背景
整个系列有相对完整的公式推导,若正文中有涉及到的省略部分,皆额外整理在Part4,并会在正文中会指明具体位置。
在Part2基于\(\text{Variational Inference}\),找到原目标函数\(-\ln{p_\theta(x_0)}\)的上界\(L\),定义如下:
\[\begin{aligned} L := & \mathbb{E}_q\left[-\log \frac{p\left(\mathbf{x}_T\right)}{q\left(\mathbf{x}_T \mid \mathbf{x}_0\right)}-\sum_{t>1} \log \frac{p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)}{q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right)}-\log p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)\right] \\ =& \mathbb{E}_q[\underbrace{D_{\mathrm{KL}}\left(q\left(\mathbf{x}_T \mid \mathbf{x}_0\right) \| p\left(\mathbf{x}_T\right)\right)}_{L_T}+\sum_{t>1} \underbrace{D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right) \| p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\right)}_{L_{t-1}} \underbrace{-\log p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}_{L_0}]\end{aligned}\tag{1}
\]
沿着论文的思路对\(L\)继续精简,得到最终在代码层面实现的损失函数\(L_{simple}\)。同样的,补充的推导见Part4;“扩散过程”的梗概介绍见Part1。
简化过程
不难看出\(L\)中的每一项皆为KL散度。回顾forward process与reverse process两个阶段的定义,马尔可夫链的状态转移皆服从高斯分布,如下所示:
\[\begin{aligned}
q\left(\mathbf{x}_t \mid \mathbf{x}_{t-1}\right) &:= \mathcal{N}\left(\mathbf{x}_t ; \sqrt{1-\beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I}\right) \\
p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)&:=\mathcal{N}\left(\mathbf{x}_{t-1} ; \boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right), \boldsymbol{\Sigma}_\theta\left(\mathbf{x}_t, t\right)\right)
\end{aligned}\tag{2}\]
同时,经过推导(见Part4推导二),易知:
\[\begin{aligned}
q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right) & =\mathcal{N}\left(\mathbf{x}_{t-1} ; \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right), \tilde{\beta}_t \mathbf{I}\right) \\ \text { where } \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right) & :=\frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1-\bar{\alpha}_t} \mathbf{x}_0+\frac{\sqrt{\alpha_t}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_t} \mathbf{x}_t, \ \ \tilde{\beta}_t:=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} \beta_t\end{aligned}\tag{3}\]
故KL散度比较皆发生在两个Gaussian间。
\(L_{t}\)的简化
可以看到,\((1)\)式中的\(L_T\)代表前向扩散过程,与待求解的参数项\(\theta\)无关,因此可被忽略:
\[\arg \min_{\theta} (L) \iff \arg \min_{\theta} \left(\mathbb{E}_q\left[ \sum_{t>1} \underbrace{D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right) \| p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\right)}_{L_{t-1}} \underbrace{-\log p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right)}_{L_0}\right]\right)
