
C++11入门
文章目录
1. C++11简介
链接:C++11官方文档
C++11是C++的一次重大更新,它新增了许多现代高级语言特性:自动类型推导、智能指针、lambda表达式…
本文只对C++11的部分基本特性作介绍,以上特性均在后续博客中。
C++标准委员会是一个妥妥的“鸽王”,在2003年,C++11的预命名是C++07,然而在2006年委员会觉得肯定完成不了,于是将命名改为C++0x,表示在2010年之前发布。然而2010年重蹈覆辙,直到2011年才“顺利”发布C++11标准。
C++11(C++ 2.0)新特性包括语言和标准库两个层面。C++11标准库的头文件可以不带.h,例如:<cstdio>,同时也兼容C语言风格。
2. 列表初始化
C++98标准:允许使用{}对数组或结构体中成员进行初始化:
struct Person
{
int age;
string name;
};
main()
{
// 对数组
int arr1[] = { 1,2,3 };
int arr2[3] = { 0 };
// 对结构体成员
Person p = { 18, "小明" };
return 0;
}
C++11标准:除了自定义类型之外,内置类型也可以用列表初始化,也可以不加上赋值符号:
int a1 = { 1 };
int a2{ 2 };
int array1[]{1, 2, 3 };
int array2[3]{0};
也可以用在new表达式中,但{}和new搭配使用就不能再加赋值符号了,因为前面已经有一个了:
int* p1 = new int[3]{ 0 };
int* p2 = new int[3]{ 1,2,3 };
实际上列表初始化就是调用对应类型的构造函数。
2.1 initializer_list
官方文档:initializer_list

initializer_list是一个初始化容器,它存储的数据会被用于初始化其他容器。这是C++11实现列表初始化的前提,这也是C++98不支持列表初始化的原因。
例如,使用初始化列表实例化一个数组,然后查看它的类型:
int main()
{
auto a = {1, 2, 3};
cout << typeid(a).name() << endl;
return 0;
}
输出:
class std::initializer_list<int>
从它的接口数量和功能来看,它就是一个临时容器。它不是专门用于存储数据的,它的名字已经说明了它的作用。
所有类型都支持它构造对象。本来是构造一个匿名对象,然后再调用构造函数,但是编译器优化后直接调用构造函数,然后隐式类型转换。
例如在C++11版本的vector容器构造函数中就增加了初始化列表为参数:
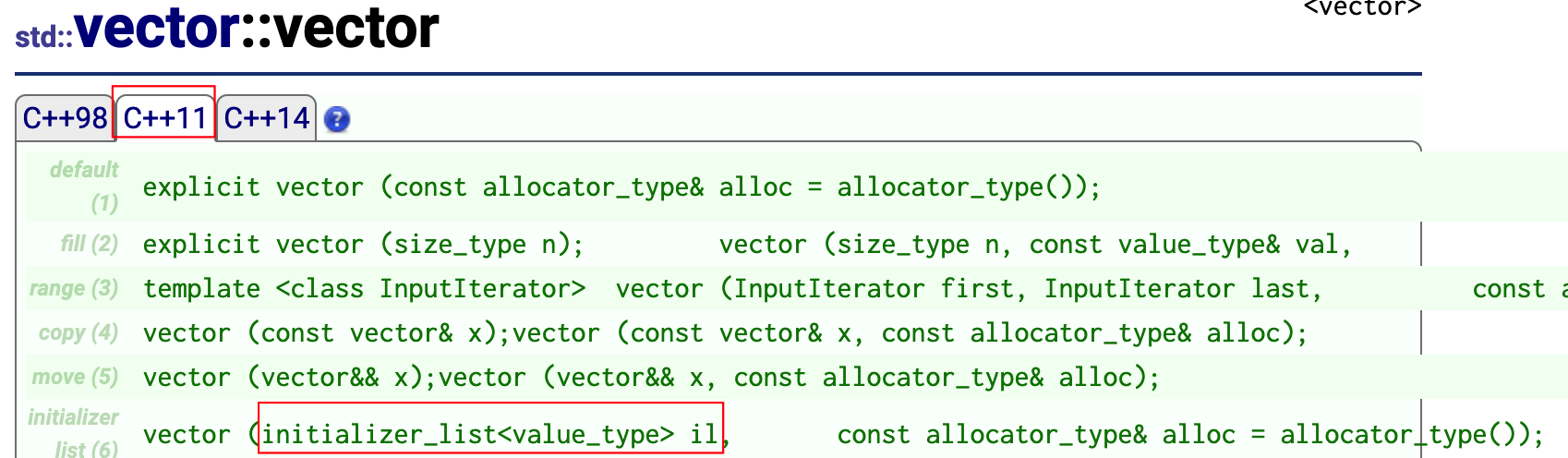
那么对于vector、map这样的多参数容器,就可以使用{}进行列表初始化构造对象。当用列表对容器进行初始化时,这个列表({}中的内容)被编译器推导成initializer_list类型,然后调用这个新增的构造函数对该容器进行初始化。这个新增的构造函数要做的就是遍历initializer_list中的元素,然后将这些元素依次插入到要初始化的容器中即完成初始化容器。
那么,针对我们自定义类型,要实现列表初始化的前提就是重载参数为initializer_list的构造函数。
2.2 小结
C++11推出的列表初始化虽然可以适用于所有类型,但是依然建议普通对象按照原有方式初始化,另有需要的容器可以使用更方便的列表初始化。例如list容器本push比较麻烦,就可以使用列表初始化。
3. 声明
C++11推出了多种简化声明的方式。
3.1 auto
auto原本是C++98的一个关键字,它原本的功能是声明变量为自动变量。「自动变量」拥有「自动的生命周期」,然而就算不使用auto声明变量,变量依旧拥有自动的生命周期:
int a = 0; // 拥有自动生命周期
auto int b = 1; // 拥有自动生命周期
static int c = 2; // 延长生命周期
auto声明变量并没有改变变量的生命周期,因为生命周期取决于变量何时创建和销毁,而这已经被默认确定了。它是变量的默认属性。因此C++11赋予auto以新的意义:自动类型推断。
要知道,在定义一个变量或实例化一个对象时,都要明确指明变量或对象的类型,假如这个变量或对象的类型比较长,或者忘记对象的名字且仍然记得这个对象的实例化方式,就可以使用auto关键字以自动推断变量或对象的类型。
int main()
{
int b = 1;
auto pb = &b;
cout << typeid(b).name() << endl;
cout << typeid(pb).name() << endl;
