[GeekBand] STL与泛型编程(2)
本篇文章在上一篇文章的基础上进一步介绍一些常用的容器以及STL的一些深入知识。
一、 Stack和Queue
栈和队列是非常常用的两种数据结构,由deque适配而来。关于数据结构的知识这里就不在介绍了,仅介绍STL中的成员方法。
stack 的基本操作有:
入栈,如例:s.push(x);
出栈,如例:s.pop();注意,出栈操作只是删除栈顶元素,并不返回该元素。
访问栈顶,如例:s.top()
判断栈空,如例:s.empty(),当栈空时,返回true。
访问栈中的元素个数,如例:s.size()。
queue 的基本操作有:
入队,如例:q.push(x); 将x 接到队列的末端。
出队,如例:q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值。
访问队首元素,如例:q.front(),即最早被压入队列的元素。
访问队尾元素,如例:q.back(),即最后被压入队列的元素。
判断队列空,如例:q.empty(),当队列空时,返回true。
访问队列中的元素个数,如例:q.size()
二、 Map
Map是一种关联容器,存储的对象是键值(Key-Value)对。和Python中的字典相似。Map中的键值对永远是排好序的。
Map中所存储的键对象必须是可排序的,默认采用从小到大的排序方式。也可以通过函数对象的方式进行指定。Map的标准头为:
template <class _Kty, class _Ty,class _Pr = less<_Kty>,class _Alloc = allocator<Pair<const _Kty,_Ty>>> class map {...} |
其中的less<_Kty>是一个函数式对象,代表了排序函数,分配器通常为默认分配器。
2.1 Map的创建
通过Pair和迭代器创建并初始化,其中Pair的第一个值为键,第二个值为值。
const std::pair<int ,char>items[3] = { std::make_pair(1,'a'),std::make_pair(2,'b'),std::make_pair(3,'c') } std::map<int,char> map1(item,item+3); |
2.2 Map的元素插入
1 通过insert成员函数
map1.insert(std::make_pair(4,'d'); |
2 直接使用未使用的下标
map1[5] = 'e'; |
2.3 Map的元素删除
iterator erase(iterator it); | 1 通过一个条目对象删除 |
iterator erase(iterator first, iterator last); | 2 删除一个范围 |
size_type erase(const Key& key); | 3 通过键删除 |
2.4 Map的元素访问
1. 通过key和引用访问
char &e = map1[2]; e = 'c'; |
需要注意的是,通过下标访问的方法和插入操作在语法上没有区别,如过使用了一个没有被定义过的键,则会创建一个新的键值对,这通常不是我们所说希望的。因此有第二种方案。
2. 通过成员函数和迭代器
map.count(k) | 返回map中键k的出现次数(对于map而言,由于一个key对应一个value,因此返回只有0和1,因此可以用此函数判断k是否在map中) |
map.find(k) | 返回map中指向键k的迭代器,如果不存在键k,则返回超出末端迭代器(map1.end())。 |
2.5 Multimap
和Map基本一致,但是允许出现重复的Key。由于可以出现重复的Key,在Map中可以进行的[]访问和[]插入操作将不能进行而只能通过迭代器和insert()的方式去执行。
三、Set
Set也是一种关联容器,存储的对象可以看做是既作为Key又作为Value。Set和Map非常相似。它实现了红黑树的搜索结构。
同理,Set中所存储的键对象必须是可排序的,默认采用从小到大的排序方式(必须有operator<)。也可以通过函数对象的方式进行指定。set的标准头为:
template <class _Kty,class _Pr = less<_Kty>,class _Alloc = allocator<Pair< _Kty>>> class map {...} |
