

[GeekBand] 面向对象的设计模式(C++)(2)
本篇笔记紧接上篇,继续学习设计模式。
4. 对象创建类设计模式
通过对象创建模式绕开new,来避免对象创建(new)过程中所导致的紧耦合,从而支持对象创建的稳定。它是接口抽象之后的第一步工作。
4.1 Factory Method(工厂方法)
4.1.1 应用场景
在软件系统中,经常面临着创建对象的工作;由于需求的变化,需要创建的对象的具体类型经常变化。
4.1.2 定义与解释
定义一个用于创建对象的接口,让子类决定具体实例化哪个类。Factory Method是的一个类的实例化延迟到子类。(目的是解耦,手段是虚函数)
考虑之前在学习观察者模式的文件分割器例子,通常来讲,我们很可能写出这样的代码:
BinarySplitter * splitter= new BinarySplitter();//依赖具体类 |
声明一个文件分割器的对象,接下来再使用它。但实际上这是不符合"面向接口编程"的,它直接的使用了BinarySplitter具体类进行编程。我们可能会有二进制分割器,文本分割器,视频分割器等等。那我们接下来就会想到,使用一个抽象类接口,然而这样只能部分地消除依赖:
ISplitter * splitter = //不再依赖具体类 new BinarySplitter();//仍然依赖具体类,BinarySplitter不存在时无法编译通过 |
在这种情况下,只要有依赖就仍然做不到解耦。而后边又无法搞成接口类,(接口类无法执行new操作)。这就引入了工厂方法,这是面向接口编程的第一步需求。
工厂方法就是用一个函数来代替new操作,这个函数要能够产生各种不同的分割器,我们就又想到了虚函数(虚函数和继承机制是延迟决定的唯一方法),如下图工厂方法的具体代码,不同的工厂产生不同的分割器:
//工厂基类 class SplitterFactory{ public: virtual ISplitter* CreateSplitter()=0; virtual ~SplitterFactory(){} };
//具体工厂 class BinarySplitterFactory: public SplitterFactory{ public: virtual ISplitter* CreateSplitter(){ return new BinarySplitter(); } };
class TxtSplitterFactory: public SplitterFactory{ public: virtual ISplitter* CreateSplitter(){ return new TxtSplitter(); } }; |
在使用这个分割器的时候,如下面的MFC中的例子:
class MainForm : public Form { SplitterFactory* factory;//工厂 public: MainForm(SplitterFactory* factory){ //利用传入参数来决定用什么文件分割器,这就把"变化"的范围限制在MainForm之外了 this->factory=factory; }
void Button1_Click(){ ISplitter * splitter= factory->CreateSplitter(); //创造性的做出了一个多态的new splitter->split(); } }; |
4.1.3 核心
- Factory Method模式用于隔离类对象的使用者和具体类型之间的耦合关系。 面对一个经常变化的具体类型,紧耦合关系(new)会导致软件的脆弱。
- Factory Method模式通过面向对象的手法,将所要创建的具体对象工作延迟到子类,从而实现扩展(而非更改)的策略,较好地解决了这种紧耦合关系。
- Factory Method模式解决单个对象的需求变化。缺点在于要求创建方法/参数相同
4.1.4 类图
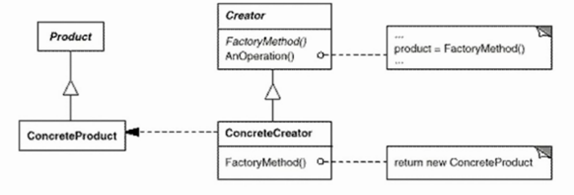
4.2 Abstract Factory(抽象工厂)
4.2.1 应用场景
在软件系统中,经常面临着创建"一系列相互依赖的对象"(和上边的唯一不同就是一系列相互依赖)的工作;由于需求的变化,需要创建的对象的具体类型经常变化。
4.2.2 定义与解释
提供一个接口,让该接口负责创建一系列"相关或相互依赖的对象" ,无需指定它们具体的类。
考虑在软件的层次架构中的数据访问层,需要访问数据库。现在使用的是SQL的数据库,但是以后有可能会使用其他种类的数据库比如Oracle等。我们的想法还是进行面向接口的编程,应用工厂方法之后我们不难写出如下的接口:
//数据库访问有关的基类 class IDBConnection{
}; class IDBConnectionFactory{ public: virtual IDBConnection* CreateDBConnection()=0; }; //支持SQL Server class SqlConnection: public IDBConnection{
}; class SqlConnectionFactory:public IDBConnectionFactory{
}; //支持Oracle class OracleConnection: public IDBConnection{
}; class OracleConnectionFactory: public IDBConnectionFactory {
}; |
但是这种情况下,用户需要手动搭配DBConnection,DataReader存在用户错误的把不同类型的操作拼到一起的问题。
因此我们希望能进一步进项抽象,提取这些工厂的特质,就产生了抽象工厂方法。其实更应该叫做"家族工厂""工厂组"之类,它把不同的操作用同一个工厂类产生,防止了某些用户错误地把不同种类的操作混杂在一起(例如SQL的Command配上Oracle的Reader)。
class IDBFactory{ public: virtual IDBConnection* CreateDBConnection()=0; virtual IDBCommand* CreateDBCommand()=0; virtual IDataReader* CreateDataReader()=0;
