Java进阶之内存模型
一张常见的图,java虚拟机运行时数据区:
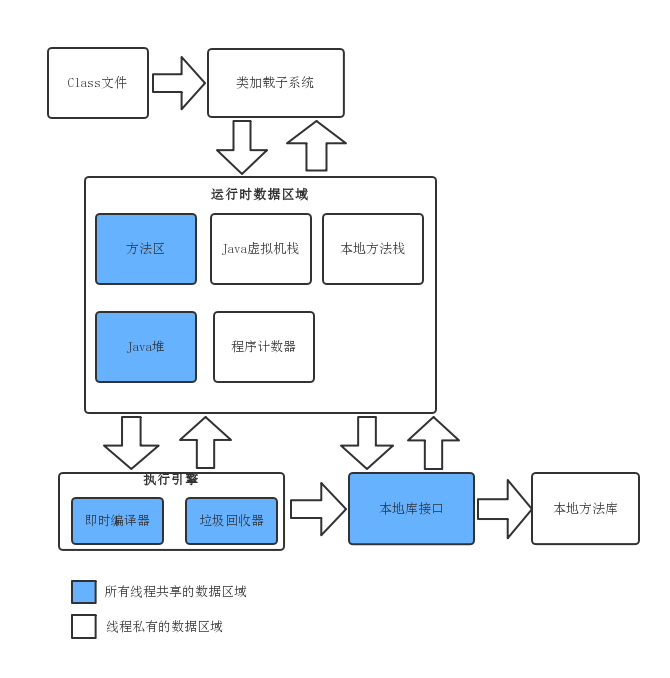
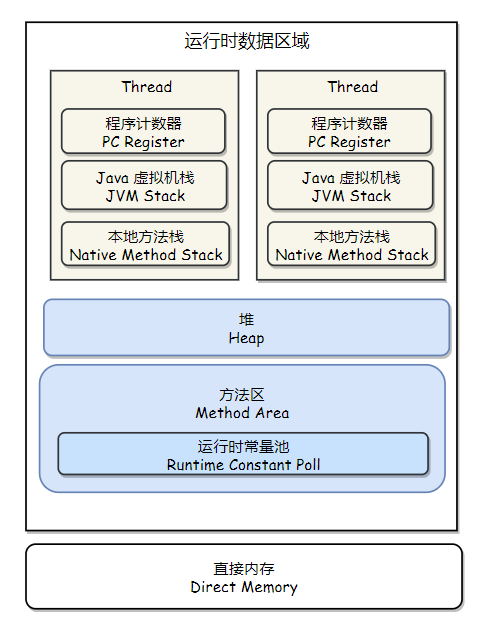
一、虚拟机栈和本地方法栈
虚拟机栈: 虚拟机为每个方法所创建的栈帧,用于存储每个方法的局部变量表、操作数栈等信息。每一个方法从调用到执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
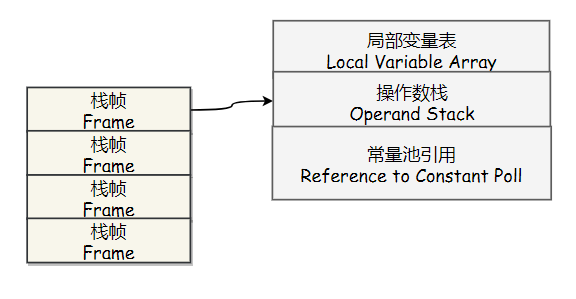
本地方法栈:native方法 => 本地方法不是用 Java 实现,对待这些方法需要特别处理。与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。

二、堆
是java对象的主要存储区域。该区域要实现自动内存管理,并被所有线程所共享。
所有的对象都在堆里分配内存。
java栈与堆怎样联系起来的?
