从TiDB学习分布式数据库
因为最近在做TiDB的一个hackthon,需要先对TiDB架构有个了解,然后再确定选题方向,进行方案设计;
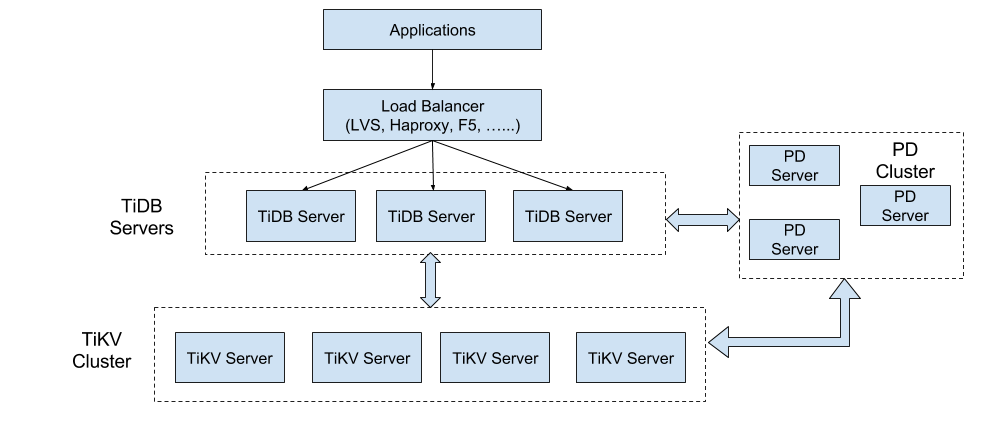
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。
1.KV分布式存储引擎
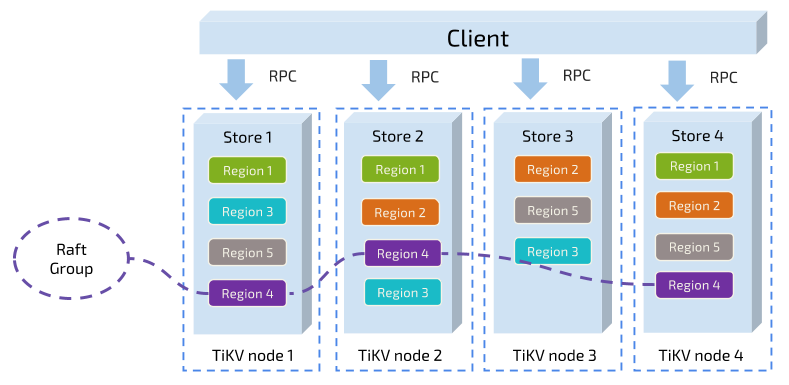
TiKV的底层是使用RockDB构建的,基于Raft 协议的进行分布式存储。分区分块存储,其中一个重要的概念就是“Region”
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
- 以 Region 为单位做 Raft 的复制和成员管理
2.关系模型到Key-Value模型的映射
1) 映射关系:
输入的SQL,是如何映射到Key-Value模型进行存储的呢?
对于一个 Table 来说,需要存储的数据包括三部分:
- 表的元信息
- Table 中的 Row
- 索引数据
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID);
其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。 每行数据按照如下规则进行编码成 Key-Value pair:
Key: tablePrefix_rowPrefix_tableID_rowID
Value: [col1, col2, col3, col4]
2) 分布式SQL运算
一个查询语句是如何操作底层存储的数据。 能想到的最简单的方案就是通过上一节所述的映射方案,将 SQL 查询映射为对 KV 的查询,再通过 KV 接口获取对应的数据,最后执行各种计算。
首先需要将计算尽量靠近存储节点,以避免大量的 RPC 调用。其次,需要将 Filter 也下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输。最后,我们可以将聚合函数、GroupBy 也下推到存储节点,进行预聚合,每个节点只需要返回一个 Count 值即可,再由 tidb-server 将 Count 值 Sum 起来。
3、分布式系统的调度
作为一个分布式高可用存储系统,必须满足的需求,包括四种:
- 副本数量不能多也不能少
- 副本需要分布在不同的机器上
- 新加节点后,可以将其他节点上的副本迁移过来
- 节点下线后,需要将该节点的数据迁移走
作为一个良好的分布式系统,需要优化的地方,包括:
- 维持整个集群的 Leader 分布均匀
- 维持每个节点的储存容量均匀
- 维持访问热点分布均匀
- 控制 Balance 的速度,避免影响在线服务
- 管理节点状态,包括手动上线/下线节点,以及自动下线失效节点
参考资料:
https://pingcap.com/blog-cn/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号