\]
注:在2015年提出diffusion框架的论文,前向扩散过程中的\(\beta_t\)是可以被学习的参数,故此处可视作DDPM的第一处简化。
\(L_{t-1}\)的简化
对于反向扩散过程的分布\(p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\),共涉及到两组参数\(\boldsymbol{\mu}_\theta\)与\(\boldsymbol{\Sigma}_\theta\),DDPM的第二处简化是定义\(\boldsymbol{\Sigma}\)为常数\(\sigma_t^2\),在计算中使用\(\beta_t\)或\(\tilde{\beta}_t\)代替,故\(p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)=\mathcal{N}\left(\mathbf{x}_{t-1} ; \boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right), \sigma_t^2\mathbf{I}\right)\)
基于Part4两个高斯的KL散度,对于\(L_{t-1}\),有:
\[L_{t-1}=\mathbb{E}_q\left[\frac{1}{2 \sigma_t^2}\left\|\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)-\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right)\right\|^2\right]+C \tag{4}
\]
其中\(C\)是个常数项。
仔细观察\((4)\)不难发现,想要目标函数最小化,则\(\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)\)与\(\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right)\)间的“距离必须要近”。也就是说,深度网络通过训练,使得\(\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right)\)趋近于\(\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)\)。为了使训练更加简单,尝试对\((4)\)式改写。
在Foward Process中,\(\mathbf{x}_t\)可由\(\mathbf{x}_0\)与\(\epsilon\)表示(见Part4推导一),不妨将\(\mathbf{x}_t\)记作\(\mathbf{x}_t({\mathbf{x}_0, \epsilon})\),故\(\mathbf{x}_0\)可以展开表示为\(\mathbf{x}_t({\mathbf{x}_0, \epsilon})\)与\(\epsilon\)的差:
\[\mathbf{x}_t = \sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \epsilon \ \Rightarrow \ \mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\epsilon)\tag{5}
\]
又因为\((3)\)式,故有:
\[\begin{aligned}
\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)
&= \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1-\bar{\alpha}_t} \mathbf{x}_0+\frac{\sqrt{\alpha_t}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_t} \mathbf{x}_t \\
&= \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t}{1-\bar{\alpha}_t} * \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_{t}}\epsilon}{\sqrt{\bar{\alpha}_t}} + \frac{\sqrt{\alpha_t}\left(1-\bar{\alpha}_{t-1}\right)}{1-\bar{\alpha}_t} \mathbf{x}_t \\
&= \frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon\right)
\end{aligned}\tag{6-1}
\]
前文提到,要优化\((4)\)式,则必然有:\(\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right) \to \tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)\)。其中,\(\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right)\)是深度网络的输出(预测)结果,\(\mathbf{x}_t\)与\(t\)作为模型的输入参数。