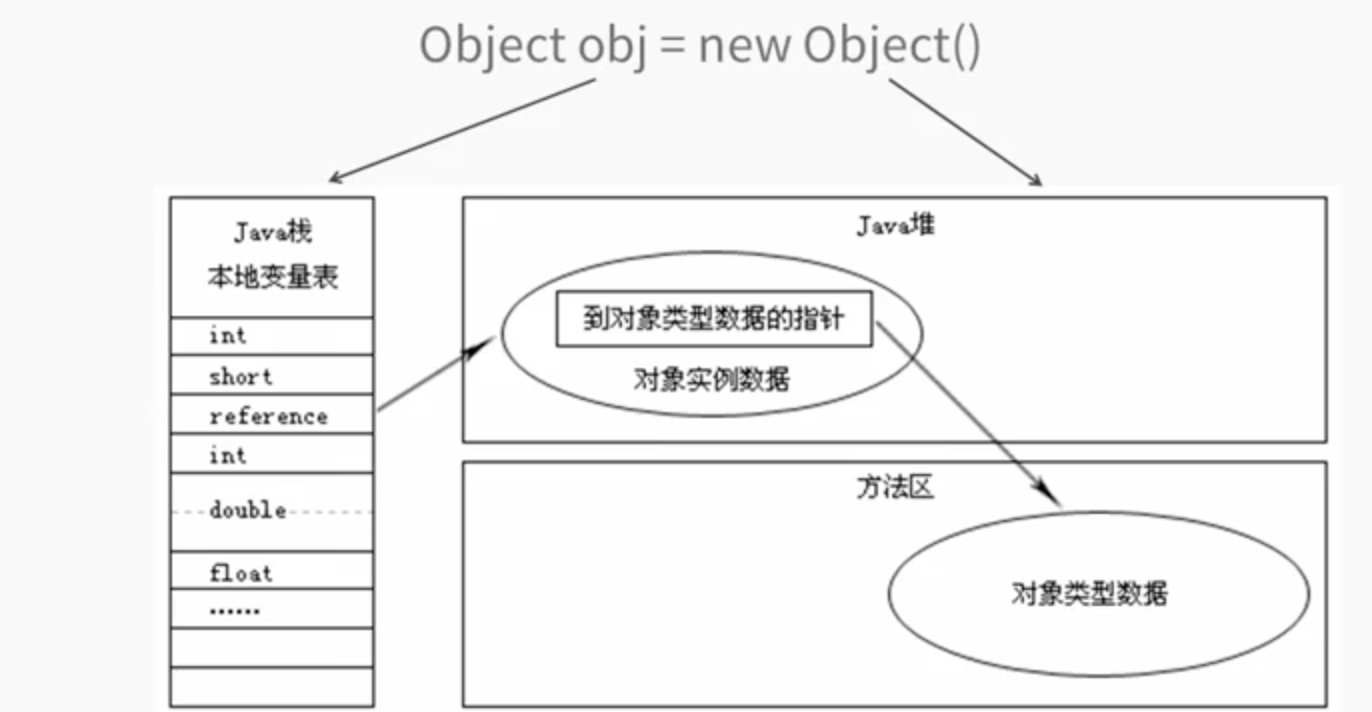
可以看见当执行Object obj = new Object()时,在栈的本地变量中一定要有一个引用存在一个obj的引用,new在堆上创建对象,并分配内存,并将该对象的引用复制给本地变量的obj,obj是一个引用类型。
java中对象的访问机制,一般有使用句柄和直接指针两种方法。
三、方法区和运行时常量池
被所有线程共享,主要存储Java的类结构信息,常量、静态变量。
四、对象判断和回收算法
回收过程:
真正宣布一个对象死亡,需要经过两次回收标记:
1)可达性分析:如不可达,则标记;
2)gc对f-queue中的对象进行第二次标记,如果此时该对象与任何引用链上的对象建立起了关系,则对象活了过来;反之,被第二次标记了,则对象会被真正回收
如下代码很好的演示了这一过程:
垃圾收集算法:
1)标记-清除算法:问题:效率问题:效率低,空间问题:大量内存碎片
2)复制算法:回收新生代=>将内存区域划分为几块
3)标记-整理算法:回收老年代=>让所有存活的对象都向一边移动,然后直接清理掉边界以外的内存
3)分代收集算法: 将内存区域划分为几块,一般现在都将java堆划分为新生代和老生代,可以根据各个年代采用合适的算法: 新生代(对象存活时间短,大量对象死去)=>复制;老生代(对象存活时间长)=>标记-整理
