《统计学习方法》 生成模型和判别模型
学习数据得到模型的方法分为两种:生成方法和判别方法。
生成模型:
由数据学习得到联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测模型,即生成模型(Generative Model):
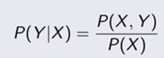
典型的生成模型:朴素贝叶斯、隐马尔可夫模型
注:输入和输出变量要求为随机变量。
判别模型:
由数据直接学习决策函数f(x)或者条件概率分布P(Y|X)作为预测模型,即判别模型(Discriminative Mosel)。
典型的判别模型:K近邻法、感知机、决策树等
注:不需要输入和输出变量均为随机变量
生成模型VS判别模型
生成模型:
- 所需数据量较大
- 可还原联合概率分布P(X,Y)
- 收敛速度更快
- 能反映同类数据本身的相似度
- 隐变量存在时,仍可用生成模型
判别模型:
- 所需样本的数量少于生成模型
- 可直接面对预测,准确率更高
- 可简化学习问题
- 不可以反映数据本身的特性
转载请注明出处。
有事请私信联系~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号