Jupyter使用py文件代码
在Jupyter中使用py文件中的代码时,可使用包sys引入路径后,再进行调用。但是这样存在一个问题,每次修改py文件中的代码时,需要重启才能正确使用修改过后的py文件代码,这样是非常没有效率的。
那么在Jupyter cell中可以通过如下几行命令以及包importlib,在每次py文件有修改时,自动引入更改后的该模块:
%load_ext autoreload
%autoreload 1
%aimport heihei
比如在这里,我有一个python文件(模块)叫做heihei。下面我来展示如何在jupyer中使用上述几行命令,使得在对heihei进行修改后,不用restart而直接使用更改后的heihei代码。
代码
首先,我有两个文件夹,ipynb以及src,我要执行的.ipynb文件存放在文件夹ipynb中,heihei.py位于src文件夹中,其中有一个方法叫做print_info(),具体代码如下:
def print_info():
print("Hello, Hello, This is ober.")
print("Oh my god.")
print("fungu.")
print("真的改了么?")
一开始,需要使用包sys引入src/heihei/:
import sys
import importlib
sys.path.append('../src/')
同时可以看到,引入了一个包importlib。
%load_ext autoreload
%autoreload 1
%aimport heihei # 引入heihei模块使用该魔法命令
importlib.reload(heihei)
接下来可以先尝试直接运行heihei.print_info(),在对print_info()方法中的最后一行信息注释后,再运行。结果如下图所示:
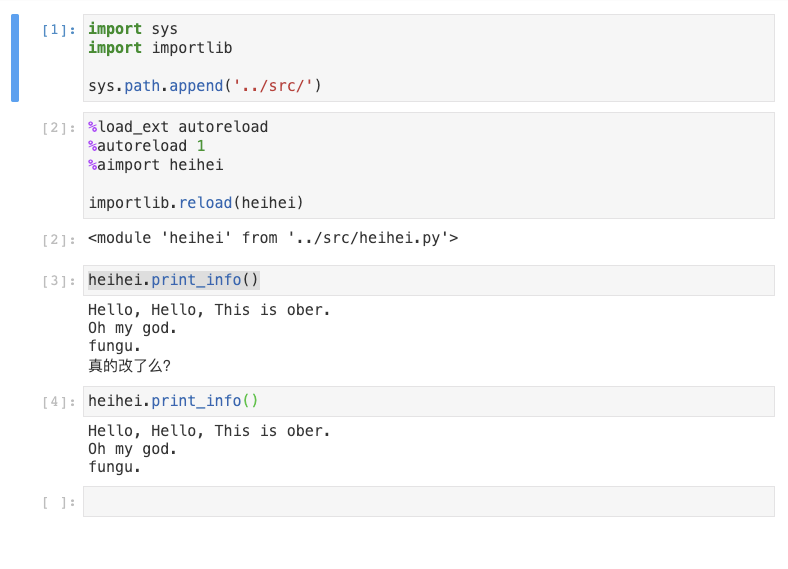
额外
importlib.reload(heihei),reload方法只能重载模块,如果不想使用heihei.print_info()而是想使用print_info()运行,那么需要在每次修改完对应的部分后,从该模块导入待执行的方法,如from heihei import print_info,之后运行print_info便能看到改变了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号