垃圾收集器:(分代收集的思想来管理内存)
垃圾收集器有很多种,现在B/S系统上最常用的是CMS(Concurrent Mark Sweep) 和 G1(Garbage-First),它真正实现了垃圾回收线程和用户线程的并发执行,效率很高。
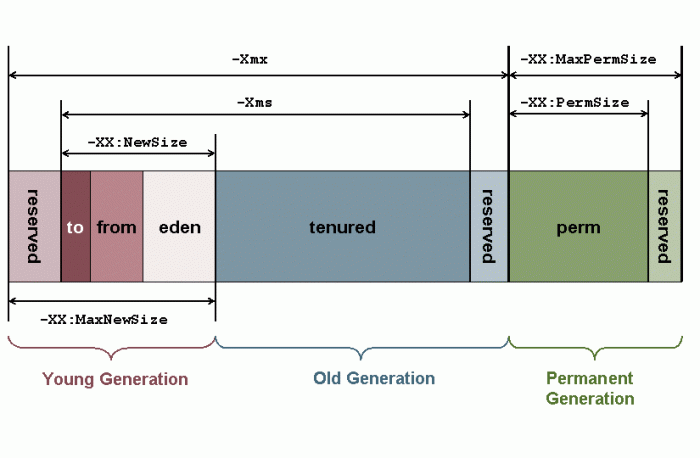
虚拟机把 Java 堆分成以下三块:
- 新生代(Young Generation)
- 老年代(Old Generation)
- 永久代(Permanent Generation)
当一个对象被创建时,它首先进入新生代,之后有可能被转移到老年代中。
新生代存放着大量的生命很短的对象,因此新生代在三个区域中垃圾回收的频率最高。为了更高效地进行垃圾回收,把新生代继续划分成以下三个空间:
- Eden(伊甸园)
- From Survivor(幸存者)
- To Survivor
五、java内存模型
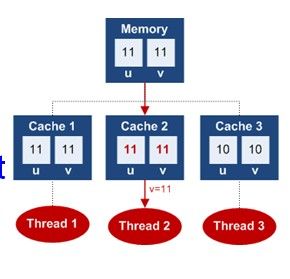
1. cpu的多级缓存
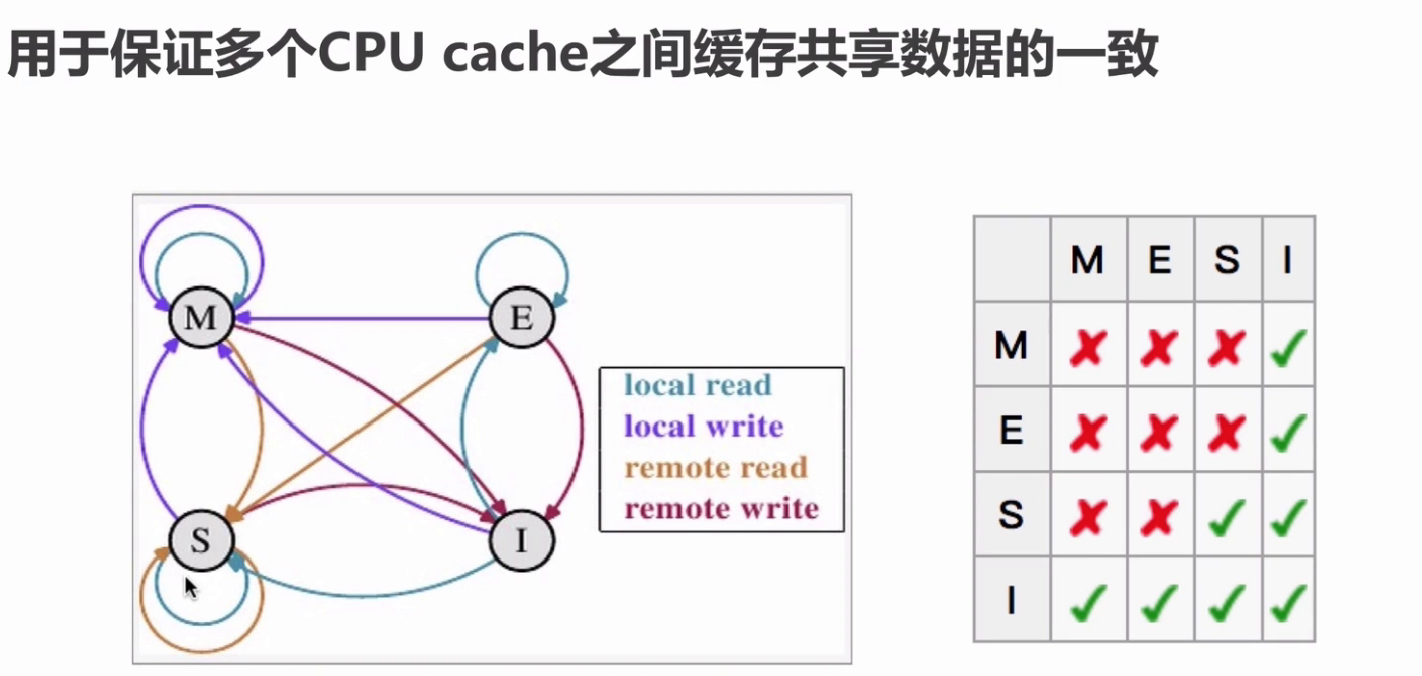
在看java内存模型之前,让我们先看看cpu的多级缓存与cpu的缓存一致性(MESI)
