
01_Flume基本架构及原理
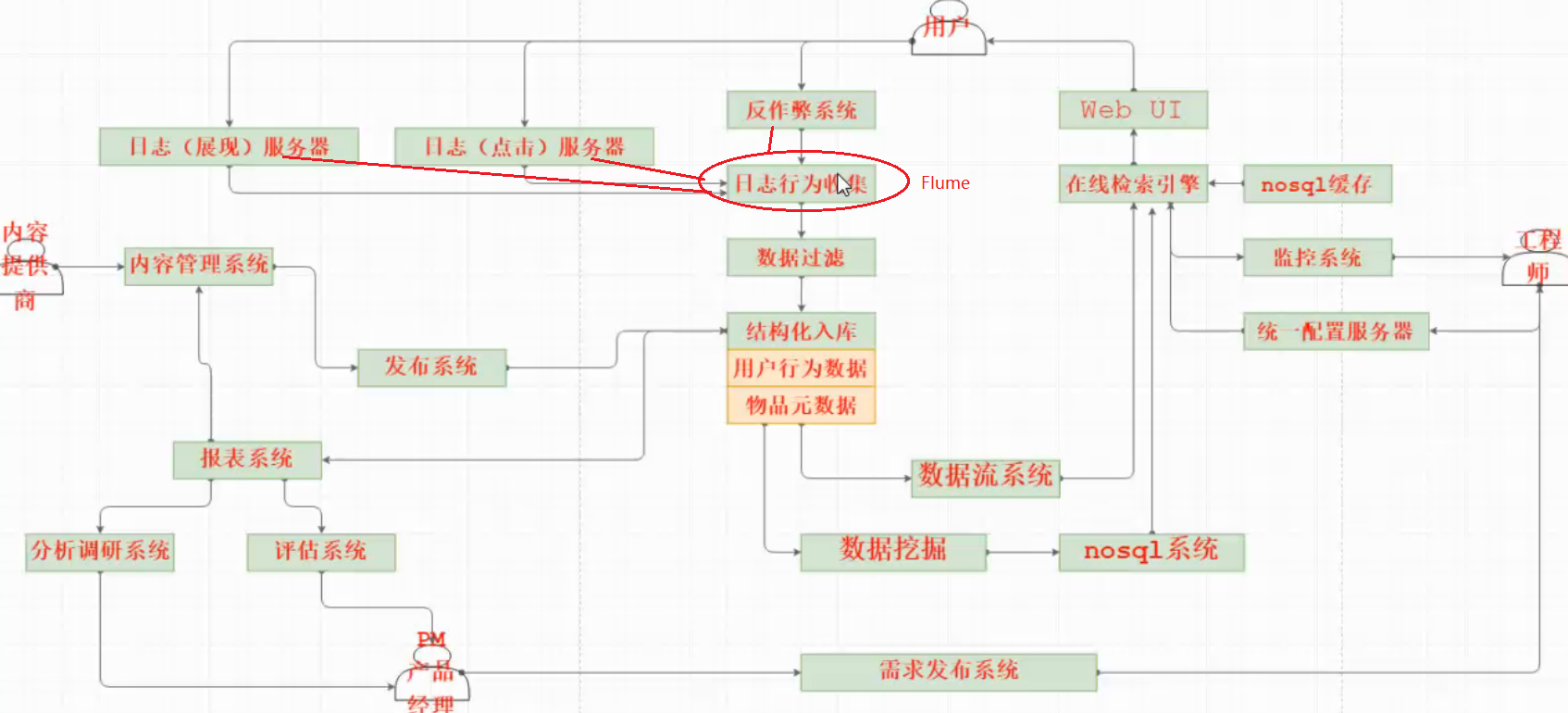
Flume消息收集系统,在整个系统架构中的位置
Flume概况
1) Apache软件基金会的顶级项目
2)存在两个大的版本:Flume 0.9.x(Flume-OG,original generation), Flume 1.x(Flume-NG,next generation)
3) 信息采集系统(分布式,支持水平扩展,事务机制保证消息event可靠传输,可定制的信息输入和信息输出,基于Java运行)
事务机制:下游agent将信息成功缓存后,上游agent才认为该信息传输成功
4)主要目的:deliver data from application to Apache Hadoop's ecosystem(HDFS,HBASE,HIVE,LocalFileSystem)
多管道接入(fan in),多管道输出(fan out),上下文路由(将event根据需求发送给不同的接收方)
5)运行环境:基于java编写,运行在unix-like系统(Ubuntu,CentOS, RHEL,SLES,Mac OS X)
数据从产生到进入分析阶段的整个流程
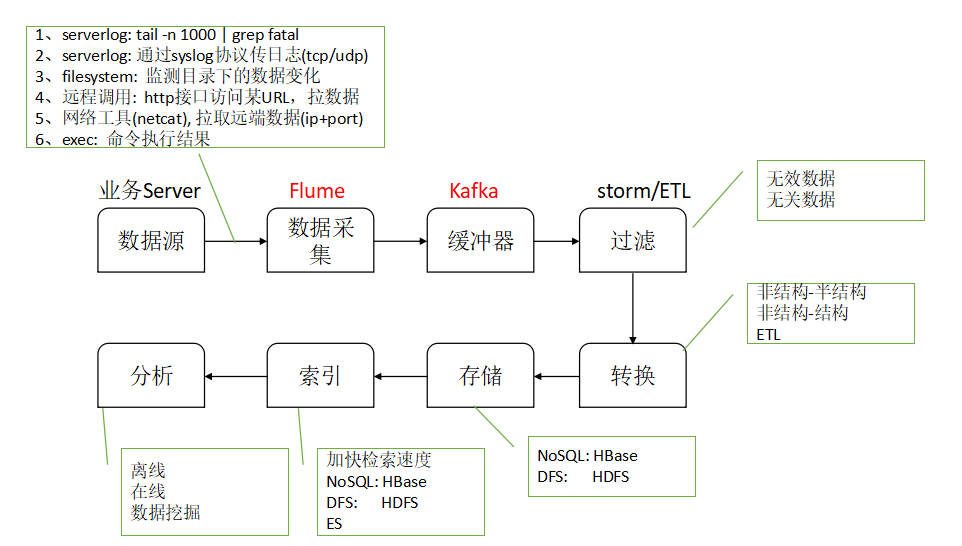
Flume的输入数据和输出数据

Flume架构
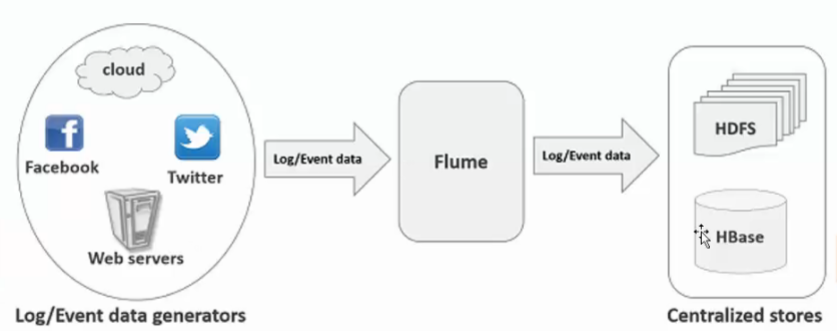
打开Flume来看

一般来说,Agent和Collector分离部署:
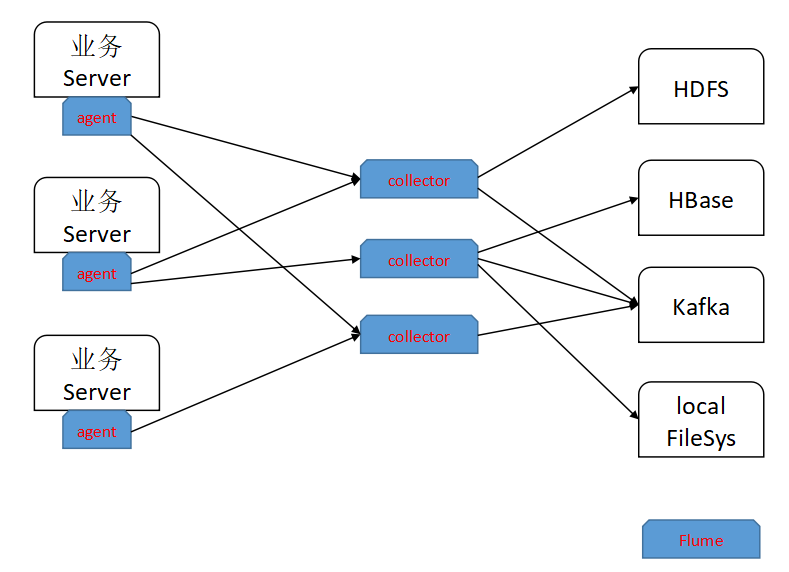