return 0;
}
输出:
int
int *
而且auto的使用还能避免出现类型不合适的情况:
int main()
{
short a = 32767;
short b = 32767;
auto c = a + b;
cout << typeid(c).name() << endl;
return 0;
}
输出:
int
如果在定义变量时忽略了它的范围,那么很有可能出现范围小的变量装不下的情况。
typeid能得到变量的类型,那么它能不能定义变量呢?
答案是否定的,如果想得到变量类型的同时,定义相同类型的变量,可以使用decltype关键字。
3.2 decltype
- 关键字decltype可以将变量的类型声明为表达式指定的类型。
int main()
{
int a = 0;
decltype(a) b = 1;
cout << typeid(b).name() << endl;
return 0;
}
输出:
int
decltype还能推断表达式的类型:
template<class T1, class T2>
void func(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}
int main()
{
int x = 1;
double y = 0.1;
decltype(x * y) ret;
decltype(&x) px;
cout << typeid(ret).name() << endl;
cout << typeid(px).name() << endl;
func(1, 0);
func(1, 0.2);
return 0;
}
输出:
double
int *
int
double
推演函数返回值的类型:
int* func(int x)
{
return (int*)x;
}
int main()
{
cout << typeid(func).name() << endl;
cout << typeid(func(1)).name() << endl;
return 0;
}
输出:
int * __cdecl(int)
int *
注意:
__cdecl(int)表明仅为函数名,不包含括号和参数;- 如果包含参数列表和括号,推导的是函数的返回值类型,且并不会调用函数。
还可以指定函数的返回类型(本部分需要结合后面的内容):
template<class T1, class T2>
auto Add(T1 t1, T2 t2)->decltype(t1 + t2)
{
decltype(t1 + t2) sum;
sum = t1 + t2;
cout << typeid(sum).name() << endl;
return sum;
}
int main()
{
cout << Add(1, 1) << endl;
cout << Add(1, 1.1) << endl;
return 0;
}
输出:
int
2
double
2.1
其中,auto Add(T1 t1, T2 t2)->decltype(t1 + t2)表示auto返回值的类型是decltype(t1 + t2)。
3.3 nullptr
在C语言中,NULL是一个空指针:
#define NULL ((void *)0)
它的类型是void*
然而在C++中NULL被定义为0:
/* Define NULL pointer value */
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else /* __cplusplus */
#define NULL ((void *)0)
#endif /* __cplusplus */
#endif /* NULL */
原因是C++不支持void*隐式转换成其他指针类型,因而void*类型在C++中就起不到空指针的作用:
int main()
{
void* x = (void*)0;
char* a = x; // 欲将 void*->char*
return 0;
}
C++中会出现这样的错误:

将源文件重命名为.c文件,则编译通过。
C++引进nullptr关键字的原因是:在极端情况下,函数重载的调用会因为NULL的字面值0而发生匹配错误:
void func(char* c)
{
cout << "func(char* c)" << endl;
}
void func(int c)
{
cout << "func(int c)" << endl;
}
int main()
{
func(NULL);
return 0;
}
输出:
func(int c)