2. java内存模型
java将内存分为主内存和工作内存。这样的区分和堆、栈、工作区是不同层次的区分,二者并没有可比性更无所谓交集。
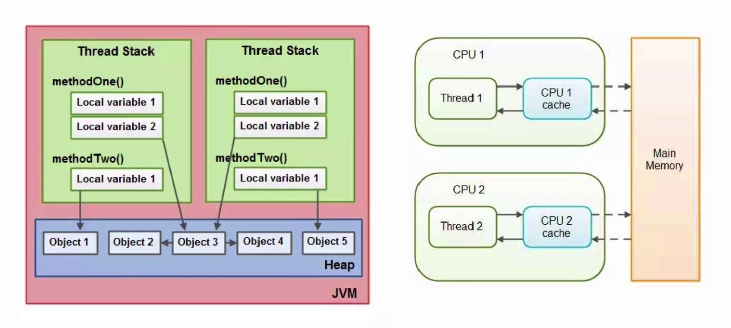
当不同栈上的方法访问同一个对象引用时,它们就分别获得了这个变量的局部拷贝,存储在各自线程所在cpu的缓存中,然后由缓存刷到主内存中;
java的内存模型主要是为了定义程序中各个变量的访问规则。即弄清楚变量怎么将变量存储到内存和将变量从内存中取出。注意这里所说的变量是指实例字段、静态字段和构成数组对象的元素,但并不包括局部变量和方法参数(因为这些是线程私有的,存储在虚拟机栈中)。
硬件效率:将运算需要用的数据复制到缓存中,让运算能快速进行,运算结束再复制回主存中,这样处理器就不用等待缓慢的内存读写了。所以其实java的内存模型就是缓存和主存交互的过程抽象。
这两张图对比,其实就可以看出主内存就相当于内存,而各线程各自的工作内存就相当于cache。主内存中存的是堆中的实例对象数据部分,工作内存则对应虚拟机栈部分。
这张图的结构其实有点类似于分布式,那么分布式一个很重要的问题就是“一致性”的问题。
=> 那么怎么保证各缓存(工作内存)和主存(主内存)之间的一致性呢?
