【课程笔记】CS224n深度自然语言处理(一)
第一节课是一个课程的介绍,没有涉及太多的知识方面的内容。
因为小艾已经有了很长时间的在NLP入门阶段跌跌撞撞了,所以对于为什么人类语言难以理解,已经有了比较深刻的认识,所以第一课没有做笔记,很快看完了,只留存了两张截图。

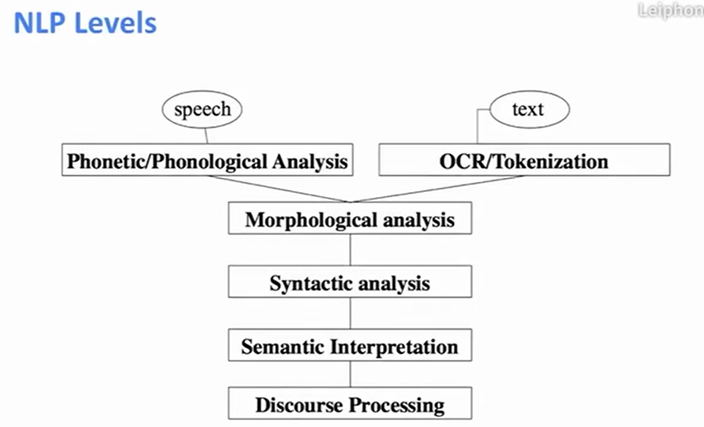
正式第一讲:Word Vector(Skip-Gram model)
这一讲主要讲了NLP研究的对象,我们如何表示单词的含义,以及Word2Vec方法的基本原理。
NLP——Natural Language Processing,其中Natural Language指的就是人类语言。人类可以用纸张上的抽象文字就能指代实际的物理事物以及其他抽象概念,在对话中能够凭借语境理解省略后极其简洁的文字。而想让机器理解人类的语言却是一项很复杂的任务,在这个方面,有很多有趣又实用的研究方向如Machine Translation(机器翻译),Semantic Analysis(语义分析),Question Answering(问答系统)等等。
在这些问题中,最基本的、最常见的一个问题就是:机器如何理解单词的含义。
在过去的研究中,语言学家曾经用概率的方法计算一句话中下一个要出现的词语是什么,运用机器学习的方法,让机器分析和处理大数据,去生成一个又一个的词语。这个方法针对分词、句子成分分析等有一定的效果,对于机器理解单词的含义贡献并不大。所以,针对这个问题,产生了WordNet。建立所有同义词synonym和下义词hypernym(即"is a"的关系)的词库,一个单词的含义就由它的同义词集合和下义词集合来定义。一定程度上,这可以解决机器理解单词含义的问题,但是,这一表示方法有很多问题,比如一个单词只在某些语境下和另一个词为同义词而其他语境下不是,词汇的新的含义很难包含进入词库,定义比较主观且需要较多人力整理,而且也很难量化两个词的相似程度。
学者们开始探索用向量来表示单词,一个简单的方法是我们用one-hot的向量来表示单词,即该单词对应所在元素为1,向量中其他元素均为0,而向量的维度就等于词库中的单词数目。
例如对六个状态进行编码:
自然顺序码为 000,001,010,011,100,101
独热编码则是 000001,000010,000100,001000,010000,100000
一个显然的问题是由于所有向量都是互相正交的,我们无法有效的表示两个向量间的相似度;并且向量维度过大,我们还是无法逃脱数据稀疏的问题。这两个问题将极大阻碍模型向我们期望的方向发展。
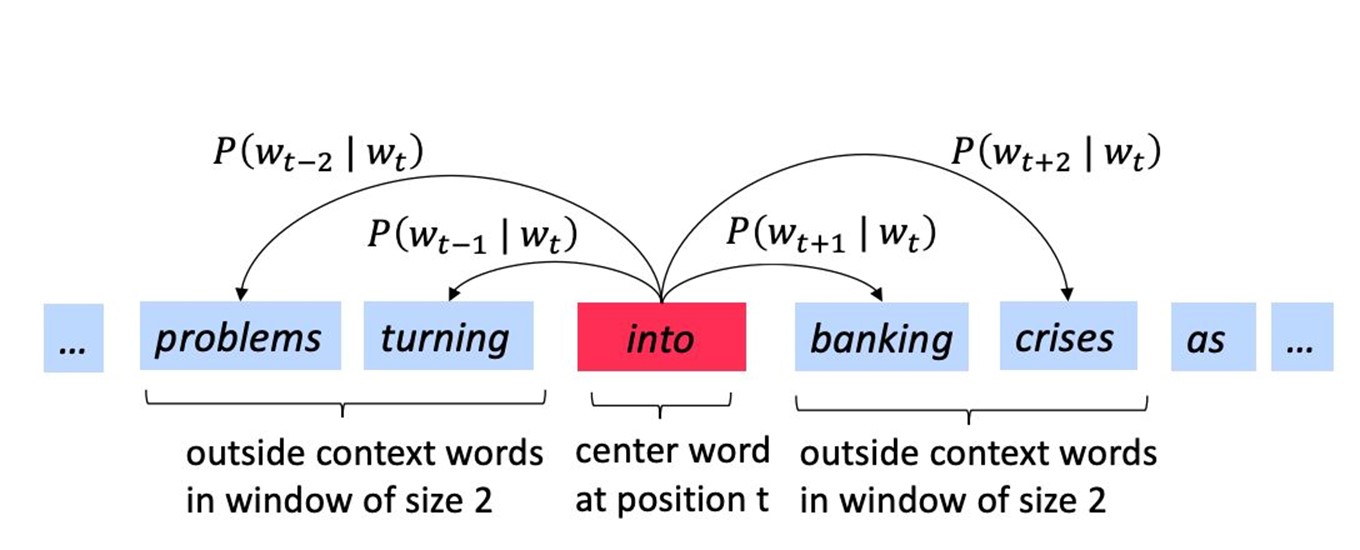
对此,语言学家们有一个敏锐的观察:一个单词的含义往往是由经常和它一起出现的附近的单词们决定的。(如果你也学习了NLP,想必你会很熟悉这句话)即我们定义一个以该词为中心的定长的窗口,窗口内的其他词构成了它的上下文context,而通过这些context我们可以建立对该词的有效的表示。如下图中banking附近常出现的词决定了banking的含义。