由\(\text{(6-1)}\)可知\(\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)\)能展开为\(\mathbf{x}_t\)与\(\epsilon\)的表达,\(\mathbf{x}_t\)已知,那不妨令原本要预测\(\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right)\)的深度网络直接预测\(\boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t, t\right)\),变换前后依然等价。即
\[\begin{aligned}
\boldsymbol{\mu}_{\theta^{\prime}}\left(\mathbf{x}_t, t\right)
\iff \frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t, t\right)\right)
\end{aligned}
\tag{6-2}
\]
此处以\(\theta^{\prime}\)与\(\theta\)对变换前后的深度网络参数进行区分,故\(\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta\left(\mathbf{x}_t, t\right)\right)\)需要无限趋近于\(\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)\)。
将\(\text{(6-1)}\)与\(\text{(6-2)}\)代入\((4)\)式,有:
\[\begin{aligned}
& L_{t-1}-C^\prime \\
=&\mathbb{E}_q\left[\frac{1}{2 \sigma_t^2}\left\|\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t, \mathbf{x}_0\right)-\boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right)\right\|^2\right] \\
\iff& \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}}\left[\frac{1}{2 \sigma_t^2}\left\|\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t\left(\mathbf{x}_0, \boldsymbol{\epsilon}\right)-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon}\right)-\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t\left(\mathbf{x}_0, \boldsymbol{\epsilon}\right)-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \boldsymbol{\epsilon_\theta}(\mathbf{x}_t, t)\right)\right\|^2\right] \\
=& \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}}\left[\frac{\beta_t^2}{2 \sigma_t^2 \alpha_t\left(1-\bar{\alpha}_t\right)}\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right)\right\|^2\right]
\end{aligned}
\tag{7}
\]
对比\((4)\)与\((7)\),不难发现参数\(\theta\)作用的对象发生变化。在\((4)\)中,\(\theta\)的参数化对象为高斯分布的均值\(\boldsymbol{\mu}\);而在\((7)\)中,\(\theta\)的参数化对象转移到\(\boldsymbol{\epsilon}\)。实际上,不仅可以参数化\(\boldsymbol{\mu}\)和\(\boldsymbol{\epsilon}\),也可以参数化\(\mathbf{x}_0\),只需要对\((5)\)中表示的主体进行变换即可。
并且,重新审视\(\text{(6-2)}\),该式与Part1中的采样算法联系上了。上述目标函数的设定及推理,皆是为了获取反向过程的分布\(p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right) :=\mathcal{N}\left(\mathbf{x}_{t-1} ; \boldsymbol{\mu}_\theta\left(\mathbf{x}_t, t\right), \boldsymbol{\Sigma}_\theta\left(\mathbf{x}_t, t\right)\right)\)。
通过公式\(\text{(6-2)}\),按照反向过程相邻状态间的图像转换服从高斯分布的定义,反向过程中知晓\(\mathbf{x}_t\)与\(t\)后,通过深度网络预测出\(\boldsymbol{\epsilon}\),再基于此求出\(\boldsymbol{\mu}_{t}\),结合自定义的\(\boldsymbol{\sigma}_{t}\),可采样得到\(\mathbf{x}_{t-1}\),便实现反向过程的一次“降噪”。