};
class SqlDBFactory:public IDBFactory{ public: virtual IDBConnection* CreateDBConnection()=0; virtual IDBCommand* CreateDBCommand()=0; virtual IDataReader* CreateDataReader()=0;
}; |
在使用这个抽象的时候,如下面的例子:
class EmployeeDAO{ IDBFactory* dbFactory;
public: vector<EmployeeDO> GetEmployees(){ IDBConnection* connection = dbFactory->CreateDBConnection(); connection->ConnectionString("..."); IDBCommand* command = dbFactory->CreateDBCommand(); command->CommandText("..."); command->SetConnection(connection); //关联性
IDBDataReader* reader = command->ExecuteReader(); //关联性 while (reader->Read()){ } } }; |
4.2.3 核心
- 如果没有应对"多系列对象构建" 的需求变化,则没有必要使用Abstract Factory模式,这时候使用简单的工厂完全可以。
- "多系列对象"指的是在某一特定系列下的对象之间(就是例子中的command,reader等)相互依赖或作用的关系。 不同系列的对象之间不能相互依赖。
- Abstract Factory模式主要在于应对 "新系列" 的需求变动。 真缺点在于难以应对 "新对象" 的需求变动。
4.2.4 类图

4.3 Prototype(原型)
4.3.1 应用场景
在软件系统中,经常面临着创建"某些结构复杂的的对象"的工作;由于需求的变化,需要创建的对象的具体类型经常变化,但是他们却拥有比较比较一致的接口。
4.3.2 定义与解释
使用一个原型实例指定创建对象的种类,通过复制这个原型创建对象。
仍然考虑文件分割器,我们类比工厂方法。原型模式是一种特殊的创建,通过克隆(复制构造)来进行创建。
//抽象类 class ISplitter{ public: virtual void split()=0; virtual ISplitter* clone()=0; //通过克隆自己来创建对象
virtual ~ISplitter(){}
}; //具体类,直接利用拷贝构造函数进行配置 class BinarySplitter : public ISplitter{ public: virtual ISplitter* clone(){ return new BinarySplitter(*this); } }; |
但是这种情况下,用户需要手动搭配DBConnection,DataReader存在用户错误的把不同类型的操作拼到一起的问题。
在使用这个抽象的时候,如下面的例子。必须强调原型对象尽管已经存在了,但是它不是用来更改的,只能用来复制。(否则不同的操作之间就可能产生影响,相当于原型有了初值。)
class MainForm : public Form { ISplitter* prototype;//原型对象
public: MainForm(ISplitter* prototype){ this->prototype=prototype; //让原型对象指向传过来的原型 } void Button1_Click(){ ISplitter * splitter= prototype->clone(); //克隆原型 splitter->split(); } }; |
4.3.3 核心
- 同样用于隔离类对象的使用者和具体类型(易变类)之间的耦合关系,他同样要求拥有稳定的接口。
- 通过克隆的方式,所需的工作比较简单,仅仅是注册一个新类的对象,然后在任何地方进行克隆。
- 可以利用某些框架中的序列化实现深拷贝。
4.3.4 类图

4.4 Constructor(构建器)
4.4.1 应用场景
在软件系统中,有时面临着创建"一个复杂的的对象"的工作,他通常由各个部分的子对象用一定的算法构成。由于需求的变化,需要创建的对象的各个部分经常变化,但是他们组合在一起的算法却相对稳定。
4.4.2 定义与解释
将一个复杂对象的构建与其表示相分离,使得同样的构建过程(稳定)可以应用于不同的表现形式(变化)。
考虑一个建房子的模型,在建房子的时候,一定是分部分进行构建的,即不同的Part。各个Part内部可能不太一样,但是各个Part之间的过程,组合方法等又是稳定的。这很像模板方法。我们有可能会产生一种想法,将模板方法应用于构造函数,然而实际上是不行的。因为构造函数采用了静态绑定机制,是不可以调用子类的动态绑定的虚函数的。所以我们通常会采用一个Init函数进行构建。
不过这样我们会导致整个House类过于庞大臃肿,而且House建立一次之后就没有必要再调用INIT了,所以我们通常采取的方法是把构造工作和House本身分开。如果构造工作本身还是庞大臃肿,我们可以把HouseBuilder再此拆开。代码重构时要避免臃肿的类。
class House{ //.... };
class HouseBuilder { public: House* GetResult(){ return pHouse; } virtual ~HouseBuilder(){} protected:
House* pHouse; virtual void BuildPart1()=0; virtual void BuildPart2()=0; virtual void BuildPart3()=0; virtual void BuildPart4()=0; virtual void BuildPart5()=0;
};
class StoneHouse: public House{ //具体房子 };