1)业务Server,只部署Agent, 尽量少的入侵业务系统
2)Collector可能会有多个,负责event汇聚的分发
3)Agent layer, Collector Layer, Storage Layer
打开Agent或者collector来看
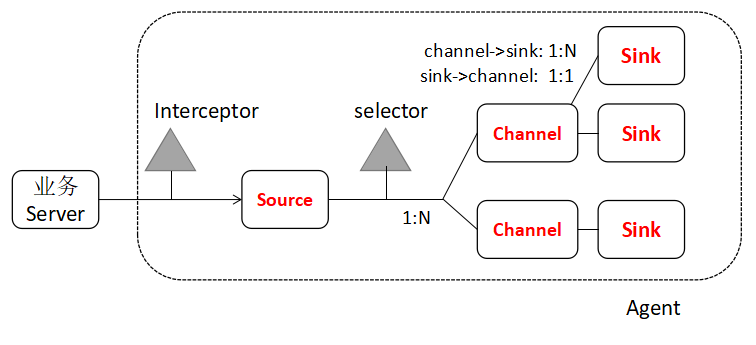
Agent或者Collector由3个必要组件,2个可选组件构成,Event是组件间的数据传递单位
1个Agent或者Collector,就是1个JVM进程
必要组件
1)Source:对接各种输入数据源(数据源直接发送event,或者Source将数据转换为event,Event由可选的Header和Byte净荷构成)

2) Channel:缓存event,直到event被Sink成功发送
最常用的是 memory(内存队列)和 file(本地文件),其他类型的channel还包括jdbc channel,kafka channel等
memory channel最大的问题是可能存在event丢失的风险,file可以持久化存储event但肯定就没有内存队列快
3) Sink: 将event送给下游Agent,或者将event送给下游存储
Agent间的级联,上游Sink必须为avro sink, 下游Source必须为avro source
可选组件
interceptor:干预器,主要用于向Event Header中注入一些附加信息(时间戳,主机信息,自定义信息,由于上下文路由)或者信息过滤(匹配正则的Event放行,匹配正则的Event丢弃)
1) timestamp interceptor: 在event的header中添加时间戳(处理该event的即时时间)
