
信息检索评价方法
测试数据集
- 一个文档集
- 一组用于测试的信息需求集合,信息需求可以表示为查询
- 一组相关性判定结果,对应每个查询-文档,通常会赋予一个二值判定结果: 相关/不相关
经验发现一般测试的查询数应>=50。
无序检索结果的评价
准确率和召回率
对于一个查询,根据其返回结果可以将整个文档集划分为4部分:
| 相关 | 不相关 | |
| 返回 | 真正例(tp) | 伪正例(fp) |
| 不返回 | 伪反例(fn) | 真反例(tn) |
定义:
准确率:P=tp/(tp+fp)
召回率:R=tp/(tp+fn)
准确率用来度量返回结果中是否带有不相关的结果。
召回率用来度量返回结果是否包含了所有相关文档。
F值
召回率和准确率很多时候是相互制衡的,返回的文档越多,一般召回率越高,但准确率随之下降。因此可以取召回率和准确率的调和平均值作为综合评价:
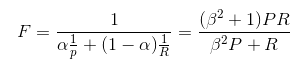
其中:

当beta取1时,召回率和准确率所占权重一致,公式简化为:

这里之所以取调和平均数而不是算数平均数或几何平均数是因为当两个求平均的数之间差距比较大的时候,相对于算数平均数和几何平均数,调和平均数更接近于较小的值,对于召回率和准确率来说这是合理的。
有序检索结果的评价
Map方法(mean average precision,平均正确率均值)
在结果有序的情况下,也可以沿用无序评价的正确率和召回率概念,方法是将搜索结果看成是前k个(k=1,2,...)搜索结果组成的若干子集,这样对每个子集都能计算正确率和召回率,然后可以将若干子集的评价取平均值。
假设搜索返回的结果文档集合为{d1,d2,d3...dm},则使用Map方法计算有序结果评价为:

P@k(precision at k)
上面提到的Map指标实际上是在所有召回率水平上计算准确率。对于Web搜索等应用来说,一般只关注第一页或前3页的结果,也就是说只关注前k个返回结果的准确率,P@k指只计算前k个返回结果的准确率。
R准确率
P@k指标有一个问题,比如将k指定为10,那么对于部分查询其相关文档数量可能<10,此时尽管查询返回了所有相关文档,但如果用10作为计算基底,仍然导致查询获得较低的准确率。
解决方法是将固定值k换成相关文档数R,R根据查询的不同而改变。这样求得的准确率称为R准确率。
根据召回率的定义可以得知,R准确率=查询结果的召回率。
R准确率和P@k准确率相比Map而言,实际上只是求了某一个召回率对应的准确率,尽管如此,但是在经验上却证实了R准确率和Map高度相关。
相关性判定
对于搜索结果的相关性,往往需要人工来判定,但是人工判定会存在一致性问题(同一个搜索结果,有的人认为相关,有的人认为不相关)。在社会科学中,一个常用的度量一致性的指标是kappa统计量:
kappa:
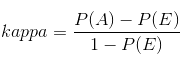
P(A)是观察到的一致性比率。P(E)是随机情况下的一致性比率。
kappa值>0说明人工判断的一致性>随机一致性,kappa=0说明和随机一致性相等,kappa<0说明还不如随机一致性。
一般来说kappa值>0.8说明具有很好的一致性:若取值在0.67~0.8之间,说明有较好的一致性,如果取值<0.67,说明结果值得怀疑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号