之前的one-hot vector是一种sparse vector(稀疏向量),我们想要构建的是dense vector(密集的向量)即大多数元素不为零且维度较小的向量,并且希望在相似的context下的word vector也较为相似。word vector就是为了解决这些问题而存在的,word vector也被称为word embedding 或是word representation。
我们要如何得到word vector呢?这一讲介绍的是一种早期较为流行的方法Word2Vec,由谷歌的NLP专家在2013年左右提出,其核心思想就是已知我们有了很大的文本库(corpus of text),当我们用固定窗口不断的扫过文本库的句子时,我们有位于中间的center word c及其周边的单词们context words o, 而它们的相似度可用给定c的情况下o的条件概率来表示,我们不断的调整word vector使得这个概率最大化。每个单词w可用两个向量表示,一个是它作为center word时的向量V以及它作为context word时的向量u。
如下图所示,就是窗口大小为2,center word为into的context word的概率表示。
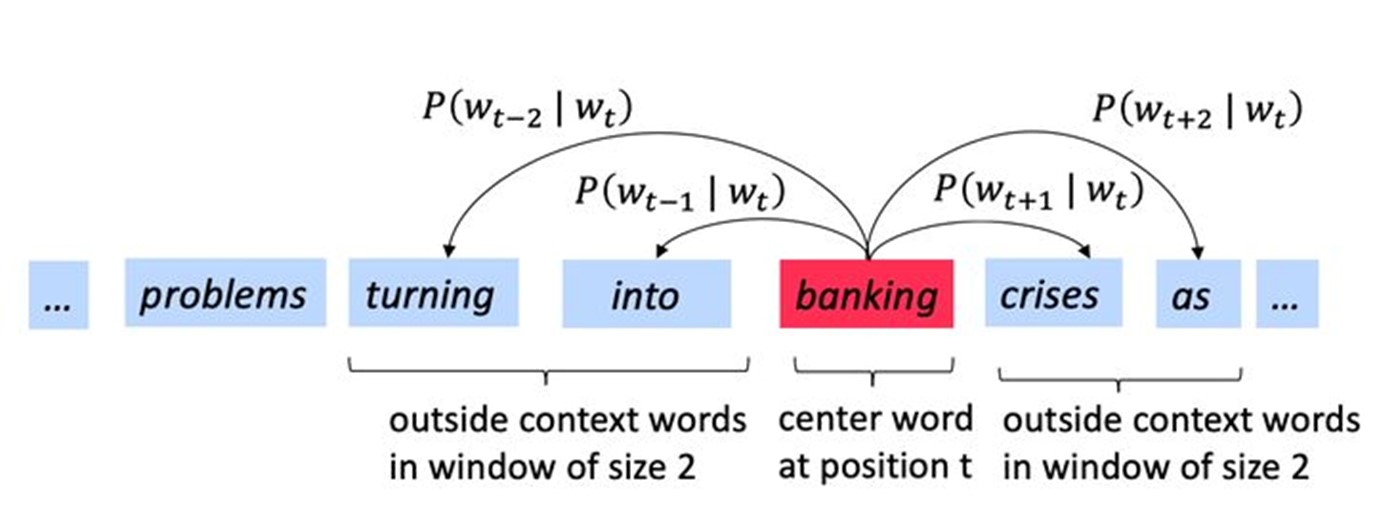
当我们扫到下一个位置时,banking就成为center word。
在word2vec中,条件概率写作context word与center word的点乘形式再对其做softmax运算,即
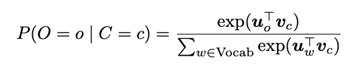
而整体的似然率就可以写成这些条件概率的联乘积形式:

