Elasticsearch中的相似度模型(原文:Similarity in Elasticsearch)
原文链接:https://www.elastic.co/blog/found-similarity-in-elasticsearch
原文 By Konrad Beiske
翻译 By 高家宝
译者按
该文虽然名为Elasticsearch中的相似度模型,实际上多数篇幅讲的都是信息检索邻域的通用相似度模型。其中涉及到具体实现的部分,Elasticsearch中相似度实际上是Lucene实现的,因此对于Lucene和Solr的开发者也具有参考意义。
导读
Elasticsearch当前支持替换默认的相似度模型。在本文中我们介绍什么是相似度模型并具体讲解tf-idf和bm25模型。
相似度模型简介
相似度模型是定义了相似度的抽象和度量。当然这是广义的定义。在这篇文章中我们只关注文本相似度模型。在此前提下:相似度模型可以分成两类:文档分类,将文档划分到已知有限类集合中的某一类;信息检索,找到和给定查询最相关的文档。在这篇文章中我们关注的是后者。
Elasticsearch提供了以下相似度模型:默认的tf-idf模型、bm25、drf和ib。我们暂时只关注默认模型和bm25模型。概率相似度和基于信息的相似度的区别可能会在以后的文章中讲解。
默认相似度模型
Elasticsearch中的默认相似度模型是tf/idf模型。tf/idf模型是最常见的向量空间模型(vsm)。在向量空间模型中每个查询词被看成是向量空间中的一个维度。因此可以将查询和文档看成是两个独立的向量。这两个向量的点积(scalar product)代表了文档和查询的相似度。这意味着文档中词的位置信息没有被使用,一个文档仅仅被看成一个词袋(a bag of words)。
一个简单的vsm模型的文档向量根据文档是否包含一个词将这个词对应的维度设成1或0。在不考虑查询词权重的情况下,查询向量中所有词对应的维度都被设成1。在这种简单模型下,两个向量的点积就是两个向量中公共词的个数。在这种简单模型下,两个包含同样数量公共词的文档,一篇每个词只出现一次,另一篇每个词出现多次,这两篇文档会获得相同的得分。然而哪篇文档的主题和查询词会更接近呢?tf/idf中的tf部分帮助我们解决这个问题:tf指的是词项的频率(term frequency),解决方法就是使用词项的频率替代文档向量中简单的0或1。
最简单的计算tf的方法是将文档中出现某个词项的次数作为这个词项的tf。这种简单的方式会带来一个问题。假设一个查询是fire fox,两篇文档用tf表示分别是D1{15,0}和D2{5,5},使用查询Q{1,1}查询的时候,D1得分会是15,D2得分是10。有可能D1是一篇很长的关于火灾的文章而D2是一篇关于如何安装火狐浏览器的入门教程。你认为哪篇更贴近于查询呢?为了让包含更多查询词的文档获得较高的得分,if/idf使用log(tf)作为向量维度的值。如果你还记得数学课学过的知识的话,应该知道log(0)无限趋于负无穷,而log(1)=0。为了获得想要的效果,我们可以在log运算前先给tf+1,也就是log(tf+1)。使用自然对数进行计算,现在两篇文档的向量变成了D1{2.772588722239781,0}和D2{1.791759469228055,1.791759469228055},这样D1得分会是2.772588722239781而D2得分会是3.58351893845611。我们现在有了一个可以根据文档中所有词项频率评估文档相似度的模型。
tf-idf的另一个部分是IDF,逆文档频率(Inverse Document Frequency)。idf的定义是总的文档数/包含词项的文档数。idf用来处理在一种语言中一部分词比其他词出现频率更高的现象。事实上很多频繁出现的词被作为噪音。如果在每篇文档中都含有同一个词,那么这个词对选择文档能有什么帮助呢?你也许会说那么为什么不用停用词(stop words)呢?当然,Elasticsearch有停用词机制,然而使用停用词被证明有时可能会损失精确度,而且使用停用词不只是语言相关的,还是领域相关的。idf代表了一个词出现在文档中所代表的重要性。和tf相似,一般使用idf的log值。log所使用的基数是多少并不重要,重要的是它使得只有指数增长才能带来idf的实际增长。
为了避免除数为0,因此一般要在分数的分母处+1。在Lucene的TFIDFSimilarity中为了避免idf是负数一般还会在log外+1。

