03_Spark集群部署
【安装前的环境准备】
Hadoop:2.6.1
Java:jdk-1.7.0
Spark: spark-1.6.0-bin-hadoop2.6.tgz
Scala: scala-2.11.4.tgz
虚拟机:host01,host02,host03; 其中host01是spark集群的主节点master, 其余两台是slave节点
【每台机器上安装Scala】
原因:每台机器上执行Scala代码,Python代码编写的Spark Application,默认Spark也是使用Scala语言
1)拷贝Scala到所有节点,修改文件权限、属主、解压、简化文件夹名称
# chmod 755 scala-2.11.4.tgz # chown root:root scala-2.11.4.tgz # tar -xzvf scala-2.11.4.tgz # rm -rf scala-2.11.4.tgz
2) 修改/etc/profile环境变量文件
export SCALA_HOME=/usr/local/src/scala-2.11.4/ export PATH=$PATH:$SCALA_HOME/bin
3)生效环境变量
# source /etc/profile
4)检查Scala是否安装成功

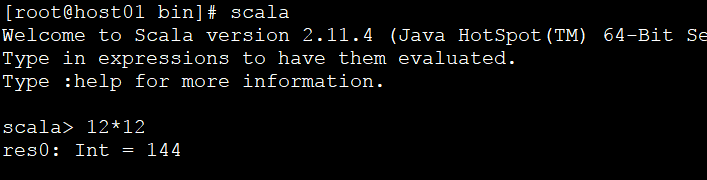
5)在其他节点上同样安装scala
【每台机器上安装Spark】
1、节点一 Host01
1) 拷贝spark安装包到该节点,修改文件权限、属主、解压、简化文件夹名称
# chmod 755 spark-1.6.0-bin-hadoop2.6.tgz # chown root:root spark-1.6.0-bin-hadoop2.6.tgz # tar -xzvf spark-1.6.0-bin-hadoop2.6.tgz # mv spark-1.6.0-bin-hadoop2.6 spark-1.6.0
2) 配置/etc/profile环境变量
# SPARK_HOME export SPARK_HOME=/usr/local/src/spark-1.6.0/ export PATH=$PATH:$SPARK_HOME/bin
3)环境变量生效
# source /etc/profile
4)配置spark-env.sh
路径:/usr/local/src/spark-1.6.0/conf/
# cp spark-env.sh.template spark-env.sh # vim spark-env.sh
添加如下配置:
export JAVA_HOME=/usr/local/src/jdk1.7.0/ export SCALA_HOME=/usr/local/src/scala-2.11.4/ export SPARK_MASTER_IP=host01 export SPARK_DRIVER_MEMORY=1G export HADOOP_HOME=/usr/local/src/hadoop-2.6.1/ export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/ # 通过该路径,确定yarn export SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6.0/tmp/ # spark进行shuffle,或者RDD持久化时的本地目录
5)配置slaves文件
路径:/usr/local/src/spark-1.6.0/conf/
# cp slaves.template slaves # vim slaves
修改为如下:
# A Spark Worker will be started on each of the machines listed below.
host02 # 将worker节点,spark集群中的slave角色,写入即可
host03
6)将节点1上的spark目录复制到其他两个节点(host02,host03)
# scp -rp spark-1.6.0 root@host02:/usr/local/src/ # scp -rp spark-1.6.0 root@host03:/usr/local/src/
2、节点host02
1)修改/etc/profile, 增加spark环境变量
# SPARK_HOME export SPARK_HOME=/usr/local/src/spark-1.6.0/
export PATH=$PATH:$SPARK_HOME/bin
2)环境变量生效
# source /etc/profile
3、节点host03
1)修改/etc/profile, 增加spark环境变量
# SPARK_HOME export SPARK_HOME=/usr/local/src/spark-1.6.0/ export PATH=$PATH:$SPARK_HOME/bin
2)环境变量生效
# source /etc/profile
4、启动spark集群,并查看各个节点的Spark进程
【先启动haoop集群】
1) Spark主节点,启动整个集群
路径:/usr/local/src/spark-1.6.0/sbin
# ./start-all.sh
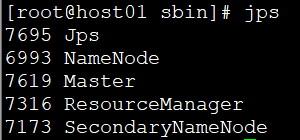
2)Spark主节点进程 Master
# jps
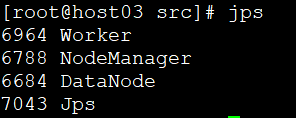
3)Spark从节点进程 Worker
# jps