其中的less<_Kty>是一个函数式对象,代表了排序函数,分配器通常为默认分配器。
3.1 Set的创建
通过迭代器/指针创建并初始化。
struct betterthan{ bool operator()(char a1,char a2){ return a1>a2?1:0; } } const char items[3] = { 'a','b','c' } std::set<char,betterthan> set1(item,item+3); |
3.2 Set的元素插入
通过insert成员函数
set1.insert('d'); |
3.3 Set的元素删除
iterator erase(iterator it); | 1 通过一个条目对象删除 |
iterator erase(iterator first, iterator last); | 2 删除一个范围 |
size_type erase(const Key& key); | 3 通过键值直接删除 |
3.4 Set的常用算法
1 set::union 取并
template <class InputIterator1, class InputIterator2, class OutputIterator, class Compare> OutputIterator set_union (InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, InputIterator2 last2, OutputIterator result, Compare comp); |
Set_union将两个input中间的所有元素取并,存储到result迭代器所处的位置中。最后一个比较函数式对象可以不指定,默认为小于。
注意这里要求result迭代器所指向的对象有足够的空间继续存储,如下例。
int first[] = {5,10,15,20,25}; int second[] = {50,40,30,20,10}; vector<int> v(10); // 0 0 0 0 0 0 0 0 0 0 vector<int>::iterator it;
sort (first,first+5); // 5 10 15 20 25 sort (second,second+5); // 10 20 30 40 50
it=set_union (first, first+5, second, second+5, v.begin()); // 5 10 15 20 25 30 40 50 0 0 |
V需要具有足够大的空间以存储新的集合。如果想要自动进行添加操作,可以使用下面的代码,通过inserter(c,c.begin)生成一个插入迭代器(返回值类型insert_iterator),可以自动进行插入操作:
set<int> a,b,c; a.insert(1); a.insert(6); a.insert(6); b.insert(2); b.insert(6); b.insert(9); set_union(a.begin(), a.end(), b.begin(), b.end(), inserter(c, c.begin())); |
2. set::intersection 取交
template <class InputIterator1, class InputIterator2, class OutputIterator, class Compare> OutputIterator set_intersection(InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, InputIterator2 last2, OutputIterator result, Compare comp); |
语法和使用要求union完全一样,不再过多赘述。
3. set::difference 取差集(集合1-集合2)
语法和使用要求union完全一样,不再过多赘述。
3.5 关于改变set的成员
