Part1: Overview of Diffusion Process
本文将会概括性地介绍\(\textit{Diffusion Process}\)算法与实践,主要参考论文《Denoising Diffusion Probabilistic Models》。它的一些改进与优化,将“扩散方法”带入主流视野。
而具体的数学推导部分,请参考其它系列文章。整个系列有相对完整的公式推导,若正文中有涉及到的省略部分,皆额外整理在Part4,并会在正文中会指明具体位置。
- Part1: Overview of Diffusion Process
- Part2: DDPM as Example of Variational Inference
- Part3: Dive into DDPM
- Part4: Appendix
Image Synthesis
在正式引入\(\textit{diffusion}\)前,希望先简单介绍图像生成的相关背景。一张图像由很多个像素点组成,对于彩色图像,每个像素点由三个0至255的整数表达,比如[255, 255, 255]代表像素点对应的颜色为白色。而一张512*512的图像就意味着共有26w左右的像素点。

图像生成的目标是学习像素及像素间的概率分布。结合具体的例子来理解概率分布,上图为拍摄于户外的照片。
假定它是由比较好的模型生成得到的图像。看到“图像上方是一片天空”,因为它是天空,所以上方的像素点不会是大面积的绿色覆盖。在生成天空区域时进行数值采样,采样到淡白色或者淡蓝色对应数值的概率,远大于采样到绿色对应数值的概率。
通过常规的机器学习方法,直接学习上述提到的概率分布很难,同时计算也很复杂。\(\textit{diffusion}\)的提出为学习图像的概率分布提供新的思路和解决办法。
Diffusion Process