class StoneHouseBuilder: public HouseBuilder{ protected: //具体构建器,但把组合操作又拆走了,可以不拆。 virtual void BuildPart1(){ //pHouse->Part1 = ...; } virtual void BuildPart2(){ } virtual void BuildPart3(){ } virtual void BuildPart4(){ } virtual void BuildPart5(){ }
};
//构建器再加一个构建器,把稳定和变化完全分开。 class HouseDirector{ public: HouseBuilder* pHouseBuilder; HouseDirector(HouseBuilder* pHouseBuilder){ this->pHouseBuilder=pHouseBuilder; } House* Construct(){ pHouseBuilder->BuildPart1(); for (int i = 0; i < 4; i++){ pHouseBuilder->BuildPart2(); } bool flag=pHouseBuilder->BuildPart3(); if(flag){ pHouseBuilder->BuildPart4(); } pHouseBuilder->BuildPart5();
return pHouseBuilder->GetResult(); } }; |
4.4.3 构造函数不能使用虚函数的原因
因为子类的构造顺序是先调用基类的构造函数,基类结束构造后才能够构造派生类;如果基类构造时候使用了派生类的函数,这时派生类的函数还没有被实例化,因此在构造函数中不能使用虚函数机制。
4.4.4 核心
- 主要用于分步骤构建复杂对象,步骤是稳定的,组成是变化的。
- 缺点在于难以应对步骤的变化。
- 注意不同语言中构造函数的绑定机制,有的语言是可以在构造函数里边使用虚函数的。在C#或JAVA中是可以在构造里边使用的。
4.4.5 类图

其中Director和Builder都是稳定的,但稳定的程度有不同。通常用Builder作为部分的构建,Director作为组合的方式。
5. 对象性能类设计模式
面向对象很好地解决了抽象的问题,但是必不可免的会带来一些代价。通常情况下面向对象的成本可以忽略不计,但是有些情况下面向对象所带来的成本需要谨慎处理。
5.1 Singleton(单件模式)
5.1.1 应用场景
在软件系统中,经常有一些特殊的类,必须保证它们在系统中只存在一个实例,才能确保他们的正确性和效率。
5.1.2 定义与解释
保证一个类仅有一个实例,并提供一个该实例的全局访问点。
首先,我们必须要私有的定义拷贝构造函数和构造函数,即使可能什么都不做。不然的话,编译器将自动生成缺省的拷贝构造函数和构造函数,突破了你对它的限制。
class Singleton{ private: Singleton(); Singleton(const Singleton& other); public: static Singleton* getInstance(); static Singleton* m_instance; }; Singleton* Singleton::m_instance=nullptr; |
在getinstance的定义上,有很多种方法:
//线程非安全版本 Singleton* Singleton::getInstance() { if (m_instance == nullptr) { m_instance = new Singleton(); } return m_instance; } |
这种方法的缺陷在于不能够应对多线程的情况(没有互斥锁)。但是互斥锁严重地影响了性能。进行优化的一种方法是,使用双检查锁,尽量减少因为锁带来的阻塞。
//双检查锁,但由于内存读写reorder不安全 Singleton* Singleton::getInstance() {
if(m_instance==nullptr){ Lock lock; if (m_instance == nullptr) { m_instance = new Singleton(); } } return m_instance; } |
这里必须解释为什么有两次锁。考虑两个线程A和B,他们同时通过了第一个关卡,然后A锁住了这个资源,B被阻塞。当A结束时,如果没有第二个锁,B也会进行创建。注意这里提到的一个reorder的情况。因为流水线安排是会将一些汇编语句交换位置。这里就涉及到了之前学过的new的三个步骤:分配内存,调用构造器,赋值。然而在指令级别,这三步有可能顺序调换,变为分配内存,赋值,调用构造器。这时候假设进程A卡在了赋值和调用构造器之间,还没有调用构造器;另一个线程B到了第一个锁的时候认为实例已经存在,就把这块地址返回了回去!这样的话这个实际上还是不能用的,会导致系统崩溃。
VC++考虑了这一点,添加了volatile关键字,代表禁止reorder;但这只能在windows上使用。在C++11后添加了跨平台的方式,即使用atomic和内存fence,代码如下:
//C++ 11版本之后的跨平台实现 (volatile) std::atomic<Singleton*> Singleton::m_instance; std::mutex Singleton::m_mutex;
Singleton* Singleton::getInstance() { Singleton* tmp = m_instance.load(std::memory_order_relaxed); std::atomic_thread_fence(std::memory_order_acquire);//获取内存fence if (tmp == nullptr) { std::lock_guard<std::mutex> lock(m_mutex); tmp = m_instance.load(std::memory_order_relaxed); if (tmp == nullptr) { tmp = new Singleton; std::atomic_thread_fence(std::memory_order_release);//释放内存fence m_instance.store(tmp, std::memory_order_relaxed); } } return tmp; } |
