Python中面向对象的基本理论(二)
Python中面向对象的基本理论(二)
属性相关补充
私有化属性
通俗理解:访问范围大的属性限制成访问范围小的(类的内部的)属性
私有化属性的意义:保证数据的安全性
怎么做?
- 并没有真正的私有化,而是使用在变量前添加下划线进行伪私有。(适用于类属性和实例属性)
- 一个下划线:受保护的属性
- 两个下划线:私有属性
类的内部
子类的内部
模块内其他位置访问
跨模块访问
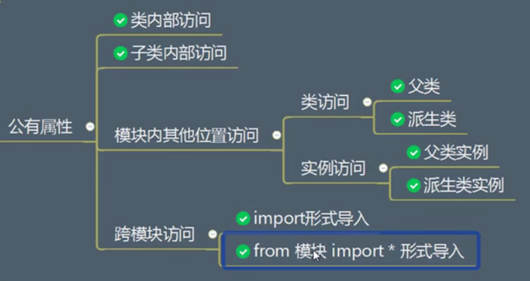
共有属性
可以访问
可以访问
可以访问
可以访问
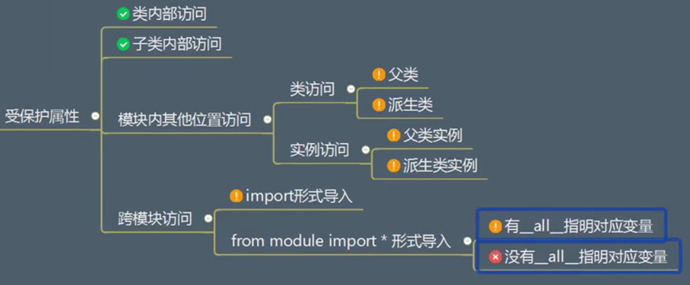
受保护的属性
可以访问
可以访问
可以访问,但是会警告
不能访问(警告/报错)
私有属性
可以访问
不能访问
不能访问
不能访问

私有化属性的实现机制:名字重整(Name Mangling)私有化之后,名字被重新修改了。(防止被外界调用,防止被子类中同名属性替代)(名字重整是由解释器自动完成的)
私有化属性的应用场景:数据保护;数据过滤(结合其他的方法完成)
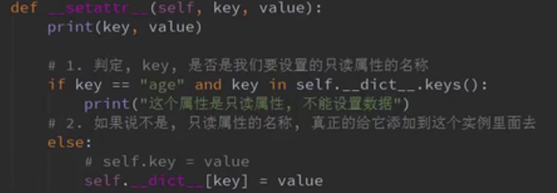
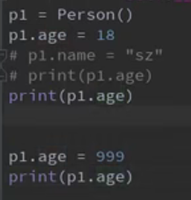
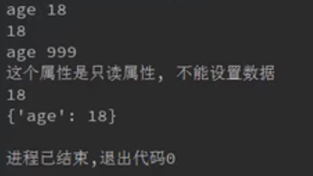
只读属性
应用场景:有些属性,只限在内部根据不同场景进行修改,对外界来说,不能修改,只能读取。
怎么设置?: 方案一:先私有化-->既不能读,也不能写;然后部分公开
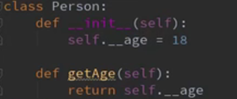
问题:读取属性的操作方式发生了变化,而且尝试给这个只读属性赋值时,可能会新建一个__age
装饰器@property解决了以上两个问题:(视频50-53)
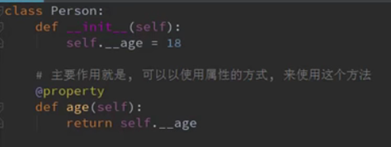
@property 将一些属性的操作方法,关联到某一个属性中

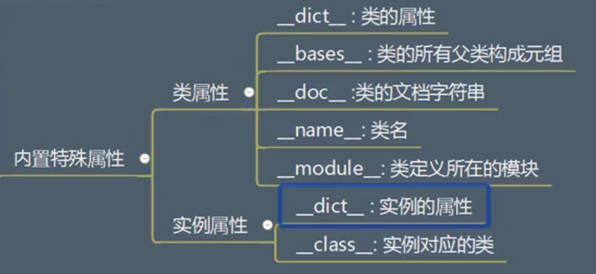
内置特殊属性
方法相关补充
私有化方法:和属性一样,def __run( )
内置特殊方法:

