02_Kafka单节点实践
1、实践场景
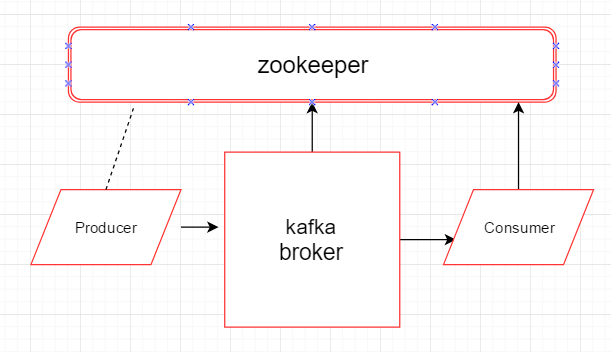
开始前的准备条件:
1) 确认各个节点的jdk版本,将jdk升级到和kafka配套的版本(解压既完成安装,修改/etc/profile下的JAVA_HOME,source /etc/profile,重启后jdk生效)
2、单节点kafka实践
1) 启动zookeeper集群
各个节点上启动zookeeper进程
# bin/zkServer.sh start
启动后,查看各个节点的zookeeper状态 (leader, follower etc)
#bin/zkServer.sh status
2) 配置kafka的zk集群
配置文件:config/zookeeper.properties
配置要点:zookeeper中snapshot数据的存放地址,和zookeeper集群中的配置保持一致
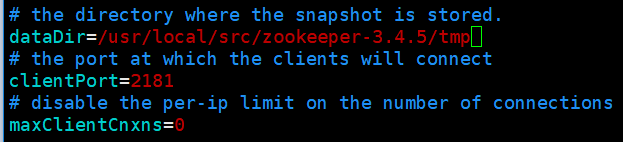
3) 配置本节点上要启动的broker
配置文件: config/server.properties
配置要点:
broker.id
log.dirs (将在该路径下自动创建partition目录)
zookeeper.connect (broker要连接的zookeeper集群地址和port)
检查broker发布给producer和consumer的主机名和端口号(9092)
配置后的参数如下:
# broker id, 每个broker的id必须是唯一的 broker.id=0 # kafka存放消息的目录 log.dirs=/usr/local/src/kafka_2.11/tmp/ # broker连接的zk集群,节点间通过逗号分隔,默认zk开放给客户端连接的端口号是2181 zookeeper.connect=master:2181,slave1:2181,slave2:2181

注意:
1) 默认Kafka会直接在ZooKeeper的根路径下创建znode,这样Kafka的ZooKeeper配置就会散落在根路径下面
2) 可以指定kafka在zookeeper的某个路径下去进行操作, 将server.properties中的zookeeper.connect修改为:
a. zookeeper.connect=master:2181,slave1:2181,slave2:2181/kafka
b. 同时手动在zookeeper中创建/kafka节点 (create /kafka)
4)启动单个Broker
# ./bin/kafka-server-start.sh ./config/server.properties

5)查看当前kafka集群中的Topic
# ./bin/kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181 # ./bin/kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181/kafka # 如果修改了kafka在zookeeper下的znode节点路径,则要在--zookeeper参数中跟上chroot路径
6) 创建topic
创建Topic时,会根据broker的个数,对replication-factor进行校验;
# ./bin/kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181 --replication-factor 1 --partitions 1 --topic mytopic
7) 查看topic描述信息
# ./bin/kafka-topics.sh --describe --zookeeper master:2181,slave1:2181,slave2:2181 --topic mytopic

partition:0 该partition的编号,从0开始
leader:0 该partition的leader节点的broker.id = 0
replicas:0 表示partition落地的所有broker, 包括leader在内
isr:0 当前处于in-sync的replicas节点, 包括leader在内, broker.id = 0
8) zookeeper上将记录kafka已经创建的topic