在C++面向对象编程(1)的学习中,采用了Static变量的方法,这也是实现单件模式的一种手段。事实上他是和完全锁一样的手段,对性能的影响比较大,static变量的创建过程是完全锁住的。
5.1.3 核心
- 实例构造器也可以设置为protected以备派生。
- 必须不能支持拷贝构造和Clone
- 注意双检查锁与reorder。
5.1.4 类图
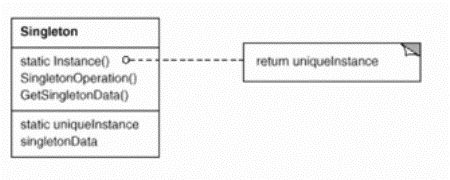
5.2 Flyweight(享元模式)
5.2.1 应用场景
在软件系统中采用纯粹对象方案的问题在于大量细粒度的对象会很快充斥在系统中,从而带来很高的运行时代价——主要是内存需求。
5.2.2 定义与解释
运用共享技术有效地支持大量细粒度的对象。
需要指出的是,现在的有些编译器会自动采取享元模式尽可能的优化内存占用。
考虑一个字体设计的场景,每个字体会有几十万个字,我们不可能把它们多次创建字体对象,这时就需要考虑使用享元来节省内存资源。
class Font { private: //unique object key string key; //object state //.... public: Font(const string& key){ //... } }; |
这里需要引入池的设计,有则返回,无则添加。
class FontFactory{ private: map<string,Font* > fontPool; public: Font* GetFont(const string& key){
map<string,Font*>::iterator item=fontPool.find(key);
if(item!=footPool.end()){ return fontPool[key]; } else{ Font* font = new Font(key); fontPool[key]= font; return font; }
}
void clear(){ //... } }; |
5.2.3 核心
- Flyweight和Singleton两种模式和抽象都没关系,解决代价问题。
- 采用共享方法降低对象个数,注意对象状态不应该被改变,最好是只读的。
- 内存开销"过大"必须要有一个具体数学上的评估,多少个对象才算大,而不能臆断。
5.2.4 类图

这里运用了一个享元工厂,如果这个资源已经有了就返回之前的,如果不存在就进行创建。
6. 接口隔离类设计模式
在组件构建过程中,某些接口之间直接的依赖常常会带来很多问题甚至根本无法实现。采用添加一层间接(稳定)接口,来隔离本来互相紧密关联的借口是一种常见的解决方案。
6.1 Facade(门面模式)
6.1.1 应用场景
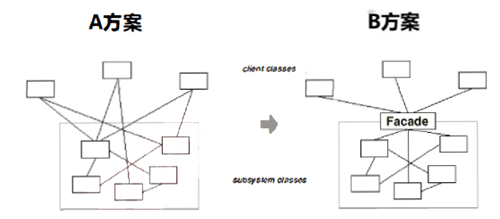
考察这两种方案的区别,A方案的问题在于客户和组件中的各种子系统有了过多的耦合,随着外部客户程序和个子系统的演化,这种过多的耦合面临诸多变化。Façade模式是层次模型的基础。
6.1.2 定义与解释
为子系统中的一组接口提供一个一致(稳定)的界面,Façade模式定义了一个高层接口,这一接口使得这一子系统更加容易使用(复用)。
6.1.3 核心
- 从客户程序的角度看,Façade简化了接口;对内外关系上,其具有解耦的效果。
- 更注重从架构的层次看系统,倾向于是一种架构模式。
- Façade内部应该是"相互耦合关系非常大的一系列组件"而不是简单的功能集合。
6.1.4 类图
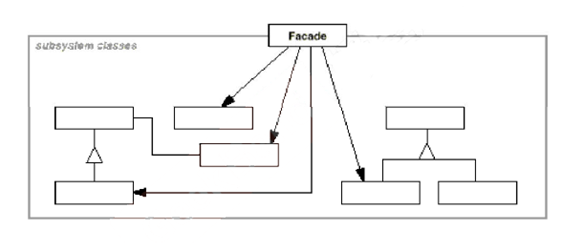
6.2 Proxy(代理模式)
6.2.1 应用场景
在面向对象系统中,有些对象由于某种原因(如创建开销、某些操作需要安全控制或进程外的访问),直接访问会给使用者或系统结构带来麻烦。我们希望能够不失去透明操作对象的同时管理这些复杂性,采用间接层。
6.2.2 定义与解释
为其他对象提供一种代理以控制(隔离,使用接口)对这个对象的访问。
化直接访问为间接访问,可实现一些安全控制等做法。
class ISubject{ public: virtual void process(); }; class RealSubject: public ISubject{ public: virtual void process(){ //.... } };
class ClientApp{ ISubject* subject; public: ClientApp(){ subject=new RealSubject(); } void DoTask(){ //... subject->process();
//.... } }; |
这里用户程序直接操纵了RealSubject,而Proxy设计模式就是为其加一层包装,然后再让ClientAPP操纵Proxy:
//Proxy的设计 class SubjectProxy: public ISubject{ public: virtual void process(){ //对RealSubject的一种间接访问,可以添加一些操作 //.... } }; |
6.2.3 核心
- 增加间接层是一种常用的解决问题方法。
- 具体Proxy的实现方法相差很大,如写实复制技术对单个对象做细粒度控制,有的则是在架构层次对对想做代理。
- Proxy并不以需要保持接口完全一致,有时候可能随时一些透明性。
6.2.4 类图

代理和具体对象都派生自这个类,代理的对象提供了一种控制的方法。
6.3 Adapter(适配器)
6.3.1 应用场景
在软件系统中,由于应用环境的变化,常常需要将旧的对象放到新的环境中应用,但是新环境要求的接口是旧的对象不能满足的。
6.3.2 定义与解释
将一个类的接口转换成客户希望的另一种接口。
考虑这样一种情况,我们要使用新的接口:
//目标接口(新接口) class ITarget{ public: virtual void process()=0; };