那么必须要有一种“一致性协议”来规定一些读写操作规则。
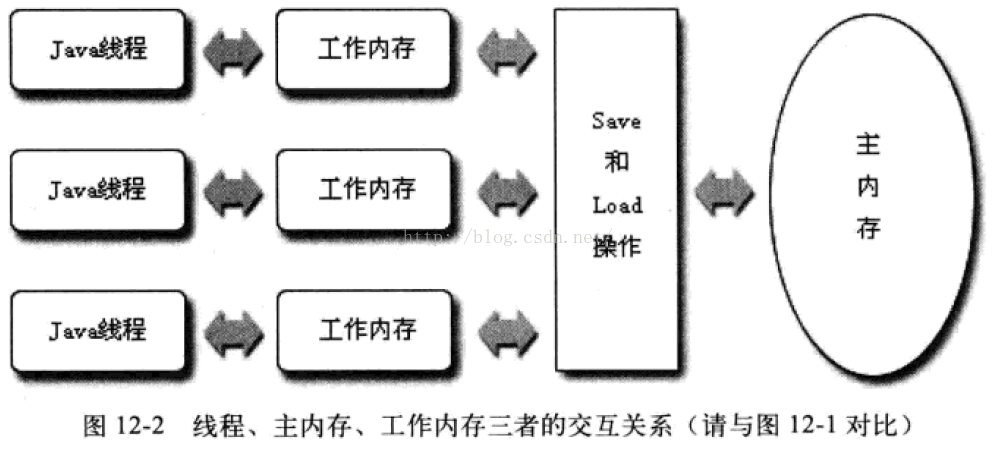
六、java内存模型与线程
java的内存模型中,主存怎么与各线程的工作内存进行交互。这也是多线程并发的基础。只有主存与工作内存遵循了统一交互原则。“一致性协议”
java内存模型中的工作内存是cpu的寄存器和高速缓存的一个抽象描述,存储着主存中数据的临时拷贝;
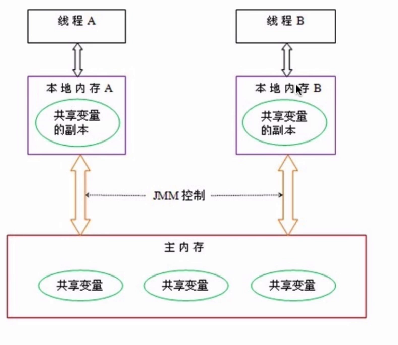
如上图所示,如果两个线程对主内存不可见,则可能存在问题;所以应当由jmm在刷新到主内存时设置一个内存屏障;控制可见性
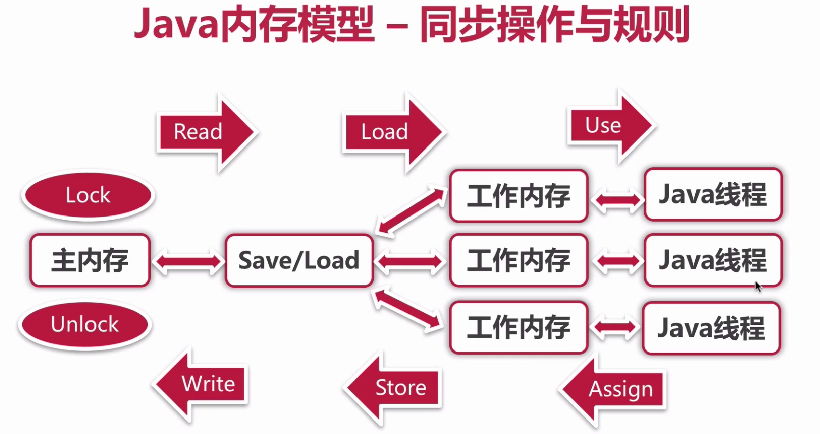
七、同步的八种操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号