【转载】超越CNN的ViT模型及其应用前景
2022-01-04 10:59
©作者 | 苏菲
https://www.sohu.com/a/514179129_121277415
Transformer 模型在 NLP 领域获得了巨大的成功,以此为内核的超大规模预训练模型BERT、GPT-3 在 NLP 各个任务中都大放异彩,令人瞩目。
计算机视觉分析任务也借鉴了Transformer 模型的思想和方法,Meta公司的DETR模型中就使用 Transformer 和端到端方法实现了 CV 领域的目标检测任务,之后 Google 公司又推出了用纯粹的 Transformer 去完成计算机视觉任务的 ViT 模型。
本文首先比较 ViT 模型与传统计算机视觉模型 CNN 的不同,详细指出 ViT 模型的优点和好处,介绍了 ViT 模型的各种变体、扩展和应用前景。
01 超越 CNN
ViT 就是"Vi"加上"T",其中"Vi"是计算机视觉 Vision,而"T"就是 Transformer 模型。
ViT模型由 Goolge 团队在 ICLR2021 论文"An Image is Worth 16x16 Words:Transformers for ImageRecognition at Scale"( https://arxiv.org/abs/2010.11929 )提出,其目标是本着尽可能少修改的原则,将 Transformer 模型直接迁移到计算机视觉分类任务上。
论文认为没有必要依赖于传统的 CNN,直接用 Transformer 也能在分类任务中获得好的结果,尤其是在使用大规模训练集的条件下。
并且,在大规模数据集上预训练好的模型,迁移到中等数据集或小数据集任务时,也能取得比 CNN 更优的性能。
那么,ViT 模型与 CNN 相比,到底好在什么地方呢?具体来说,有以下六个方面的不同:
(1)从浅层和深层中获得的特征之间,ViT 有更多的相似性;
(2)ViT 表示从浅层获得全局特征;
(3)ViT 中的跳跃连接影响比 CNNs(ResNet)大,且大大地影响特征的表现和相似性;
(4)ViT 保留了比 ResNet 更多的空间信息;
(5)通过大量的数据,ViT 能学到高质量的中间特征;
(6)与 ResNet 相比,ViT 的表示是更接近于 MLP-Mixer。
1. 浅层和深层的表示更相似
如图1所示,图中显示了 ViT 模型的确切视窗,即自注意力机制(多头)的有效距离。
在浅层中,有一些带有局部视窗的头注意部分与 CNN 是相似的,但在深层的头注意部分则更多地使用了全局视窗。
与 ResNet 相比,ViT 与 ResNet 之间的一个不同就是初始层的更大视野。CNN 或者ResNet 仅有一个固定大小的核心卷积窗宽度(大小为 3 或者 7)。
CNNs 通过一层一层卷积,逐渐扩大卷积视窗的信息;而 ViT 模型即使在最低层,也可以通过自注意力机制允许模型有更大的视窗。
因此,图像可视化窗口的不同或大小是依赖于网络结构模型的,即在 CNNs 模型中视窗信息是逐渐变大的,而 ViT 模型结构中即使低层也能有很大的视野。
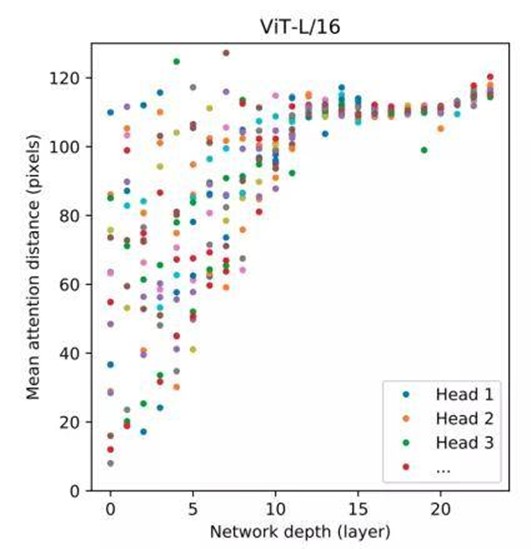
图 1
2.在浅层获得全局特征信息
图2给出了 ViT 模型的自注意力机制有效距离(即来自 5000 个数据样本的自注意机制的平均距离)。
ViT 模型使用谷歌自己的超大规模数据集 JFT-300M(约 3 亿数据图片) 进行了预训练,ViT-L/16 为大模型(3.07 亿参数),ViT-H/14 为巨大模型(6.32 亿参数), 然后用 ImageNet (约 1300 万图片) 进行了微调(fine-tuning)。
从图中可以看到,在浅层(编码为block0、block1)中,模型逐渐获得了局部和全局的特征。然而,在深层(编码为 block22、block23、block30、block31)中,从一开始模型就是获得了全局视野的特征。

图 2
但是,由于训练ViT模型需要超大规模的数据(约3亿张图片),如果数据训练量小,那么精确度就会下降。
图3显示了这种数量训练量小的对比结果,可以看到对于更少的训练数据,模型中更低的自注意力机制层确实没有在局部进行学习关注。
也就是说,仅仅在 ImageNet 数据集上进行训练,会导致低层的自注意力机制也不学习局部信息,从而导致了模型精度的下降。

图 3
3.跳跃连接在 ViT 模型中的影响更大
如果网络中一个层的跳跃连接(skip connection)被删除,那么这个层所获得的特征表示与原来所获得的相比会有很大的不同。
换句话说,跳跃连接对特征表示的传播有着巨大的影响,如果被删除的话将会大大改变这个层的特征表示学习能力。
在某些情况下,如果中间层的跳跃连接被删除,那么模型的准确率大约会下降 4%。
虽然论文中没有特别提及这一点,但是跳跃连接在特征信息传播中起到了主要作用这一事实,可能导致当中间层中的跳跃连接被删除时,精度显著会下降。
因此,在ViT模型中,跳跃连接对模型的影响比 CNNs(ResNet)更大,而且大大地影响表示(特征)的获得与传播。
4.ViT 保留了比 ResNet 更多的空间信息
有些论文测试了 ViT 和 ResNet 所保留的位置信息。通过对比输入图像某个位置块和最终层特征图的 CKA 相似程度,可以知道图像被保留的位置信息。