由于set中的对象即为键,又为值,从set的角度上看,键是不应该改变的。因此,set不允许通过迭代器改变对象成员,以确保排序不会发生异常。然而这又带来了一些不合理之处:例如我们存储的是一个pair<int,string>的名次列表,那么我们希望的行为是int不改变而string也就是名字可以改变。而且显然名字并不是用来排序的,修改它不会带来任何的异常,那么理论上应该可以更改它。我们可以采用以下的方案进行修改名字:
const_cast<Pair<int,string>&> (*iter).name = "Bill"; |
const_cast<type_id> (expression)运算符用来修改类型的const或volatile属性。特别注意的是,这里const_cast的实例化对象必须是相应的引用,否则采取了依据(*iter)创建临时可修改对象,然后修改临时对象的行为,并不能实现更改。通过这一运算符,常量指针被转化成非常量的指针、常量引用被转换成非常量的引用,并且仍然指向原来的对象。不过这也使得set丧失了相应的保护措施,切记不可以修改排序时用的值。
PS:对于迭代器,*iter运算返回的是相应的引用而不是值传递的一个实例,因此可以使用const_cast进行处理。
四、STL进阶问题
1. STL整体结构与各部分的关系
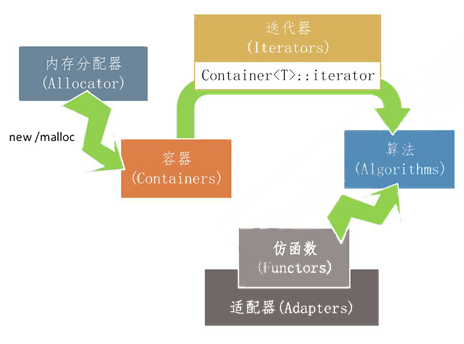
容器通过内存分配器分配空间;容器和算法因为迭代器而分离,算法通过迭代器访问容器;仿函数协助算法指定不同的策略;适配器套接仿函数。
仿函数将某种"行为"作为算法的参数传给算法。以之前自定义的ContainsString为例:
v.erase(remove_if(v.begin(),v.end(),ContainsString(L"C++")),v.end()) |
我们可以看一下ContainsString的定义:
struct ContainsString:public std::unary_function<std::wstring,bool> { ContainsString(const std::wstring& wszMatch):m_wszMatch(wszMatch){} bool operator()(const std::wstring& wszStringToMatch) const{ return(wszStringToMatch.find(m_wszMatch)!=-1); } std::wstring m_wszMatch; } |
通过查看定义可以发现,ContainsString(L"C++")创建了一个函数对象,随后在remove_if中进行了使用。类似地,我们可以通过自定义仿函数和for_each结合以实现一些其他的功能。
struct PrintContainer { PrintContainer (std::ostream& out):os(out){}
Template<class T> void operator()(const T& x) const{ os<<x<<' '; } std::ostream& os; } |
Q:为什么要定义仿函数而不用函数指针?
A:1.不能满足STL的抽象要求,参数和返回型别无从确定;2. 函数指针无法和其他组件交互。
2. 仿函数适配器(Function Adapter)
有时我们想要利用现有的仿函数,但是虽然功能上满足了要求,但是形式上并不正确,这时可以采用仿函数适配器的方法对仿函数进行装饰。
2.1 binder1st/binder2nd
给定一个vector,其元素为:[0,0,0,1,0],想要匹配到第一个非零元素。我们有find_if()的算法和not_equal_to的函数对象,根据这两个东西就可以实现我们的目的。
然而,not_equal_to()(const T& a,const T&b),并不能接受一个参数;find_if()又是向最后一个函数对象直接给予一个引用作为参数,所以无法编译通过。为此使用binder1st来把其中的一个参数固定下来。 从下图可以了解到一些实现细节:

这里需要提及的几点是:
1. 为了这种机制的考虑,在所有的仿函数中都要有first_argument_type等这几个typedef。通常通过派生自binary_function<class Arg1,class Arg2,class Result>可以直接得到。
2. 例如 binder1st<not_equal_to<int>>(f,0)就代表生成一个函数对象func(x)=f(0,x);