图像生成领域的\(\textit{Diffusion Process}\)最早在2015年发表的论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》提到,作者认为它是一种适配于深度学习背景下的图片生成框架。其灵感来源于统计物理学中的非平衡态热力学\((\textit{non-equilibrium})\)。在该领域,\(\textit{diffusion}\)并非新名词,用于描述分子运动的现象。
Diffusion is the movement of a substance from a region of high concentration to a region of low concentration without bulk motion.
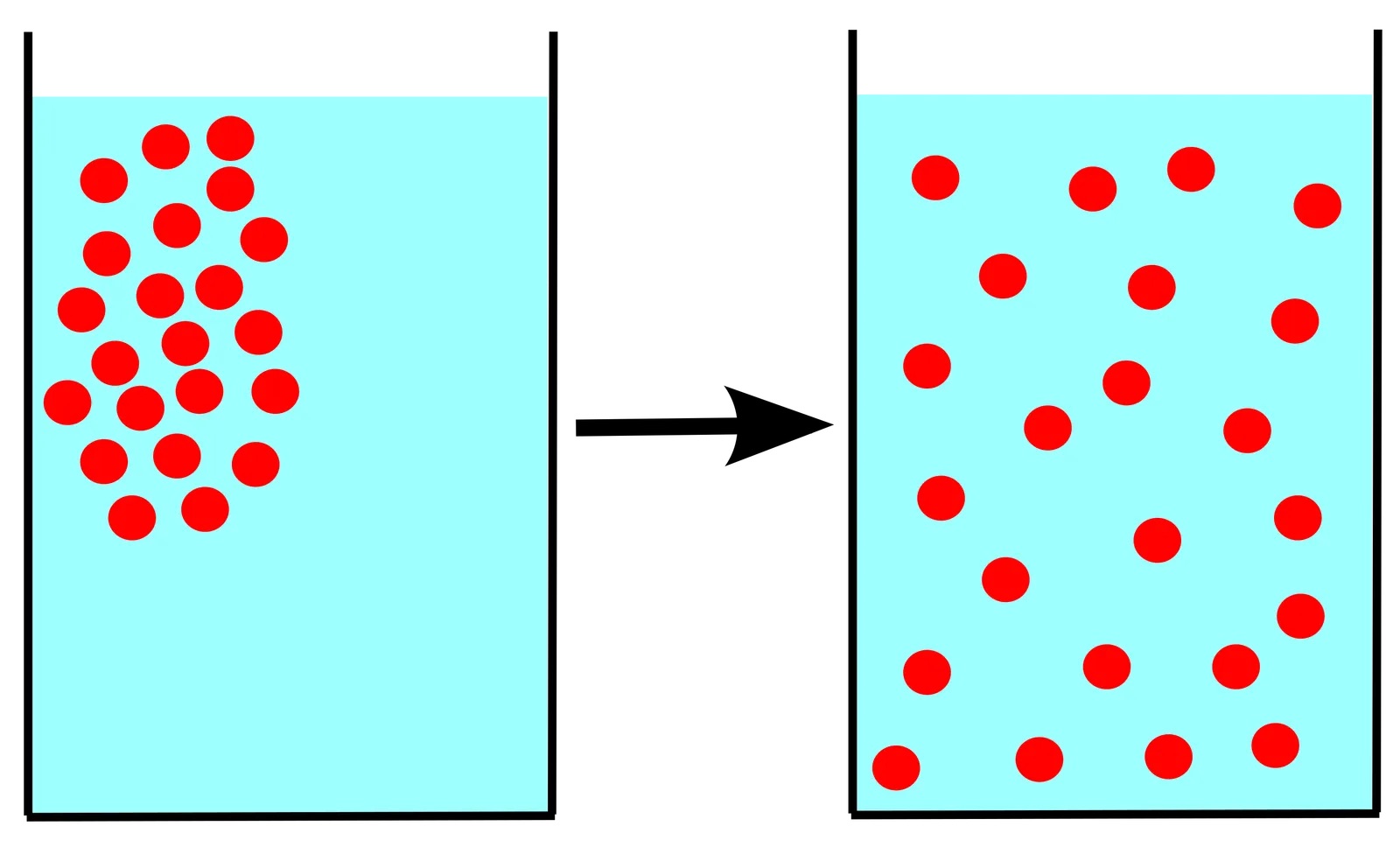
上图中,起初红色分子都聚集在液体的左上角,而当趋于稳定后,红色分子遍布在整个液体中。
那在图像生成领域,论文作者获取到的灵感是什么?
图像生成的其中一个难点在于不知晓图像服从何种分布,如此统计机器学习无法派上用场。故\(\textit{diffusion}\)的思路是,在\(\textit{forward process}\)中,通过缓慢、持续地往原数据上增加其它分布的数据,将图片原本分布破坏掉,转变到其它分布;同时,存在一个\(\textit{reverse process}\),即通过深度模型学习「如何将破坏掉的分布复原回破坏前的分布」。
前后两个过程都是缓慢且逐步进行的,天然地可以用马尔可夫链\((\textit{Markov chain})\)建模。并且,选择的其它分布是常见分布,比如高斯分布或二项分布等。这类分布的特性为人们熟知,可以方便地进行计算。
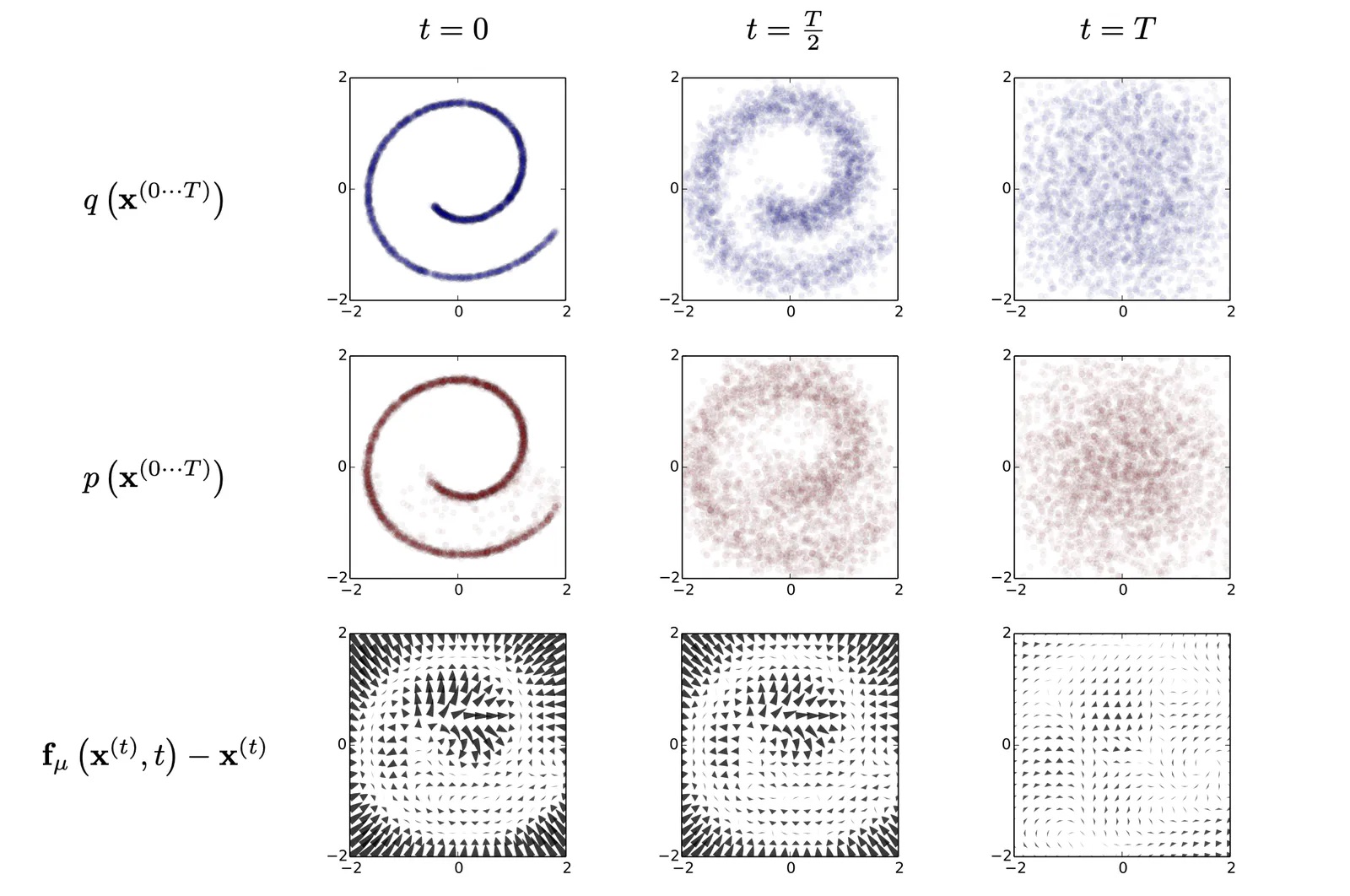
上图第一行描述二维数据分布从\(t = 0\)至\(t = T\)的变化情况,数据分布初始时为Swiss Roll,在逐步经过Gaussian的diffusion后,最终完全转变到服从Gaussian。