9)broker的log.dirs中将创建partition目录
目录名:topic名-partition编号 //编号从0开始
mytopic-0

10)Partition目录下的segment文件
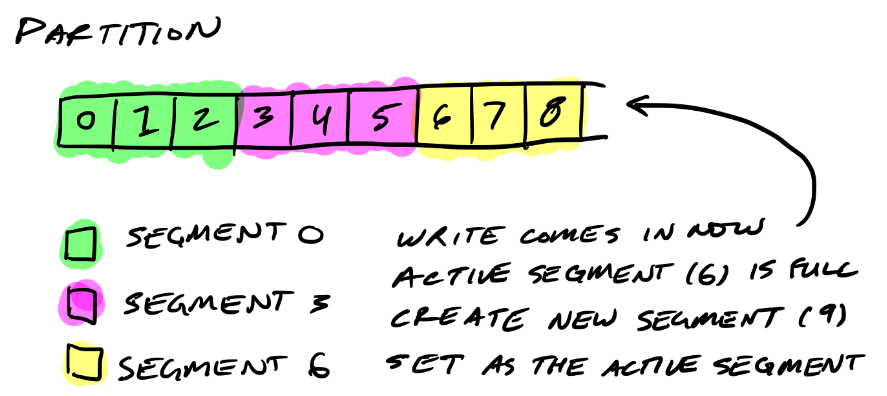
每一个segment,都会由 log文件,index文件 组成

解析:
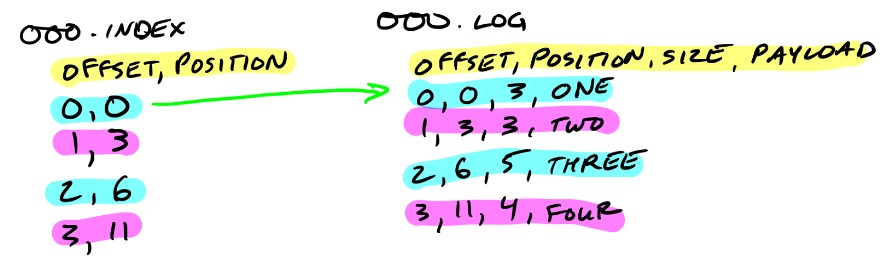
xxxx.log -- 最初的log文件,文件名是初始偏移(base offset), 消息存储在log文件
xxxx.index -- 最初的index文件,文件名是初始偏移(base offset),index则用于对应log文件内的消息检索
offset, postion
offset, 消息计数; postion,消息头在log文件中的起始位置(position从0开始)
index文件可以映射到内存,从index文件的名字可以判断出某一个消息应该位于哪一个log文件
segment文件的默认最大size为1G,超过该size后才会创建新的segment文件,新的segment文件将称为active segment, 数据是向active segment写入
11) 调整Topic的partition个数
只能增加,不能减少
# ./bin/kafka-topics.sh --alter --zookeeper master:2181,slave1:2181,slave2:2181 --topic mytopic --partitions 2

物理的partition目录,也变为了2个

12)使用kafka提供的Producer客户端,模拟消息发送
# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic mytopic
--broker-list: 该producer要向哪些broker推送消息, ip:port形式说明
--topic: 该producer要向哪一个Topic发送消息
启动producer客户端后,每行都会作为一条message, 存储到该topic的partition文件下的log文件中

13) 查看log文件中,消息落地到了哪里
1) 由于消息中没有指定key, kafka将针对每条message,随机找一个partition进行存放
2)4条消息,存储到了两个分区mytopic-0和mytopic-1下
mytopic-0分区,log文件存储了2条消息

mytopic-1分区,log文件存储了2条消息

14)启动Consumer, 模拟消息的消费
1、Consumer消费消息时,只需要指定topic+offset
2、通过zookeeper获取topic的partition位于哪些broker上,各自的leader broker是谁,然后和leader broker连接,获取数据
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic mytopic --from-beginning
3、观察多个partition下,consumer端数据的顺序
topic有2个分区,consumer端得到的数据顺序和发送端的不一定相同,但每个partiton内部的消息顺序能够保证(非全局有序,partition内部有序)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号