3. 各种函数适配器都是以实例化后的仿函数的类型作为模板参数的类模板,这是函数适配器的重要标志。
图中这种使用方法由于涉及到手动取类型,还是比较复杂的,为此,C++提供了一层包含了这些诸如typename使用的操作的封装bind1st,简化了我们的编写。
使用时可以使用这种写法:
vector<int>::iterator it = find_if(v.begin(),v.end(),bind1st(not_equal_to<int>(),0)); |
其中红字部分就是一个函数对象。
完全对称地,还有binder2nd这个函数适配器和bind2nd这两个工具可以使用。
2.2 mem_fun/mem_fun_ref
前面我们已经提到过,for_each()算法是将迭代器指导的每个对象直接丢给函数作为他的为一参数。通过binder1st/2nd的两个函数,我们实现了把双元函数应用到这个地方;而mem_fun/mem_fun_ref则是使得函数的无参成员函数能够被使用。例如经常使用的print()方法:
for_each(v.begin(),v.end(),mem_fun(&Person::print)); |
其中的mem_fun(&Person::print) 就是生成了一个具有单参的、针对Person类、内部调用Person::Print的全局函数。我们同样根据一个图来看这个工具的实现:
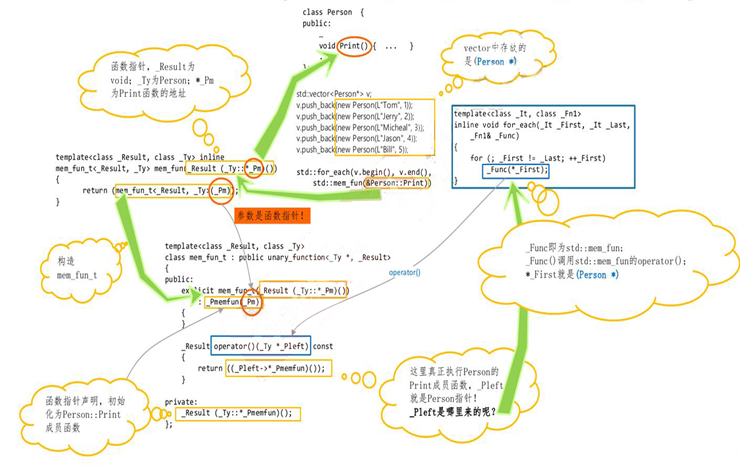
几个注意点:
1. 应用这种泛型算法的向量存储的应该是指针,因为它在for_each和mem_fun上各涉及到了一次取值运算(*),这也符合多态的要求。
2. mem_fun实际上是一层对于mem_fun_t的封装,其中有一个函数指针_Pm.这里需要注意的是,函数指针在类的内部再指向成员函数(即图中的_Ty::*_Pm)的写法,则_Ty是作用域,_Pm代表在当前作用域下的偏移量这里要注意体会*p =obj.func和class::*p = class::func的区别..
3. 这里解释一下类的成员是指针的情况下的写法,*(obj.ptr)和obj.*ptr是等价的;第二,对于函数指针来说,函数名本质就是指针,根据语法标准obj.func()和obj.*func()两种写法都能正确调用到成员函数;第三,虽然*号可以不写,但是对函数指针进行赋值时的&号是不可省略的。
PS: 如果向量中存储的直接是对象(或对象的引用)而不是指针,则可以使用mem_fun_ref的方式,操作一模一样,只不过是其内部实现的时候,_Pleft->*_Pmemfun()变成了_Pleft.*_Pmemfun();
3.其他特别的问题
1. std::string/std::wstring和vector<char>/vector<wchar_t>
- 在windows系统中,通常推荐使用wstring和wchar_t,在linux系统中则差别不大。在VS的比较新的版本中,所有的char和string都会默认使用wchar_t和wstring。这两种是采用了宽字符编码,适用于中文、日语、韩文等编码而不会产生乱码,可以使用UNICODE字符编码方式。
- 在单线程下涉及字符串,建议使用string而不是字符数组或字符向量组。
- 多线程情况下涉及到引用计数的问题,引用计数是为了避免不必要的内存分配和字符拷贝,但是多线程环境下,这部分省下来的开销被并发控制所消耗。这样的情况下,通常就是用字符向量表示字符串。
3.2 注意如果使用了诸如push(new Point(x,y))这种语法,必须要在删除容器之前遍历容器进行内存释放,否则就发生了内存泄露。
3.3 尽量用算法代替手写的循环,一方面是从效率的角度考虑,另一方面使用算法的这种方式更好地体现了面向对象的思想。
3.4 容器的size和capacity
Capacity是容器"占据"的空间,size是容器"使用"的空间。所以容器有可能占据了很大的空间然而并没有使用那一部分空间,那么这种情况下应该通过swap方法对容器进行缩小。
在上一篇中介绍swap时已经见过,swap的功能是将两个向量中的内容交换。上篇文章没有提到的一点是,交换的时候只保留有意义的对象。因此,a.swap(a)就可以实现时capacity调整到size的目的,而vector<int>().swap(a)能够实现将a清除并最小化的目的。
3.5 为什么建议在容器中放指针而不是对象?
