Docs > torch.nn > LSTM pytorch里使用LSTM
LSTM
CLASS torch.nn.LSTM(*args,**kwargs) [SOURCE]
对输入序列应用多层长短期记忆(LSTM) RNN。
对于输入序列中的每一个元素,每一层(layer)计算以下的函数值:
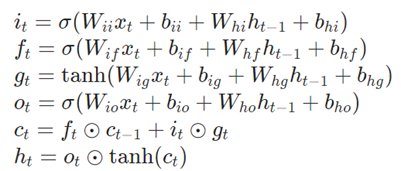
这里h_t是t时刻的hidden state,c_t是t时刻的cell state,x_t是t时刻的输入。
h_t-1是t-1时刻的hidden state,也是 o时刻的initial hidden state。i_t, f_t, g_t, o_t 分别是输入门,忘记门,cell,输出门。σ是sigmoid函数, ⊙是 Hadamard积。

在多层(multilayer)LSTM中,l层(l>=2)的输入x是l-1层的隐藏状态h乘以dropout δ ,δ 是一个伯努利随机变量,有一定概率为0。
 。因此,LSTM网络的输出也会有不同的形状。有关所有变量的精确尺寸,请参阅下面的输入/输出部分。详情请访问https://arxiv.org/abs/1402.1128。
。因此,LSTM网络的输出也会有不同的形状。有关所有变量的精确尺寸,请参阅下面的输入/输出部分。详情请访问https://arxiv.org/abs/1402.1128。


在一些版本的cuDNN和CUDA上,RNN函数存在已知的不确定性问题。您可以通过设置以下环境变量来强制执行确定性行为:
On CUDA 10.1, 设置环境变量CUDA_LAUNCH_BLOCKING=1。这可能会影响性能。
See the cuDNN 8 Release Notes for more information.
Orphan
NOTE
如果满足以下条件:
1)cudnn开启 2)输入数据在GPU上 3)输入数据有dtype torch.float16 4)使用V100 GPU
5)输入数据不是PackedSequence格式。
可以选择持久算法(persistent algorithm)来提高性能。
Examples:
rnn = nn.LSTM(10, 20, 2)
input = torch.randn(5, 3, 10)
h0 = torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
output, (hn, cn) = rnn(input, (h0, c0))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号