如果模型保留了位置的信息,那么在某个位置的输入图像块与相应位置的特征图的相似度应当最高。
实验表明,在 ViT 模型中输入图像与最后一层的特征图在相应位置的相似性非常高。这表明 ViT 在特征信息传播的同时还保留了位置信息。
而在 ResNet 模型中,不相关位置的特征图相似性更高,这表明 ResNet 模型没有很好地保留位置信息。这种位置信息上的差异可能源于模型内部网络结构的不同。
5.ViT 能学习到高质量的中间特征
 图 4
图 4
在如图4所示的实验中,作者使用一个简单线性模型来区分中间层特征表示学习的质量: 如果一个简单模型(例如线性模型)在中间层表示中能获得更高的准确率,那么这个中间层就能获得更好的学习特征。
在图4左边的实验结果图中,在 ImageNet 数据集上用一个简单的线性模型进行测试,虚线是在ImageNet 数据(包含了130万张图片)中进行预训练后的模型的实验结果,实线是在JFT-300M(3亿张图片)中进行预训练后的模型的实验结果。
从实验结果图中可以看到,在超大规模数据集 JFT-300M 上的模型准确率要高于在小数据集上的准确率。
在图4右边的实验结果图中,是 ViT 模型(实线)和 ResNet 模型(虚线)在相同数据集(JFT-300M)进行预训练后的比较,也使用了一个简单线性模型在 ImageNet 数据集中进行测试。
同样, ViT模型获得了比 ResNet 模型更好的中间层的特征学习结果。
6.MLP-Mixer 的表示更接近于 ViT
最近,与使用 Transformer 不同,一些准确率高的图像识别模型使用了多层感知机(MLP),例如由Tolstikhin 等人 2021年提出的多层感知机混合模型(MLP-Mixer),它使用第一个感知机MLP1混合了图像块之间的信息,又使用第二个感知机MLP2混合了图像块之间的信息,然后通过这些信息块的叠加来组合这两种信息。
这种多层感知机混合模型 MLP-Mixer 可以达到像 ViT 模型一样或者更高的准确率。
MLP-Mixer 把图像分割成不同块的方式与 ViT 模型非常相似,因此它在结构上比 ResNet 更接近于 ViT 模型。
或许正是这种结构上的原因导致了不同模型在计算机视觉任务上结果的相似与不同。
02 应用前景分析
ViT模型是在计算机视觉任务中应用Transformer模型的一个结果,2020年10月由Dosovitskiy等人提出并应用于图像分类任务。
其模型架构几乎与自然语言处理机器翻译任务中的原始 Transformer 模型一模一样, 它所做的拓展是允许图像作为 Transformer 的输入,把图像分成一个个块(patch),然后通过位置编号按顺序存储起来,可以把一个 patch 看成 是自然语言中的一个词语, 因此与自然语言处理的 Transformer 模型有异曲同工之妙。
在 ViT 之后,一些可能的研究方向或者模型也被众多公司或学者推进或者扩展,在计算机视觉的物体检测、语义分割等其他应用上大放异彩。例如:
(1)DeiT:在合理的规模内训练 ViT 模型,使用知识蒸馏、自蒸馏等硬标签蒸馏方式,可以在100万张ImageNet图片规模的数据上训练 ViT 蒸馏模型。
(2)PyramidVision Transformer:通过可变的空间缩减注意力机制实现了一种可变的自注意力机制,并应用于 ViT 模型以克服注意力机制中的平方复杂度。
(3 )Swin Transformer:使用了滑动窗口的层次化的视觉 Transformer 模型,基于 Transformer 的位置或窗口注意机制对不重叠的窗口应用局部自注意力机制,从而在下一层级中形成了层次化的特征表示并最终进行融合。
(4)DINO:Meta 公司的 AI 团队提出的基于视觉 Transformer 的自监督训练框架,可以在大规模无标注数据上进行训练,甚至不需要一个微调的线性层也可以获得鲁棒性的特征表示。
(5)Scaling ViT:更大规模的 ViT 模型,谷歌大脑团队对 ViT 模型进行了规模上的扩展,使用了 20 亿参数模型的 ViT 模型在 ImageNet 的识别结果排名上获得了第一名。
(6)SegFormer:计算机视觉任务的语义分割中应用了 ViT 模型,由英伟达公司提出的关注系统的组件化,且不需要位置编码,而是采用了一个简单的 MLP 解码模型。
(7)Unet + ViT = UNETR :Vision Transformers 在医学上的应用,ViT 模型被用于三维医学图像的语义分割任务。与 Unet 模型类似,致力于有效地捕捉全局的多尺度信息,并能够使用长跳跃连接传递到解码器中。
03 结论
自从 ViT 诞生以来,许多新的模型和应用被挖掘出来,推动计算机影像识别到达了一个新的水平,在许多方向和任务上可以应用 ViT 模型上并改进。
例如寻找新的自注意力模块的 XCIT 、寻找新的来自于 NLP 的新模块组合的 PVT 和 SWIN、寻找深度无监督或自监督学习的 DINO、在新领域或新任务中应用适应性的 ViT 的 SegFormer 和 UNETR 等等。
总之, ViT 模型在计算机视觉领域的应用前景上,大有可为。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号