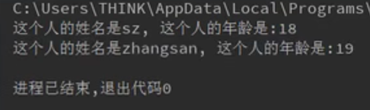
return "这个人的姓名是%s,年龄是%s"%(self.name , self.age)
print(P1) #直接print会默认调用__str__方法的返回值
如果定义了这个方法,要获取这个类型的本质信息(地址信息等),那么可以调用__repr__方法:
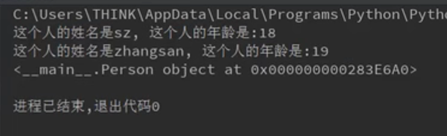
我们可以重新定义__repr__方法来重新编辑调试代码会用到的调试信息。
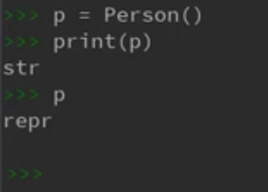
当一个类中同时定义了以上两种方法时,print(P1)会优先打印__str__中的内容。
当一个类中只定义了__repr__方法时,print会优先打印__repr__中的内容。
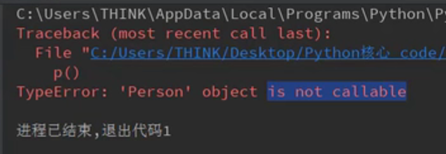
def __call__(self, *args , **kwargs):
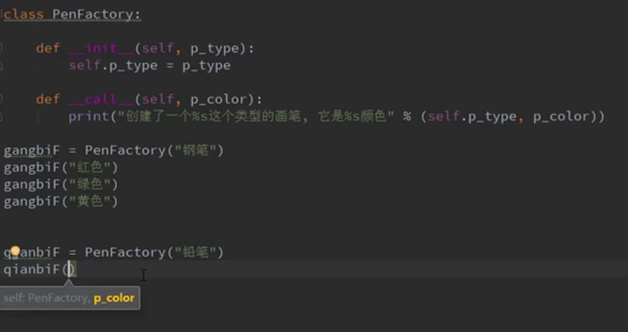
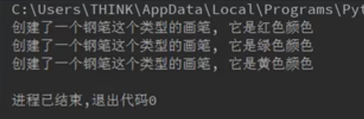 (不包含铅笔部分)
(不包含铅笔部分)
索引操作
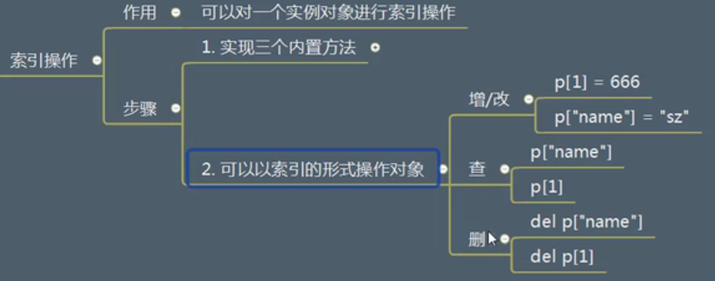
def __setitem__ (self , key , value ):
def __getitem__ (self , key ):
切片操作
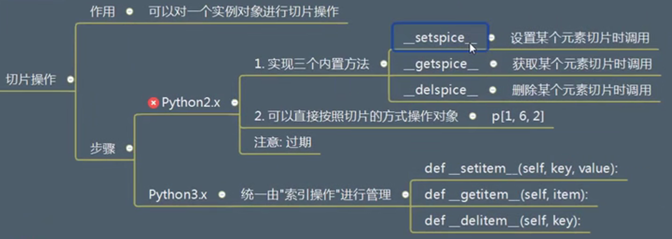
(https://www.bilibili.com/video/BV1A4411v7b2?p=63视频63)
比较操作(视频64-67)
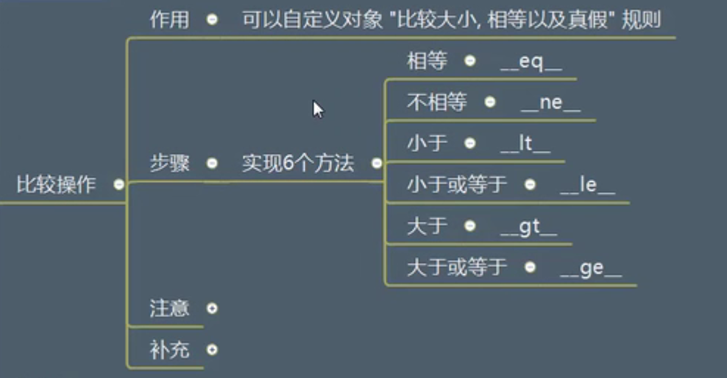
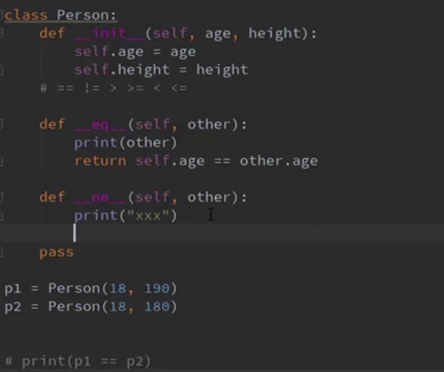
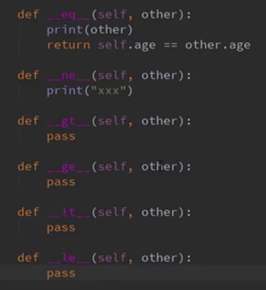
如果只定义了等于,要判断是不是不等于,这个时候解释器会自动映射到等于的方法,并取反。(同样适用于 > < 等,大于小于运算是调用参数位置,但是并不会对> = 采用叠加操作。定义了>和=并不能推算出>= 。)
这一点可以用装饰器解决(@functools.total_ordering)
上下文布尔值,可以根据判定条件生成类被调用时候的布尔值
def __bool__(self):
XXXXXX
return false
eg. return self.age >= 18

 浙公网安备 33010602011771号
浙公网安备 33010602011771号