//遗留接口(老接口) class IAdaptee{ public: virtual void foo(int data)=0; virtual int bar()=0; };
//遗留类型 class OldClass: public IAdaptee{ //.... }; |
通过继承关系保证了接口的一致性,通过组合关系对老接口进行操作。
//对象适配器 class Adapter: public ITarget{ //继承 protected: IAdaptee* pAdaptee;//组合
public:
Adapter(IAdaptee* pAdaptee){ this->pAdaptee=pAdaptee; }
virtual void process(){ int data=pAdaptee->bar(); pAdaptee->foo(data);
} }; |
还有一种适配器的实现是通过多重继承的方式,一般我们不推荐。但是必须承认的是多重继承的"类适配"方案效率略高于对象适配器。
//类适配器 class Adapter: public ITarget, protected OldClass{ //多继承
} |
6.3.3 核心
- Adapter模式主要用用于希望复用但接口不一致。
- GoF23实际上定义了两种Adapter模式的实现结构:对象适配器和类适配器。类适配器应用多继承,对象适配器应用组合。一般不推荐多继承,一方面由于内存模型的复杂性,另一方面组合更符合松耦合精神。
6.3.4 类图
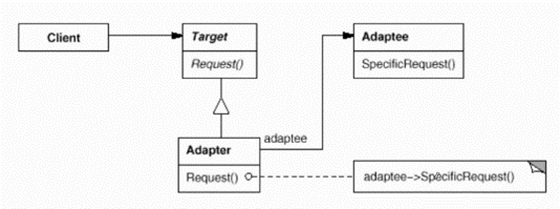
Adapter继承自目标接口,它组合了一个指向旧的对象的指针,组合的目的是能够使用旧的代码。一般我们不推荐使用多继承。
6.4 Mediator(中介者)
6.4.1 应用场景
在软件构建过程中,经常会出现多个对象互相关联交互的情况,对象之间常常会维持一种复杂的引用关系,如果遇到一些需求的更改,这种直接的引用过膝将面临不断的变化。
在这种情况下,我们使用一个中介来管理对象间的关联,避免相互交互的对象之间的紧耦合引用关系,从而更好地抵御变化。
6.4.2 定义与解释
用一个中介对象来封装一系列的对象交互。中介者使各个对象不需要显式地相互引用(编译时到运行时),从而实现松耦合,并且可以独立的改变他们之间的交互。
和门面的区别在于门面是客户和后台的隔离层,而中介者可以是后台模块间的隔离层;门面主要是解除单向的紧耦合,中介者则是解除双向的紧耦合。
6.3.3 核心
- 将多个对象将的复杂的关联关系解耦,将控制逻辑进行集中化,简化了系统的维护。
- 当系统复杂化时,Mediator有时需要进行一些分解处理。
- 注意与门面的区别,门面为系统"间",中介者为系统"内"。
6.3.4 类图

Colleague有一个指向终结者的指针,具体中介中有指向具体Colleagues的指针。这种方式使得,ConcreteMediator和ConcreteColleague之间双向紧耦合但是各个Colleague不再紧耦合,因此修改某一个类时我们只需重新编译具体类与中介者。
这种有点像通信系统的结构,通过一个基站把两个对象相连接。因此一般需要一个统一的消息机制,也就是一种通知协议,这也使得中介者模式经常要与观察者模式联用。
6.3.5 四种接口隔离模式的区别
- Façade解决了系统内和系统外之间的耦合关系
- Proxy解决了两个对象之间的由于分布式、高性能等的细腻控制
- Adapter解决新老接口不Match的情况
- Mediator解决系统内部各个部件的耦合。
7. 状态变化类设计模式
在组建构架的过程中,某些对象的状态经常面临变化。状态变化模式提供了一种有效地对状态进行管理并维持高层稳定的办法。
7.1 State(状态模式)
7.1.1 应用场景
在软件构建的过程中,某些对象的状态如果改变,其行为也会改变。比如读写和只读。
7.1.2 定义与解释
允许一个对象在内部状态改变是改变行为,从而使对象看起来像是修改了自己的行为。
考虑一个网络应用的情形,他会根据网络的Open、close、connect状态进行调整:
enum NetworkState { Network_Open, Network_Close, Network_Connect, }; class NetworkProcessor{ NetworkState state; public:
void Operation1(){ if (state == Network_Open){ //********** state = Network_Close; } else if (state == Network_Close){ //.......... state = Network_Connect; } else if (state == Network_Connect){ //$$$$$$$$$$ state = Network_Open; } } public void Operation2(){ if (state == Network_Open){ //********** state = Network_Connect; } else if (state == Network_Close){ //..... state = Network_Open; } else if (state == Network_Connect){
//$$$$$$$$$$ state = Network_Close; } } } |
这种大量的ifelse结构在之前的策略模式中我们已经提到过具有不宜添加状态,不宜单个修改,不和开闭原则的特点。那么依照策略模式的方法衍生出状态模式:
class NetworkState{
public: NetworkState* pNext; virtual void Operation1()=0; virtual void Operation2()=0; virtual void Operation3()=0;
virtual ~NetworkState(){} };
class OpenState :public NetworkState{