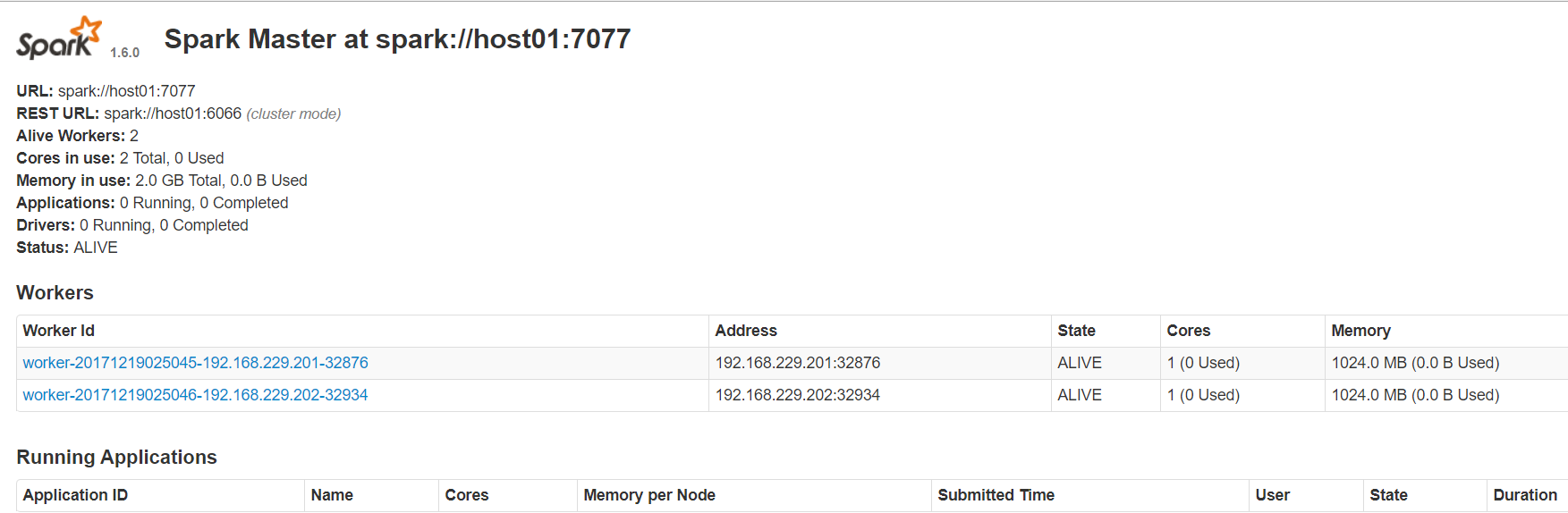
4)Spark UI (http://主节点:8080)
Spark UI: 8080, 运行在Master
Standalone模式下的运行的Spark Application,会在Spark UI显示
Spark集群验证(不同方式提交Spark Application,查看运行情况)
1、本地模式提交自带的示例Spark Application
# ./bin/run-example SparkPi 10 --master local[2] //2个线程,本地模式运行,run-example会调用spark-submit进行提交
结果:结果和日志会直接打印到终端

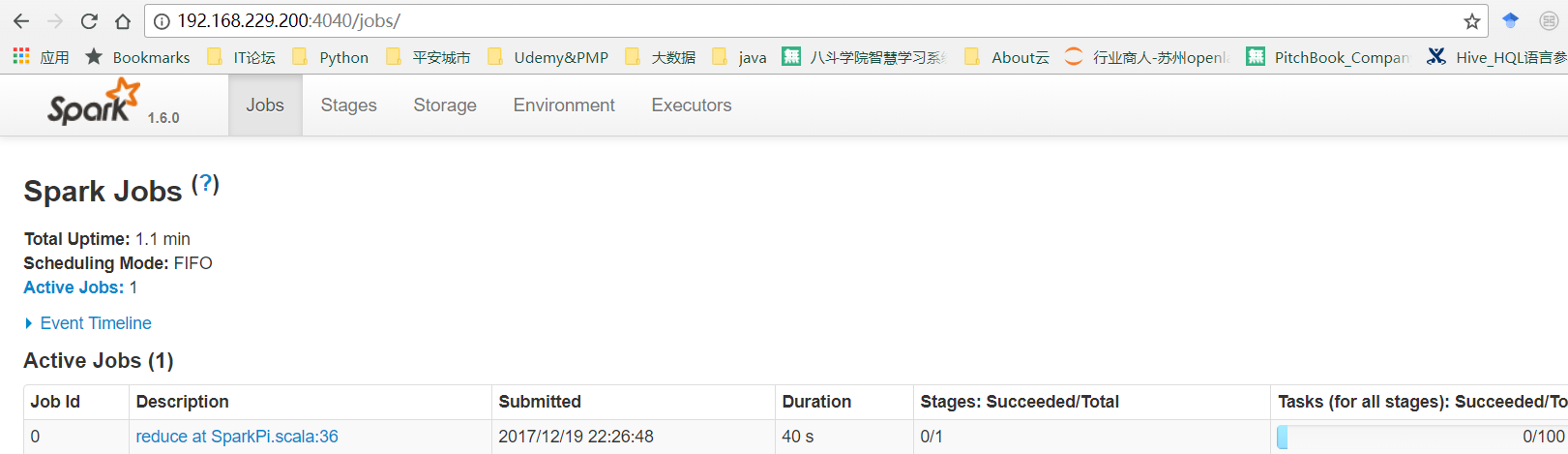
也可以通过Driver上的Application运行期间,提供的WEB UI http://<driver-node>:4040 查看
2、Standalone集群模式提交
# ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://host01:7077 \ lib/spark-examples-1.6.0-hadoop2.6.0.jar \ 100
监控:1)提交作业的终端会打印信息
2)Spark UI会出现该Application, Application Detail则会跳转到Driver Programme Web UI(4040)

Spark UI(8080)查看Spark Application

Driver Programme Web UI(4040)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号