下面将围绕以下几部分展开介绍,符号定义与论文《Denoising Diffusion Probabilistic Models》保持一致:
- Forward Process
- Reverse Process
- Loss Function
- Model Architecture
- Train and Sample
Forward Process
给定一张图片,将其初始状态记为\(\mathbf{x}_0\),逐渐地对其增加服从其它分布的数据,如服从高斯分布,重复若干轮后,原图片的特征逐渐被销毁,完全难以分辨。为了方便,下文记“其它分布的数据”为噪声。

若对上图经过缓慢地加噪,其变换情况如下图所示。

整个缓慢的加噪过程建模为马尔可夫过程,状态间的转变\(\mathbf{x_{t-1}} \rightarrow \mathbf{x_{t}}\)服从高斯分布:
故时刻\(t\)的图片\(\mathbf{x_t}\),由\(\mathbf{x_{t-1}}\)经过\((2)\)式得到,\((2)\)式的推导见Part4中高斯分布的性质1:
其中,\(\beta_t\)是个参数,为0到1的小数,表示时刻\(t\)噪声增加的幅度。有过相关实践的同学,应该会在模型文件或者代码中看到scheduler的字样,它便是用来产生\(\beta_t\)的模块。
对\((2)\)式中的项\(\beta_t\)改写,定义:
则通过推导(见Part4中推导一,可以得到\((3)\)式:
这是一个很好的性质,意味着任意时刻的状态\(\mathbf{x}_t\)皆可由\(\mathbf{x}_0\)基于一次运算得到。在后续实际进行训练时,自然地与随机梯度下降\((\textit{Stochastic Gradient Descent})\)结合使用。
并且,当\(t\)足够长,发现\((3)\)式的第一项趋近于0,而\(\mathbf{x}_t \approx \epsilon\)。这也印证,经过逐步缓慢的“扩散过程”后,原数据的分布会被破坏,转而服从所加入噪声的分布。