而我们的目标函数或者损失函数就可以写作如下形式:
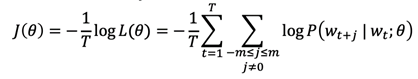
其中log形式是方便将联乘转化为求和,负号是希望将极大化似然率转化为极小化损失函数的等价问题。
有了目标函数以及每个条件概率的表现形式,我们就可以利用梯度下降算法来逐步求得使目标函数最小的word vector的形式了。关于梯度下降算法,可回顾这篇文章梯度下降算法——深度学习花书第四章数值计算,这里不再赘述。
在我们关注的是单词本身的含义的时候,我们就不必在意单词距离中心词的位置。单词所处的位置会对一些句法分析起到很好的效果,但是如果我们只关注单词本身的含义的话,大可不必关注他出现的位置。
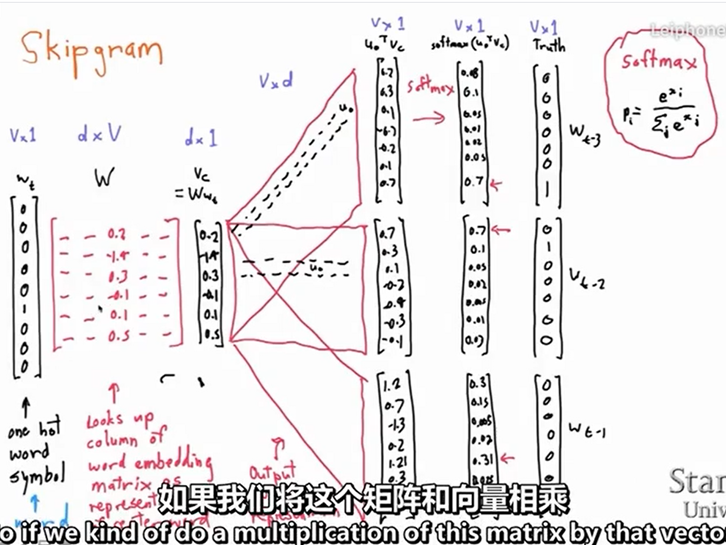

这里的word2vec算法又被叫做Skip-Gram model,还有另一种word2vec算法是Continuous Bag of Words,简称CBOW,它们的原理区别是Skip-Gram是求context word相对于center word的条件概率,而CBOW是求center相对于context word的条件概率,其他方面基本类似。
下一讲会继续深入的讲解word2vec的一些细节以及结合了word2vec及SVD思想的GloVe算法,to be continued。
转载改编自https://zhuanlan.zhihu.com/p/59016893

 浙公网安备 33010602011771号
浙公网安备 33010602011771号