2) host interceptor: 在event的header中添加当前agent运行的主机的hostname或者IP地址
3) static interceptor: 在event的header中添加配置文件中指定的key,value
4) Regex Filtering: 将event的body中的内容和指定的正则表达式匹配,将匹配的event丢弃
5) Regex Extractor: 将event的body中的内容和指定的正则表达式匹配,将匹配的event放行,并添加header(指定的key, value为匹配的内容)
总结:interceptor可以级联,配置文件中通过空格分隔,前一个interceptor处理后的event,是后一个interceptor的输入event
selector: 选择器,主要用于选择Event将发往哪一个Channel(路由)
selector将event发送给channel有两种方式:复制Replicating(全部都发,默认方式), 复用Multiplexing(根据一定规则分发);
复用分发原理:selector根据event header中指定key的值来决定该event应该发给哪一个channel
Flume可靠性信息传递的原理(上下游协同,事务处理)
简单来说:下游agent将event成功缓存到channel后,上游agent才认为该event传输成功, 然后上游将该event从channel中删除
Flume的级联
1)多Agent级联

2) 多个Agent聚合级联
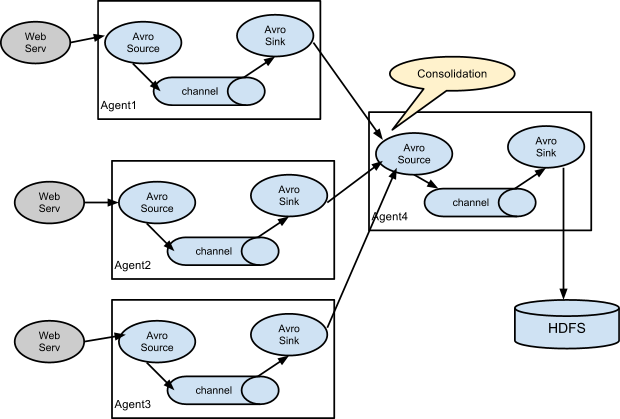
3) 复用分流


