
03_Flume多节点Failover实践
1、实践场景
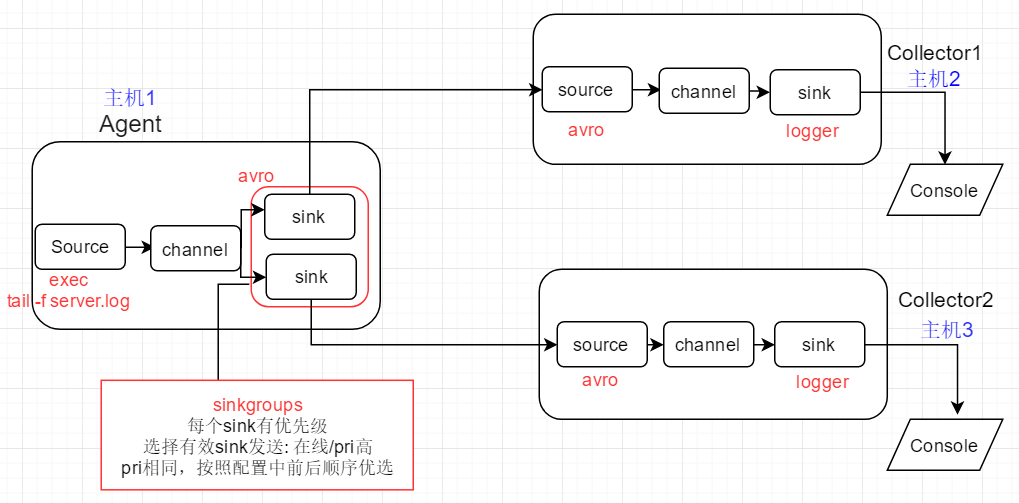
模拟上游Flume Agent在发送event时的故障切换 (failover)
1)初始:上游Agent向active的下游节点Collector1传递event
2)Collector1故障: kill该进程的方式来模拟, event此时发送给Collector2,完成故障切换
3)Collector1恢复:重新运行该进程,经过最大惩罚时间后,event将恢复发送给Collector1
2、配置文件
Agent配置文件
# flume-failover-client # agent name: a1 # source: exec with given command, monitor output of the command, each line will be generated as an event # channel: memory # sink: k1 k2, each set to avro type to link to next-level collector # 01 define source,channel,sink name a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2 # 02 define source a1.sources.r1.type = exec a1.sources.r1.command = tail -f /root/flume_test/server.log # 03 define sink,each connect to next-level collector via hostname and port a1.sinks.k1.type = avro a1.sinks.k1.hostname = slave1 # sink bind to remote host, RPC(上游Agent avro sink绑定到下游主机) a1.sinks.k1.port = 4444 a1.sinks.k2.type = avro a1.sinks.k2.hostname = slave2 # sink band to remote host, PRC(上游Agent avro sink绑定到下游主机) a1.sinks.k2.port = 4444 # 04 define sinkgroups,only 1 sink will be selected as active based on priority and online status a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = failover # k1 will be selected as active to send event if k1 is online, otherwise k2 is selected a1.sinkgroups.g1.processor.priority.k1 = 10 # 基于优先级进行选择,优先级高的被选中active; 优先级相同则根据k1,k2出现的先后顺序进行选择 a1.sinkgroups.g1.processor.priority.k2 = 1 # failover time,milliseconds # if k1 is down and up again, k1 will be selected as active after 1 seconds a1.sinkgroups.g1.processor.priority.maxpenality = 1000 # 回切时间 # 05 define channel a1.channels.c1.type = memory # number of events in memory queue a1.channels.c1.capacity = 1000 # number of events for 1 commit(commit events to memory queue) a1.channels.c1.transactioncapacity = 100 # 06 bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
Collector1配置文件
# 01 specify agent,source,sink,channel a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 02 avro source,connect to local port 4444 a1.sources.r1.type = avro # 下游avro source绑定到本机,端口号要和上游Agent指定值保持一致 a1.sources.r1.bind = slave1 a1.sources.r1.port = 4444 # 03 logger sink a1.sinks.k1.type = logger # 04 channel,memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 05 bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Collector2配置文件
# 01 specify agent,source,sink,channel a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 02 avro source,connect to local port 4444 a1.sources.r1.type = avro # 下游avro source绑定到本机,端口号要和上游Agent指定值保持一致 a1.sources.r1.bind = slave2 a1.sources.r1.port = 4444 # 03 logger sink a1.sinks.k1.type = logger # 04 channel,memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 05 bind source,sink to channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
3、启动Collector1,2 以及Agent
启动Collector1
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
解读:根据当前目录下的conf目录中的flume-failvoer-server.properties配置文件启动flume agent; agent名称为a1;
flume向终端打印INFO级别及以上的日志信息
启动Collector2
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
启动Agent
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-client.properties --name a1 -Dflume.root.logger=INFO,console
注意:
1)要先启动下游Collector,再去启动Agent; 否则Agent启动后就会进行下游有效站点的选择,此时Collector如果还没有启动,则会出现报错

2)3个Agent正常启动后, Agent会建立和所有下游站点的连接: 经历 open -> bound -> connected 三个阶段


4、故障模拟及恢复
1) 故障发生前: 首先向log文件,管道方式添加数据,查看event是否在Collector1的终端被打印
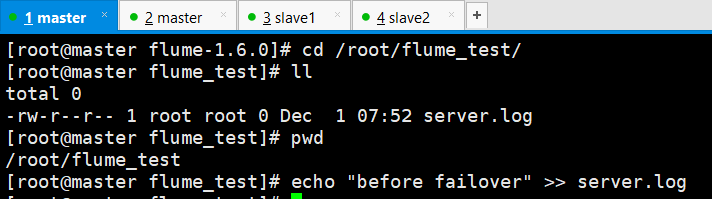
Collector1所在的Slave1节点收到并向终端打印event

2) 故障模拟: kill collector1进程
3)再次尝试发送数据

Collector2所在的Slave2节点收到并向终端打印event

与此同时,Agent将一直尝试重新建立和Collector1的连接

4)重新启动Collector1进程,模拟故障恢复
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
5)向log中再次追加数据,查看event是否重新被发送给collector1, 并被打印到终端

此时Collecot1收到并打印事件 (回切时间在Agent的配置中设置为1秒)

6) 考虑所有下游节点全部down掉,之后下游节点恢复的情况,数据最终给谁?
由于Flume有基于event的事务机制,当下游节点全部down掉时,Flume会将event保留在channel中
当下游节点重新恢复,Agent会再次进行active节点选择,然后将evnet再次发送
当下游节点收到event后,Agent才将event从channel中移除
如果是Collecotr2先恢复, 则event会发送给Collector2; 并且Collecot1之后并不会收到发给Collector2的数据,因此event此时已经从Agent的channel中被移除