显然,调用func函数的参数NULL已经表明了我们想调用的是参数为char*的函数,然而事实并非如此。原因是源文件在编译链接的时候会进行宏替换,NULL会被替换为它的字面值0,在编译器眼里,这个调用就是这样的:
func(0);
调用void func(int c)也就不难理解了。
C++为了解决这样的匹配问题,将nullptr作为空指针关键字。
注意,这是NULL和nullptr本质上的区别:
NULL是一个宏,它的值是0;nullptr是C++中的关键字。
4. 范围for
4.1 使用
范围for的使用能让我们更方便地遍历元素。
for循环后的括号由冒号分为两部分:
- 用于接收每个元素的变量
- 迭代的范围
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
for (int e : arr)
{
cout << e << " ";
}
cout << endl;
return 0;
}
for (int e : arr)表示遍历整个arr数组,并用一个int类型的变量接收每个元素。
范围for常与auto关键字结合使用:
for (auto e : arr)
如果遇到比较大的变量,可以使用引用接收以减少临时拷贝的开销:
for (auto& e : arr)
4.2 使用条件
- 范围确定:对于数组,它的长度需要明确;对于类,需要提供begin和end迭代器。因为范围for本质上就是使用迭代器遍历元素。
- 迭代的对象要支持++和==操作:原因同上,因为范围for本质就是使用迭代器,所以要遍历元素,就要支持++,要停下来,就要支持==
5. STL新容器
C++11中新增了四个容器:array、forward_list、unordered_map和unordered_set。
5.1 array
本质是一个静态数组,和原生的静态数组 区别不同的是它对越界访问检查十分严格,因为底层上array是用断言检查的,而原生数组并没有对每个空间检查,而是设定哨兵位。
array容器的operator[]接口如果发现有越界情况发生,会调用at接口抛出异常。
而且array容器的对象是创建在栈上的,因此array容器不适合定义太大的数组。而且人们已经习惯使用原来的数组,而且如果要保证安全性,vector足矣,因此它并没有被广泛使用。
5.2 forward_list
本质是一个单链表,没有被广泛使用。、
原因是:
- 它只支持头插,因此尾插尾删时需要先找尾,时间复杂度为O(N);
- 它只支持在指定元素后面插入,接口名为
insert_after,如果要在元素前面插入元素,还要遍历整个链表,时间复杂度为O(N); - 它只支持在指定元素后面删除,接口名为
erase_after,原因同上,时间复杂度为O(N)。
5.3 unordered_map和unordered_set
它们底层使用和哈希表,因此查找效率非常高,可以认为是O(1),是查找效率最高的数据结构。
作者曾经的文档:
unordered_set和unordered_map的使用【STL】
用同一个哈希表实现unordered_map和unordered_set(C++实现)【STL】
5.4 字符串转换
C++11补充了string类型和内置类型相互装换的接口,最常用的有:to_string,其次是stoi、stol、stod等。
- 内置类型转换为string
官方文档:std::to_string
- string转换成内置类型
官方文档:Convert from strings
C++11为每个容器都增加了一些新接口,例如:
- 提供了一个以initializer_list作为参数的构造函数,用于支持列表初始化;
- 提供了cbegin和cend方法,用于返回const迭代器;
- 提供了emplace系列方法,并在容器原有插入方法的基础上重载了一个右值引用版本的插入函数,用于提高向容器中插入元素的效率。
关于右值引用等,是C++11最重要的特性,会在后续文档中着重介绍。
- 内置类型转换为string
官方文档:std::to_string
- string转换成内置类型
官方文档:Convert from strings
C++11为每个容器都增加了一些新接口,例如:
- 提供了一个以initializer_list作为参数的构造函数,用于支持列表初始化;
- 提供了cbegin和cend方法,用于返回const迭代器;
- 提供了emplace系列方法,并在容器原有插入方法的基础上重载了一个右值引用版本的插入函数,用于提高向容器中插入元素的效率。
关于右值引用等,是C++11最重要的特性,会在后续文档中着重介绍。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程