\(L_{0}\)的简化
这一项对应着信息由隐变量转变回\(\mathbf{x_0}\),故而需要特殊考虑。
真实图片中各个像素由0到255的数值组成,在处理时通常将所有像素值归一化到区间[-1,1]。论文中将该项对应的优化目标定义为:
\[\begin{aligned}
p_\theta\left(\mathbf{x}_0 \mid \mathbf{x}_1\right) & =\prod_{i=1}^D \int_{\delta_{-}\left(x_0^i\right)}^{\delta_{+}\left(x_0^i\right)} \mathcal{N}\left(x ; \mu_\theta^i\left(\mathbf{x}_1, 1\right), \sigma_1^2\right) d x \\ \delta_{+}(x) & =\left\{\begin{array}{ll}\infty & \text { if } x=1 \\ x+\frac{1}{255} & \text { if } x<1\end{array} \quad \delta_{-}(x)= \begin{cases}-\infty & \text { if } x=-1 \\ x-\frac{1}{255} & \text { if } x>-1\end{cases} \right.
\end{aligned}
\tag{8}
\]
其中,积分项是为了与图片真实像素的离散特性保持一致,\(D\)为像素点的个数。
该项的优化目标是:对于输入图片\(x_0\)的所有像素位置,使得基于神经网络产生的高斯分布在该位置的采样结果,与\(x_0\)对应位置的真实值相差不大。
直接文字阐述并不好理解,下方是对于单个位置的具体实例,截图来自视频:
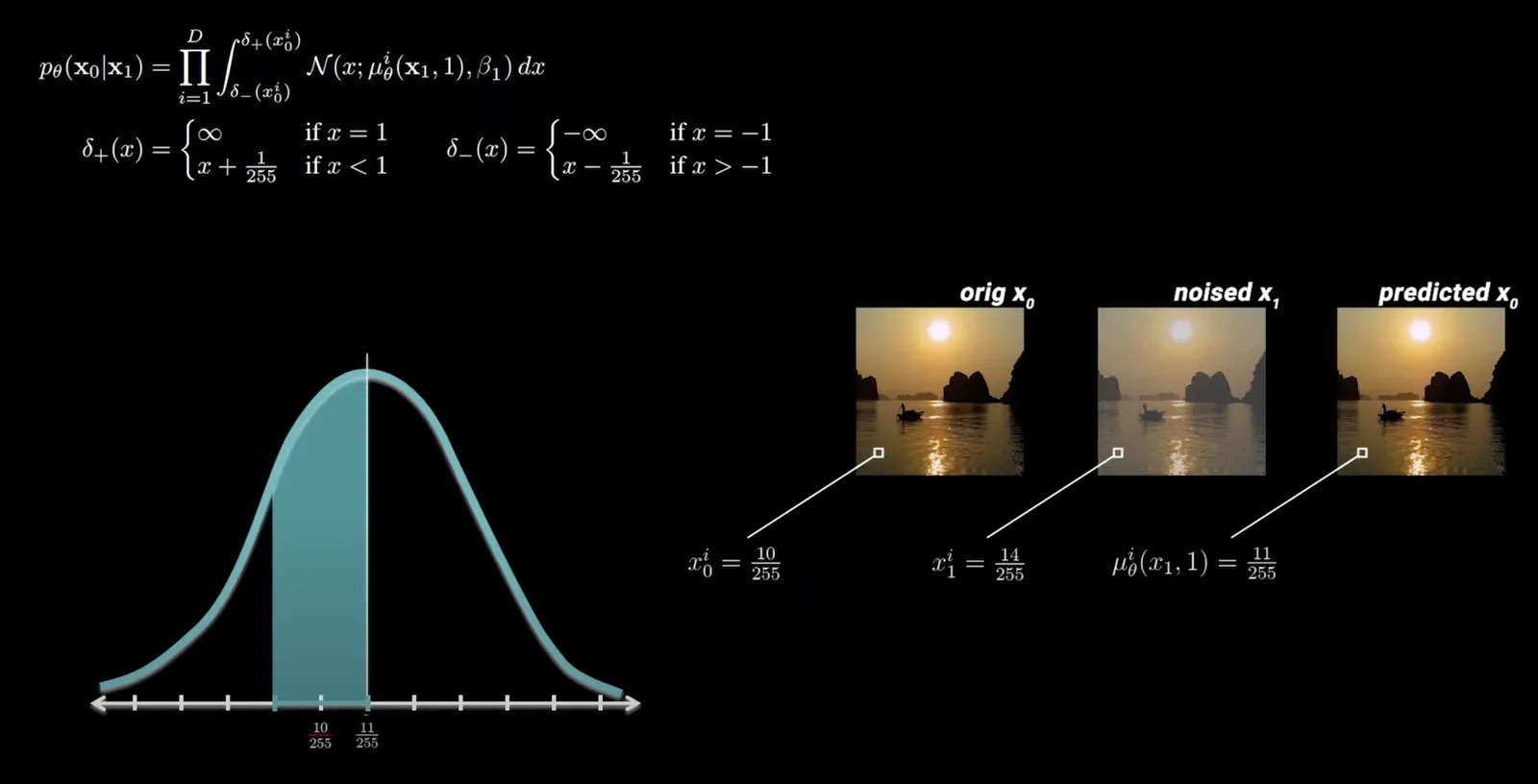
当前有一张真实的图片\(x_0\),对应上图内靠左边的图片,经过缩放后,在位置\(i\)的值为\(x^i_0 = \frac{10}{255}\);
并且,中间图片表示在\(x_1^i\)(此时还处于有噪声状态),经过神经网络模型,预测出该位置的值是服从均值为\(\frac{11}{255}\)的高斯分布\(\mathcal{N^1}\);
在左下角画出该\(\mathcal{N^1}\)的概率密度曲线,此时积分的上下界为\((\frac{9}{255}, \frac{11}{255})\),从图上可以直观地看出积分对应的阴影面积相对来说比较大。故基于此采样得到的\(\hat{x_0}^i\)与输入图片\(x_0^i\)接近的置信度很高。在训练时反映出来的是,神经网络在该位置的预测表现对\((8)\)式即Loss的贡献程度较低;
但如果神经网络预测出该位置的值服从服从均值为\(\frac{105}{255}\)的高斯分布\(\mathcal{N^2}\),此时概率密度曲线整体会往右平移,\((\frac{9}{255}, \frac{11}{255})\)区域属于长尾位置,显然积分结果比较小,从侧面来说,基于此采样得到的\(\hat{x_0}^{i_\prime}\)与输入图片\(x_0^i\)接近的置信度很低,在训练时对Loss的贡献程度高,在反向传播时的梯度也大。
实际代码实现中,该项被省略,这是第三处简化。
简化的损失函数
回顾\((1)\)式,目前只剩下以\(L_{t-1}\)为主体的求和部分,如下所示:
\[\begin{aligned}
\arg \min_{\theta} (L) & \iff \arg \min_{\theta} \mathbb{E}_q\left[ \sum_{t>1} \underbrace{D_{\mathrm{KL}}\left(q\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{x}_0\right) \| p_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t\right)\right)}_{L_{t-1}} \right] \\
& \iff \arg \min_{\theta} \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}}\left[\frac{\beta_t^2}{2 \sigma_t^2 \alpha_t\left(1-\bar{\alpha}_t\right)}\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right)\right\|^2\right]
\end{aligned}
\tag{9}
\]
对于\((9)\)式,DDPM的第四处简化在于省略了均方差损失项的权重,最终的损失函数\(L_{simple}\)为:
\[\begin{aligned}
L_{\text {simple }}(\theta):=\mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}}\left[\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right)\right\|^2\right]
\end{aligned}
\]
总结
回顾本文,DDPM在损失函数上做了很多简化,对于代码侧的实现非常友好。同时,论文作者也给出实验对比,验证简化并不会使得结果变差,有些简化(比如设置reverse过程中的\(\Sigma\)为非参数项)甚至取得大幅度的提升效果。
Reference

 浙公网安备 33010602011771号
浙公网安备 33010602011771号