static NetworkState* m_instance; public: static NetworkState* getInstance(){ if (m_instance == nullptr) { m_instance = new OpenState(); } return m_instance; }
void Operation1(){
//********** pNext = CloseState::getInstance(); }
void Operation2(){
//.......... pNext = ConnectState::getInstance(); }
void Operation3(){
//$$$$$$$$$$ pNext = OpenState::getInstance(); }
};
class CloseState:public NetworkState{ } //... |
各种状态切换的时候,在执行操作后改变的是"对象",而不是"枚举"。通过这种方式,使NetworkState对象看起来像是改变了功能一样,实际上是所委托的状态对象改变了。
套用这种设计,我们可以有这样的一个状态机架构,每次执行当前状态的操作,然后切换状态。所切换的下一个状态究竟是谁,是由状态对象自己决定了。NetworkProcesser本身不需要进行任何的改变,成为了稳定的,永远是"执行操作—>切换下一个状态"的这种套路。
class NetworkProcessor{ NetworkState* pState; public: NetworkProcessor(NetworkState* pState){ this->pState = pState; } void Operation1(){ //... pState->Operation1(); pState = pState->pNext; //... } void Operation2(){ //... pState->Operation2(); pState = pState->pNext; //... } void Operation3(){ //... pState->Operation3(); pState = pState->pNext; //... }
}; |
7.1.3 核心
- 实例构造器也可以设置为protected以备派生。
- 必须不能支持拷贝构造和Clone
- 注意双检查锁与reorder。
7.1.4 类图

7.2 Memento(备忘录)[Obsoleted]
7.2.1 应用场景
在软件构建过程中,某些对象的状态转换过程中可能要求程序能够回溯到之前的某个状态。如果使用一些共有借口来让其他对象得到对象的状态,会暴露实现细节。备忘录就是要实现状态恢复又不破坏封装性。
7.2.2 定义与解释
在不破坏封装性的前提下,捕获一个对象的内部状态并在该对象之外保存这个状态。这样以后就可以将该对象恢复到原先保存的状态。
class Memento { string state; //.. public: Memento(const string & s) : state(s) {} string getState() const { return state; } void setState(const string & s) { state = s; } }; class Originator { string state; //.... public: Originator() {} Memento createMomento() { Memento m(state); return m; } void setMomento(const Memento & m) { state = m.getState(); } }; |
这只展示了一个很简单的例子,但实际上保存的状态不同的平台,不同的Originator(源发器),不同的量级(保存次数)要求非常多,实际上是很复杂的。
7.2.3 核心
- 需要提出,备忘录这种模式现在随着行业发展已经有些过时了。
- 备忘录的核心是信息隐藏,Originator需要向外界隐藏信息,又要将状态保存到外界。
- 现代语言在运行时(C#,JAVA等)具有对象序列化支持,因此备忘录模式已经被序列化方案来替代,效率较高又容易使用。
7.2.4 类图

8. 数据结构类设计模式
常常有一些组建的内部有特定的数据结构,如果让客户程序依赖这些特定的数据结构,将极大地破坏组件的复用。这时候将这些特定数据结构封装在内部,在外部提供统一的接口来实现与特定结构无关的访问。
8.1 Composite(组合模式)
8.1.1 应用场景
某些情况下,客户代码过多的依赖与对象容器复杂的内部实现结构,对象同其内部实现结构(而不是接口)的变化将引起客户代码的频繁变化。组合模式要使对象容器自己来实现自身的复杂结构,使得客户代码就像处理简单对象一样处理复杂的对象容器。
8.1.2 定义与解释
见对象组合成树形结构以表示"部分-整体"的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性。
参见如下的代码,叶子和根都是Component的子类:
|
有了这样的组合模式,我们可以进行这样的操作:
|
8.1.3 核心
- 把一对多的关系转化为一对一的关系,使得客户代码可以不去考虑自己是操作一个对象还是一整个容器的对象。
- 将客户代码与容器的结构解耦是Composite的核心思想。解耦之后,客户代码将于纯粹的抽象接口发生依赖,从而更能应对变化。
- 在实现时可以考虑双向树,如果频繁有遍历需求,可以用缓存来提高效率(可以应用树的算法方面的技巧)
8.1.4 类图
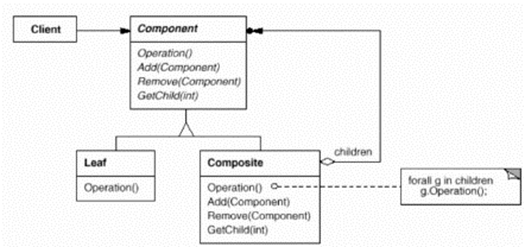
注意这里边Component的Add和Remove操作时有争议的,因为Leaf不应该具有Add和Remove的接口。在此例子中,我们直接在根节点中添加add方法,不把它作为统一的接口实现。
8.2 Iterator(迭代器)
8.2.1 应用场景
几何对象内部结构常常不同,但对于这些集合对象,我们希望在不暴露内部结构的同时,可以让外部客户代码透明地访问其中包含的元素;这也为算法应用于不同几何对象提供了可能。
各种面向对象技术广泛应用了迭代器,在之前的学习中也有很细致的讲解在这一个章节就不过多讲授。