Reverse Process
当\(\textit{forward process}\)进行完毕后,认为\(\mathbf{x}_T\)基本看作是一张噪声图片,它的像素点服从标准高斯分布。
$$p(\mathbf{x}_T) \sim \mathcal{N}(0, \mathbf{I})$$
前文提到\(diffusion\)方法需要在reverse阶段对被破坏的分布进行复原,如视频所示:
在这一过程中,深度学习模型介入,基于\((4)\)式表达这一过程:
其中,\(\theta\)对应模型的参数。
Loss Function
扩散模型的损失函数基于变分推断\((\textit{variational inference})\)得到。简单来说,最初的目标是最大化对数似然估计,但直接对\(\ln p_\theta\left(x_0\right)\)无从做起。基于变分推断的思想,引入该目标的下界ELBO,通过最大化该下界实现计算。具体推导ELBO的方式请查看Part2。
经过一系列推导,最后简化得到的损失函数如下所示:
$$L = \left|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(\sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}, t\right)\right|^2
\tag{5}$$
目标是给定任意时刻\(t\)的状态\(\mathbf{x}_t\),预测此状态中所包含的噪声\(\epsilon_{\theta}(\mathbf{x}_t, t)\),并与真实增加的噪声\(\epsilon\)比较。\((5)\)式完全就是平方差损失函数\((\textit{mean squared error})\)。
Model Architecture
基于\((5)\)式,不难发现模型的输入与输出皆为图片格式的数据。在DDPM中,使用U-Net作为该部分模型的结构。下图为U-Net原始的结构框架: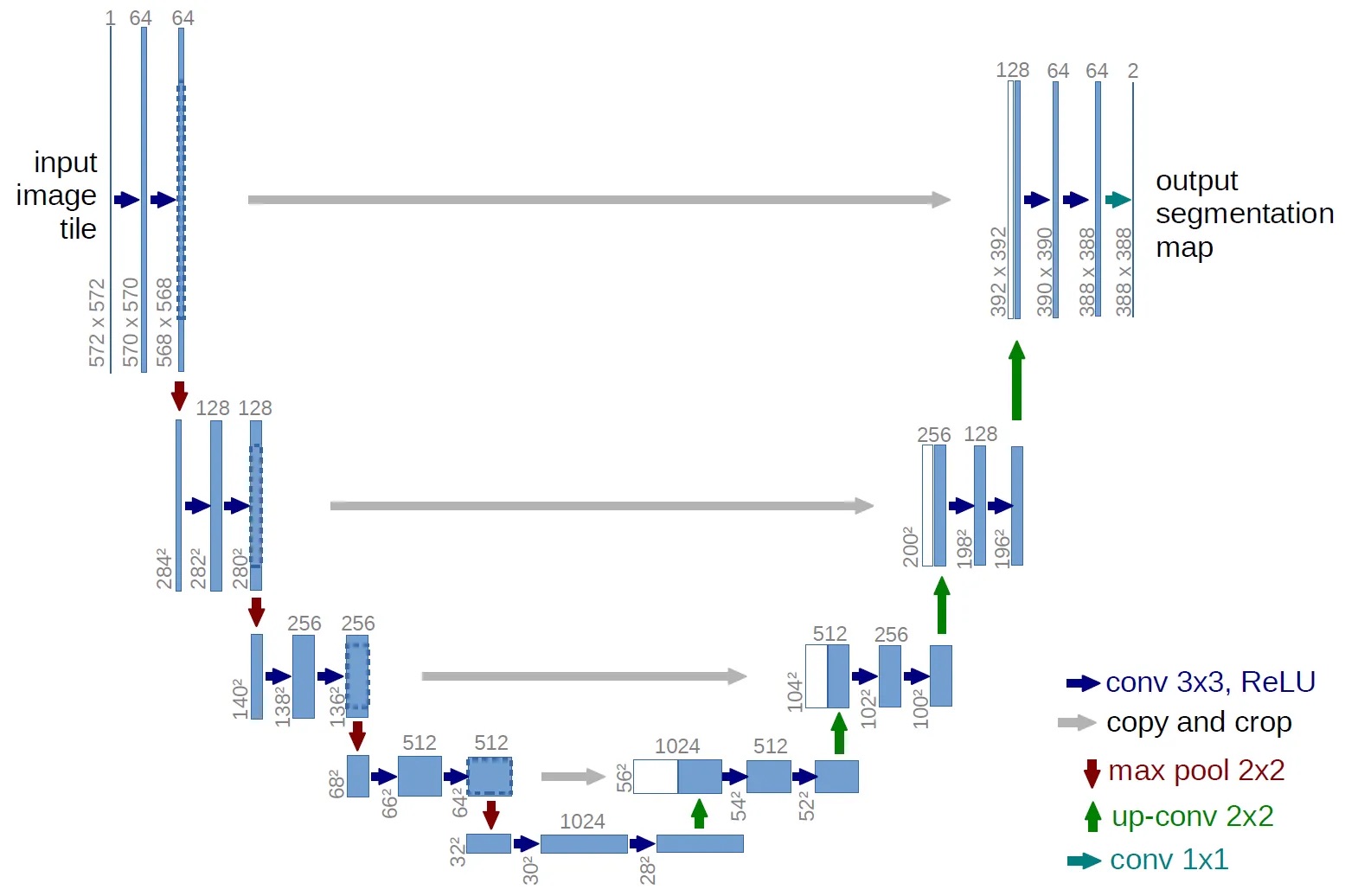