BM25
TF-IDF属于向量空间模型,而BM25属于概率模型,但是他们的公式可能并没有你想象的那么大差距。两种相似度模型都使用idf方法和tf方法的某种乘积来定义单个词项的权重,然后把和查询匹配的词项的权重相加作为整篇文档的分数。

如果你想更深入的了解BM25的理论基础,我推荐你阅读 The Probabilistic Relevance Framework: BM25 and Beyond.这篇文章我更侧重于讲解实践。
饱和度
tf-idf和bm25都默认对于高频率的词项来说,该词项的频率继续升高对相关性的影响实际很小。区别在于BM25在这一点上做的更好一些。在BM25中高频词接近饱和之后会渐进一个边界值,而在tf-idf中则没有边界值。在tf-idf中,将tf乘以log的底数将会持续的让log值+1.
增长曲线的不同意味着对于包括log基数在内固定的调节参数的任意值,你都可以在tf-idf中创建一个比bm25中tf分数更高的文档。
下面的公式描述了tf在BM25和tf-idf中的算分函数。
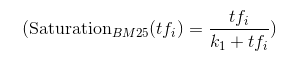

我们可以画出tf从0变化到100的时候,不同函数的变化情况。k1只取几个代表值。

看图的时候注意图中函数的绝对高度是无关的,因为可以简单的用加权因子(boost factor)调节。有趣的是每条曲线的相对增长。有两点需要注意:首先,可以看到log函数没有上边界,其次,k1取到1.2~2.0时函数变化很微小。后者可以说明当你不了解如何调节k1的值时,默认的值通常就可以满足要求。
平均文档长度
tf-idf和BM25之间第二点主要区别是BM25中对文档长度的使用。BM25使用文档长度来补偿长文档通常含有更多词从而在并不相关的情况下获取较高tf分数的情况。然后长文档并不一定是不好的,有些长文档覆盖了更广的范围因此是合理的。BM25通过因子B来做长度补偿,B通过一个调节参数b (0<=b<=1)、文档长度dl和平均文档长度avdl来计算,如下:
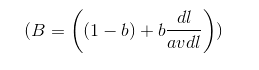
通过定义(tf_{adjusted} = tf * B) 并且把之前公式的 (tf) 替换为(tf_{adjusted}) ,我们可以得到:
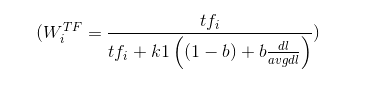
这就是BM25中tf的使用方式。
完整的词项权重
要获得BM25中词项的完整计算公式,我们需要要用 (W_{i}^{TF}) 乘上 (IDF_{i})。然而BM25中idf的定义和默认相似度稍有不同,这一点也反映到了Lucene中。公式如下:

D代表文档总数,di代表包含查询中第i个词项的文档数。
Lucene中BM25的实现
Lucene使用了BM25的一个变体,分子乘了一个 (\left(k_{1} + 1\right))。这是一个常用的技巧,使得公式和其他的排序方法更相似从而可以更方便的比较结果值。因为这个表达式是一个常量,因此它并不会影响排序的结果。

Lucene为了提高效率,这个公式并不是完全在查询时计算的。Lucene在索引和查询的时候都使用相似度模型。具体实现也取决于Elasticsearch。
BM25调优
关于调节参数,k1和b的定义肯定是有意义的。合理的参数值取决于文档数据。不幸的是,在调节参数这个事情上没有银弹(silver bullet),唯一的方法就是不断尝试和修正错误,但是调节参数的作用还是很大的,至少给我们调节文档和查询的相关性提供了一个途径。
结论
TF-IDF能够获得广泛的应用当然有其原因。它在概念上非常易于理解而且实际性能也算不错。这就是说,还有其它的强有力的替代者。典型地,它们能够提供更多的可调节参数。在这篇文章中我们深入讲解了他们中的一个,BM25。事实上,BM25一般被认为可能比tf-idf更好,特别是在短文档集上。不过不要忘了,文本相关性并不是Elasticsearch中排序的唯一因素。要实现好的搜索体验,关键是要基于需求场景综合文本相似性和源数据静态属性,例如文档的更新时间或是文档和查询者之间的特定关系。也可以继续阅读下一篇文章:BM25和Lucene Default Similarity比较。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号