- 拷贝的开销比较大。
- 如果存在继承,就会发生slicing。即由于保存的仅仅是基类对象,其留下的大小也就是基类对象的大小。如果存在继承关系时,若将派生类对象放入容器,则只会保留基类部分,派生类部分会丢失。这种方式体现出了C++中的多态性。
五、 泛型算法
1. 非变易算法
算法都是以模板函数的方式表现出来的。所谓的非变易算法,指的是不会改变对象内容的值的算法,诸如查找、匹配、遍历、计数等操作。
1.1 for_each
template<class _InIt,class _Fnl> inline _Fnl for_each(_InIt _First, _InIt _Last, _Fnl _Func) |
在前边已经提到,for_each就是把两个迭代器之间的对象实例扔给_Func作为唯一参数。注意,_Func不一定非得是函数对象(仿函数),直接传函数名或函数指针也是可以的。
1.2 find
template<class _InIt,class _Ty> inline _Ty find(_InIt _First, _InIt _Last,const _Ty& _Val) |
如果在左闭右开区间内找到了值为_Val的对象则返回该迭代器,否则返回器尾不迭代器。
1.3 find_if
template<class _InIt,class _Pr> inline _Ty find(_InIt _First, _InIt _Last,const _Pr _Pred) |
_Pr为一个函数名或者函数对象(仿函数)。如果在左闭右开区间内找到了的能使得这一对象返回真的,则返回该迭代器,否则返回器尾部迭代器。注意_Pr为单参,注意联合适配器的使用。
1.4 adjacent_find
template <class ForwardIterator> ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last); |
返回第一个遇到的两个连续相等的对象中,第一个对象的迭代器,如对于[0,1,2,3,3,4],则返回指向第一个3的迭代器。
template<class _InIt,class _Pr> inline _Ty find(_InIt _First, _InIt _Last,const _Pr _Pred) |
Adjacent的操作实际上是针对自己和后继进行的比较操作。除了默认的等于比较操作之外,也可以使用自定义的函数或仿函数。_Pred 具有两个参数,使用时会把连续的两个值分别作为第一参数和第二参数求真值。
1.5 find_first_of
template <class ForwardIterator1, class ForwardIterator2> ForwardIterator1 find_first_of (ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2);
template <class ForwardIterator1, class ForwardIterator2, class BinaryPredicate> ForwardIterator1 find_first_of (ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2, BinaryPredicate pred); |
它是在两组区间内搜索是否有*it1==*it2,如果有就返回第一组区间内对象的迭代器。也可以使用自定义的双参函数进行比较。
1.6 count/count_if
template <class InputIterator, class T> typename iterator_traits<InputIterator>::difference_type count (InputIterator first, InputIterator last, const T& val); |
返回左闭右开区间中值等于val的元素的个数。
类比find,count_if就是自己指定所想使用的函数。同样地,其为单参,要注意两对适配器的使用。
1.7 mismatch
template <class InputIterator1, class InputIterator2, class BinaryPredicate> pair<InputIterator1, InputIterator2> mismatch (InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, BinaryPredicate pred); |
当不指定最后一个函数时,其作用是逐元素比对两个序列,返回指向第一个容器中的第一个不一致的迭代器。如果指定函数,则是需要返回值等于False。
1.8 equal
template <class InputIterator1, class InputIterator2, class BinaryPredicate> bool equal (InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, BinaryPredicate pred); |
当不指定最后一个函数时,其作用是检查两个容器内容是否完全相等。若指定最后一个函数,则是逐元素检查是否满足两两返回值均为True。
1.8 search
template <class ForwardIterator1, class ForwardIterator2, class BinaryPredicate> ForwardIterator1 search (ForwardIterator1 first1, ForwardIterator1 last1, ForwardIterator2 first2, ForwardIterator2 last2, BinaryPredicate pred); |
当不指定最后一个函数时,其作用是搜索前一个序列中是否存在和第二个序列相同的子序列;如果自定义判别函数,则是逐元素比对,搜索是否存在能够和第二个序列匹配的序列。返回值为第一个序列中匹配的位置,如果找不到则返回末位迭代器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号