8.2.2 定义与解释
提供一种方法顺序访问一个局和对象中的各个元素而又不暴露(隔离变化)该对象的内部表示。
在迭代器刚提出的时候是采用面向对象的方式设计的,设计了一个基本的迭代器接口(虚函数),然后各种不同的迭代器进行重写。必须提出这种迭代器现在已经过时了。这种实现具有非常巨大的性能成本,由于虚函数机制的访问内存消耗对迭代器这种大量访问是很可观的。
现在C++的迭代器采用的实现是通过模板方法,而不是通过派生。模板方法也可以理解成是一种多态,但他是编译时就决定了,不需要再去找内存位置,这就提高了效率。
不过,在JAVA,C#等语言中,迭代器仍然采用虚函数机制,这是C++性能较高的一个原因。
8.2.3 核心
- 迭代抽象:访问内容而不需暴露内部表示
- 迭代多态:遍历不同的集合由一个统一的接口
- 迭代器健壮性:遍历时更改迭代器所在的集合结构会导致问题。
8.2.4 类图[Obsolete]

这是当初利用对象的方式实现迭代器的方法,不过这种方法现在对于C++来说已经过时了
8.3 Chains of Responsiblity(职责链)[Obsolete]
8.3.1 应用场景
在软件构建过程中,一些请求可能被多个对象处理,但是每个请求在运行时只能有一个接受者,如果显示指定,则会带来发送者与接受者的紧耦合。(但一般现在已经不把它作为一种设计模式了)
8.3.2 定义与解释
使每个对象都有机会吃了靓丽请求,从而避免请求的发送者和接受者的耦合关系,将浙西对象形成一条链(链表),并沿着这条链传递请求,直到有一个对象处理它为止。
- class Reqest { //一段请求信息
- string description;
- RequestType reqType;
- public: Reqest(const string & desc, RequestType type): description(desc), reqType(type) {}
- RequestType getReqType() const {
- return reqType;
- }
- const string & getDescription() const {
- return description;
- }
- };
- class ChainHandler {
- ChainHandler * nextChain; //多态的链表
- void sendReqestToNextHandler(const Reqest & req) {
- if (nextChain != nullptr) nextChain - > handle(req);
- }
- protected: //判断是否能处理请求
- virtual bool canHandleRequest(const Reqest & req) = 0; //具体处理请求
- virtual void processRequest(const Reqest & req) = 0;
- public:
- ChainHandler() {
- nextChain = nullptr;
- }
- void setNextChain(ChainHandler * next) {
- nextChain = next;
- }
- void handle(const Reqest & req) {
- if (canHandleRequest(req)) processRequest(req);
- else sendReqestToNextHandler(req);
- }
- };
这里边的handle函数清晰地解释了职责链的处理逻辑,判断了如果当前对象能够处理这个请求,就处理这个请求;如果当前对象不能处理这个请求,就将其传递给下一个对象处理。接下来我们可以写各种具体的Handler。
8.3.3 核心
- 职责链应用于一个请求有多个接收者但是真正的执行者只有一个。
- 职责链使得对象的职责分派更具有灵活性,我们可以动态地添加/修改请求的处理职责。
- 如果没有能够处理的请求,要有一个缺省机制。
- 很多情况下现在已经不把它作为一种设计模式,而作为一种设计结构。
8.3.4 类图

这种情况下Handler和客户端程序是不变的,而具体的handler是很容易改变的。职责链这种模式在现在的应用不是很多。s
9. 行为变化类设计模式
在组组件的构建过程中,组件行为的变化经常导致组件本身剧烈的变化。"行为变化"模式将组建的行为和组件本身解耦,从而支持组建行为的变化,实现二者的松耦合。
9.1 Command(命令模式)
9.1.1 应用场景
在软件构建过程中,"行为请求者"与"行为实现者"通常是紧耦合,但在一些场合——比如对行为进行记录、撤销、事务等处理,这种紧耦合使不合适的。
9.1.2 定义与解释
将一个请求封装为一个对象,从而使你可以用不同的请求对客户进行参数化;队请求排队或记录请求日志,以及支持可撤销的操作
参见如下的代码,每个对象就表示一种行为,然后用一个MacroCommand对象,采用一种类似于组合模式的实现方法:
- class Command {
- public: virtual void execute() = 0;
- };
- class ConcreteCommand1: public Command {
- string arg;
- public: ConcreteCommand1(const string & a): arg(a) {}
- void execute() override {
- cout << "#1 process..." << arg << endl;
- }
- class MacroCommand: public Command {
- vector < Command * > commands;
- public:
- void addCommand(Command * c) {
- commands.push_back(c);
- }
- void execute() override {
- for (auto & c: commands) {
- c - > execute();
- }
- }
- };
