集成中与其他单元测试一起运行。
接口级别的性能测试则需要较多环境的支持,一般来说,接口级别的性能测试至少要求将模块或子系统运行起来,并设置好测试的支持环境。
端到端性能测试需要更复杂的环境支持。考虑到端到端的性能测试结果与所在的环境存在极大的依赖性,这个层次的性能测试需要在严格定义的测试环境上运行。因此,通常需要为被测应用准备好‘一键部署’的脚本,只要通过一个命令行就能够将被测应用部署到制定环境上,然后使用合适的工具和脚本对其进行性能测试。
3.完全活接近完全自动化的性能测试
敏捷测试极大的依赖于自动化测试,每个迭代中组织的性能测试,同样需要依赖自动化测试来达成。
性能测试中的自动化包括两个部分:性能测试工具与脚本,以及用于设置环境的脚本。市面上有很多商业和开源的性能测试工具,例如:LoadeRunner工具,JMeter工具,JUnit工具等。但是这些工具往往都不能直接帮助设置性能测试需要的环境,不能基于某个基线进行结果的比较。如果要在敏捷的性能测试中实现高度自动化,还需要其他自动化工具(如部署工具等)的支持。
4.使用测试驱动方法保证性能与优化性能
测试驱动开发(TDD)促使开发工程师在实现代码之前准确定义代码功能,并通过这个准则避免开发工程师增加不必要的功能。
实际上,TDD方法同样适用于敏捷中的性能测试。如果有明确的针对函数的性能标准,该标准,同样可以背包含在测试中,并作为函数实现与否的一个判定辨准。
除了可以在函数级的性能测试中建立标准外,在更高层面简历持续的性能测试标准也是一个可用的实践。由于敏捷方法中需求变动比较频繁,难易建立一个确定的,持久的性能接受性标准。
对于没有明确定义性能标准的关键性能点,‘不低于上一个版本的性能表现’可以作为默认的性能约束,从而包含在每个迭代的验收标准中,甚至可以被放在持续集成或代码提交的标准中,以决定某个CL(Change List)是否可以被提交。
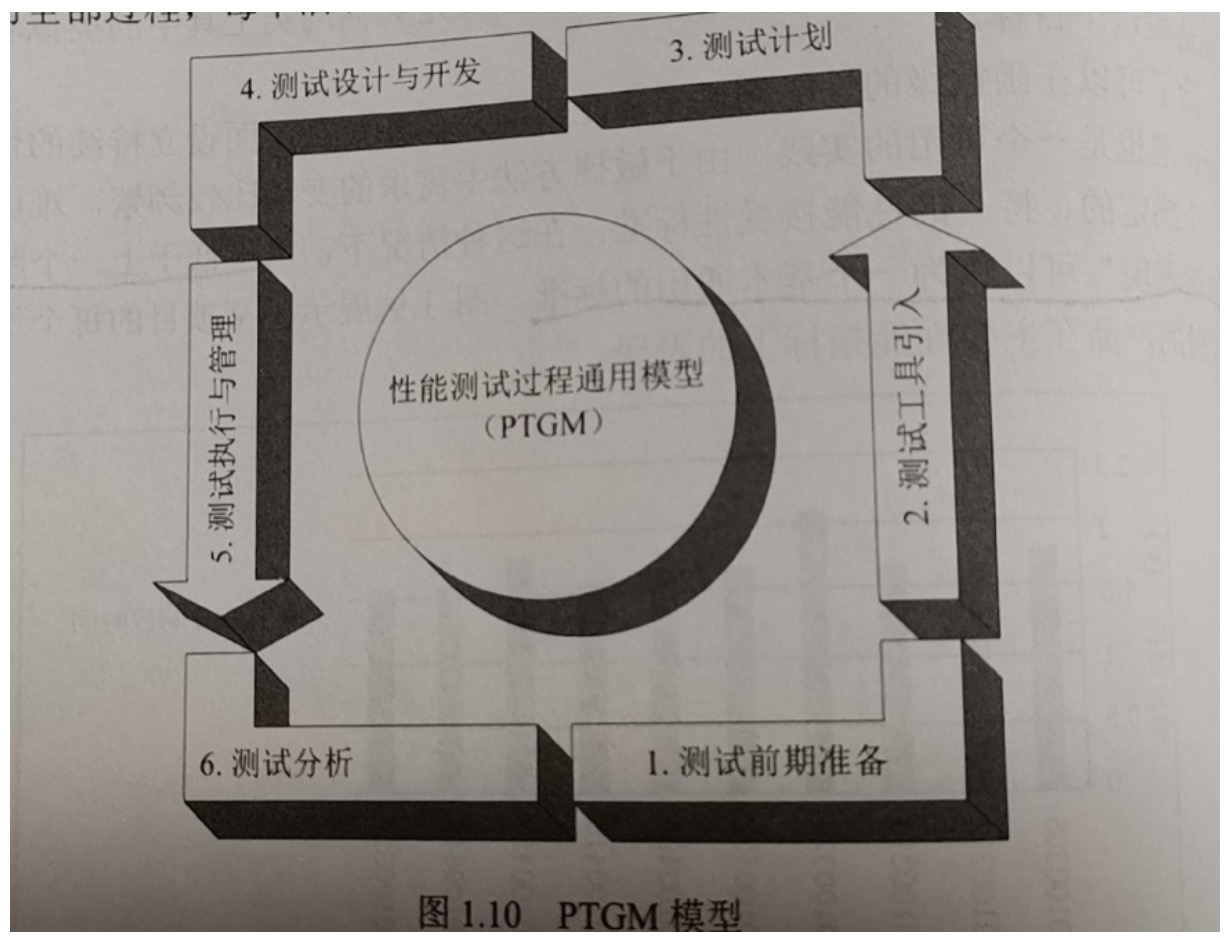
1.3.7.本书提供的性能测试模型
非敏捷测试模型