
04_Flume多节点load_balance实践
1、负载均衡场景
1)初始:上游Agent通过round_robin selector, 将event轮流发送给下游Collecotor1, Collector2
2)故障: 关闭Collector1进程来模拟故障,Agent1由于配置了backoff, 会将Collecotor1暂时从发送列表中移除,event全部发送给Collector2
3) 恢复: 重启Collector1进程, Collector1在经历最大timeout后,重新进入发送列表;之后的event再次分发给Collector1/2
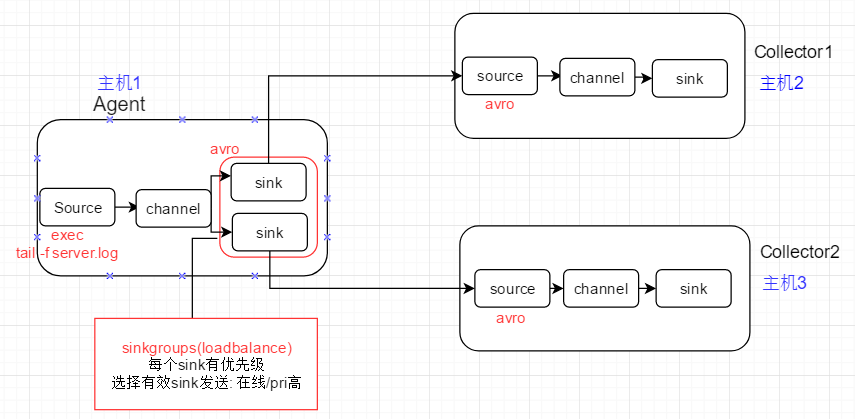
2、节点配置
2.1 上游Agent的flume配置
# 05-flume-loadbalance-client # agent name: a1 # source: exec # channel: memory # sink: k1 k2, each set to avro type to link to next-level collector # 01 define source,channel,sink name a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2 # 02 define source a1.sources.r1.type = exec a1.sources.r1.command = tail -f /root/flume_test/server.log # 03 define sink,each connect to next-level collector via hostname and port a1.sinks.k1.type = avro a1.sinks.k1.hostname = slave1 # 上游avro sink绑定到下游主机,RPC a1.sinks.k1.port = 4444 a1.sinks.k2.type = avro a1.sinks.k2.hostname = slave2 # 上游avro sink绑定到下游主机, PRC a1.sinks.k2.port = 4444 # 04 define sinkgroups, sink will be seleced for event distribution based on selecotr a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.selector = round_robin # 节点失效,则将节点从sinkgroup中移除一段时间 a1.sinkgroups.g1.processor.backoff = true # 将节点从sinkgroups中移除的时间,millisecond # 节点被暂时移除,selector就不会尝试向节点发送数据,能一定程度提高event分发速度,但event可能会分发的不均衡 a1.sinkgroups.g1.processor.selector.maxTimeOut = 10000 # 05 define channel a1.channels.c1.type = memory # number of events in memory queue a1.channels.c1.capacity = 1000 # number of events for 1 commit(commit events to memory queue) a1.channels.c1.transactioncapacity = 100 # 06 bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
2.2 下游Collector1的flume配置
# 01 specify agent,source,sink,channel a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 02 avro source,connect to local port 4444 a1.sources.r1.type = avro # 下游avro source绑定到本机端口,端口要和上游Agent中的配置值保持一致 a1.sources.r1.bind = slave1 a1.sources.r1.port = 4444 # 03 logger sink a1.sinks.k1.type = logger # 04 channel,memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 05 bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
2.3 下游Collecotor2的flume配置
# 01 specify agent,source,sink,channel a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 02 avro source,connect to local port 4444 a1.sources.r1.type = avro # 下游avro source绑定到本机端口,端口要和上游Agent中的配置值保持一致 a1.sources.r1.bind = slave2 a1.sources.r1.port = 4444 # 03 logger sink a1.sinks.k1.type = logger # 04 channel,memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 05 bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
3、启动各个节点上的flume agent
启动Collector1
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
启动Collector2
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
启动上游的Agent
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-loadbalance-client.properties --name a1 -Dflume.root.logger=INFO,console
注意:需要先将下游的Collector节点启动,再启动Agent;否则Agent启动,但下游Collector没有启动,Agent会发现没有可用的下游节点,从而产生报错
4、故障模拟
1) 故障前,向Agent所在机器的log文件,通过管道的形式追加数据,看看event是否轮询的发往了Collector1, Collecotor2
Agent上追加如下数据
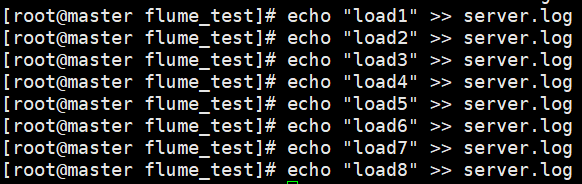
Collector1接收并打印到Console的Event (2,4,7)

Collector2接收并打印到Console的Event (1,4,5,6,8)

总结: Flume的round_robin分发,如果是小测试集,分发结果并不是严格的round_robin. 会出现某些节点被分发的次数多,某些节点被分发的次数少的情况
2)模拟故障,将Collector1的进程kill
3)再次在Agent上进行数据追加,查看此时event是否全部分发给Collector2

Collector2此时接收全部event, 并打印到Console

注意1个细节
当Collector1故障的时候,Agent发送event时会提示1个Sink不可用,并尝试下一个Sink进行Event发送

4) 恢复Collector1, 查看Event此时的分发结果
Agent上追加数据

Collector1分发得到的数据

Collector2分发得到的数据

5、负载均衡场景下的官方配置参考