注意MacroCommand类,既继承于Command,由组合了Command,可以实现对Command的控制。每一种Command就只有一个函数execute,就表示了一种功能。
9.1.3 核心
- 请求与实现解耦的手段是,将行为抽象为对象。
- 具体命令对象有时候可能需要保存额外信息,可以通过Composite模式将多个命令进行封装。
- Command模式的作用有点像函数对象,但是又有所区别。它以"接口-实现"来定义行为接口规范,更严格但是有性能损失;C++函数对象以函数签名定义接口规范,更灵活,性能更高。
9.1.4 类图
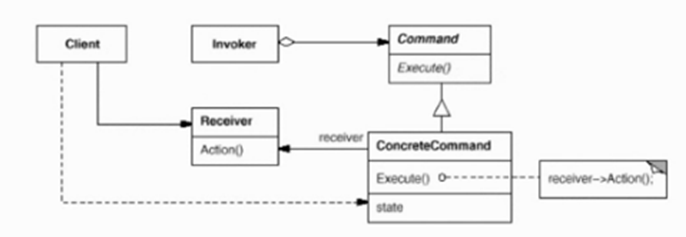
一旦把行为对象化之后,我们也可以很轻易的实现redoundo等功能。
9.2 Visitor(访问器)
9.2.1 应用场景
在软件构建过程中,由于需求的改变,某些类层次结构中常常需要增加新的行为(方法),如果直接在基类中做这样的更改,将会给子类带来很繁重的变更负担,甚至破坏原有设计。(父类中添加虚函数,所有子类不得不添加新的虚函数,)
9.2.2 定义与解释
表示一个作用于某对象结构中的各元素的操作。 使得可以在不改变(稳定)各元素的类的前提下定义(扩展)作用于这些元素的新操作(变化)。
Visitor用于,设计者知道将来肯定会加一些操作,但是加什么操作,加多少操作都不知道的情况。可以看如下代码:
- class Visitor;
- class Element {
- public: virtual void accept(Visitor & visitor) = 0; //第一次多态辨析
- virtual~Element() {}
- };
- class ElementA: public Element {
- public: void accept(Visitor & visitor) override {
- visitor.visitElementA( * this);
- }
- };
- class ElementB: public Element {
- public: void accept(Visitor & visitor) override {
- visitor.visitElementB( * this); //第二次多态辨析
- }
- };
- class Visitor {
- public: virtual void visitElementA(ElementA & element) = 0;
- virtual void visitElementB(ElementB & element) = 0;
- virtual~Visitor() {}
- }; //================================== //扩展,而不用更改子类、
- class Visitor1: public Visitor {
- public: void visitElementA(ElementA & element) override {
- cout << "Visitor2 is processing ElementA" << endl;
- }
- void visitElementB(ElementB & element) override {
- cout << "Visitor2 is processing ElementB" << endl;
- }
- };
注意调用关系,Visitor会根据不同的调用的element进行不同的操作。里边的accept函数是核心。
- int main() {
- Visitor1 visitor;
- ElementB elementB;
- elementB.accept(visitor); // double dispatch
- ElementA elementA;
- elementA.accept(visitor);
- return 0;
- }
这里涉及到两次多态辨析,第一次是在element接受一个visitor,第二次是visitor对于element的操作。这种调用方式是visitor的重中之重。
Visitor
9.2.3 核心
- Visitor模式通过所谓双重分发来实现在不更改Element层次结构的前提下,在运行时透明地给类层次结构上的各个类动态添加新的操作。
- 双床分发即值中间两个多态辨析。
- 缺点在于Element不能再增加了。因此Visitor仅适用于element层次结构稳定但其中的操作却经常变化。
9.2.4 类图

注意!这个模式要求ConcreteElementA和B都是稳定的!因为Visitor依赖于两个具体的Element。这个模式中可以变化的部分只有具体的Visitor,也就是具体的功能。在写这个Visitor的时候,你必须知道Element有多少个ConcreteElement。而且只要有多少个Element,就要有多少个方法。这个要求实际上是很严苛的。
10. 领域规则类设计模式
在特定领域中,某些变化虽然频繁,但可以抽象为某种规则。 这时候,结合特定领域,将问题抽象为语法规则,从而给出在该领域下的一般性解决方案。
10.1 Interpreter(解析器模式)
10.1.1 应用场景
在软件构建过程中,如果某一特定领域的问题比较复杂,类似的结构不断重复出现,如果使用普通的编程方式来实现将面临非常频繁的变化。在这种情况下将特定领域的问题表达为某种语法规则下的句子,然后运行一个解释器来解释这样的句子。
10.1.2 定义与解释
给定一个语言,定义它的文法的一种表示,并定义一种解释器,这种解释器使用该表示来解释语言中的句子。
一个例子就是字符串表达式的解析器。通常解析器要形成类似的树形结构。

10.1.3 核心
- Interpreter模式的应用,只有满足"业务规则频繁变化,且类似的结构不断重复出现,并且容易抽象为语法规则的问题"。
- 使用Interpreter对象来标示文法规则,从而可以使用面向对象技巧扩展文法。
- 对于复杂的文法,需要利用语法分析生成器这种工具。
10.1.4 类图

在进行表达式解析时,可以使用递归定义。在前文所画的树中,叶子节点(变量)就是TerminalExpression;非叶子结点就是NonterminalExpression。