DDPM中使用的UNet在原基础上,对于每个Block加入Attention以及Residual等模块。
拿上图所示的UNet举例,其包含Down、Mid以及Up三部分,体现在图中时,左边包含有红色向下箭头的部分皆属于Down,最底下包含数字1024的为Mid,而右边属于Up部分。不难看出,UNet的形状是镜像对称的,但是Down与Up输入的张量维度却是不同,主要原因在于:Up中所有的子模块输入,除了接收上一层传递过来的张量,还会接收对应层级Down子模块传递过来的输出。拿Up部分最低一层56x56x1024来说,其中56x56x512来自较低一层传递而来,另一部分的56x56x512从左边的64x64x512经过copy+resize而来,两者concate之后构成了当前层的输入。
更加具体的代码实现可以参考。
Train and Sample
这样一来,模型的训练算法如下所示:
而采样算法如下所示:
其中,\(\sigma_t\)在具体实现中一般设置为\(\sqrt{\beta_t}\),是在diffusion process时该时间步\(t\)对应的标准差。
Summary
本文相对粗旷地介绍了“扩散过程”。前半阶段,主要基于论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》引入\(\textit{diffusion}\)的具体思想;后半阶段,以《Denoising Diffusion Probabilistic Models》为例,引入其训练与采样的算法步骤。
对于\(\textit{diffusion}\),其最终在代码层面的实现不算复杂;实际上,比较令人着迷的是其完备的数学推导,以及与其它隐变量模型\((\textit{latent models})\)的关联。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号