
架构设计:远程调用服务架构设计及zookeeper技术详解(上篇)
一、序言
Hadoop是一个技术生态圈,zookeeper是hadoop生态圈里一个非常重要的技术,当我研究学习hadoop的相关技术时候,有两块知识曾经让我十分的困惑,一个是hbase,一个就是zookeeper,hbase的困惑源自于它在颠覆了我对数据库建模的理解,而zookeeper的困惑却是我无法理解它到底是干嘛的。
前不久我结合我了解的一种远程调用服务的设计来帮助我理解zookeeper在实际的生产中运用,该文章的地址是:
http://www.cnblogs.com/sharpxiajun/p/3297852.html
其实这篇文章写完后,我自己感觉并不是太好,因为写本文的时候,对远程调用服务的设计以及zookeeper的理解都不是很到位,但是这篇文章还是受到了大家很大的关注,被博客园作为了推荐文章,还有很多网友希望我写一篇更加详尽的文章,还有童鞋留言说这个设计方案和淘宝开源的dubbo和hsf类似。我相信大家的关注就是意味着这个主题是当下技术的热点,所以今天我要写一篇主题和上篇文章一样的博文,这是上篇文章的升级版,不管是远程调用服务还是zookeeper我都会给出更加详尽的讲解。不过这里还是要说明下,这篇文章里远程服务的设计我还是没有参照dubbo,因为最近实在太忙,没有时间研究淘宝的dubbo,但是我希望学习过dubbo的童鞋可以帮我对比下我的方案和dubbo的区别,区别就会产生新的问题,也会有新的知识需要研究。
本文是该主题的上篇,主要是讲解远程调用服务的相关知识,下篇则是根据远程调用服务架构设计中zookeeper的相关应用方法详细讲解关于zookeeper的知识。
二、远程调用服务的架构设计总述
首先我们要再深入理解下为什么应用软件服务里需要一个远程调用服务,远程调用服务解决了软件设计中的什么问题,它的架构设计又有什么理论根据了?
我曾写了一篇关于分布式网站架构设计的文章,文章地址是:
http://www.cnblogs.com/sharpxiajun/archive/2013/05/11/3072798.html
在文章开头我就把这个新的网站架构方案和传统的企业软件的B/S架构作了对比,我将一个网站里提供业务服务的组件抽象为独立的服务系统,接收用户信息的逻辑部分抽象为前端系统,服务系统和前端系统使用netty这样的通讯组件进行通讯,而到了讲解远程调用服务的框架设计时候我将netty通讯组件进一步抽象为一个通讯独立系统及远程调用服务,这就是为什么要设计远程调用服务的缘起了,远程调用服务又会带来了网站架构的升级,如果传统的企业B/S架构为1.0版,我将前端和业务服务端分离为独立系统则是2.0版,那么引入了远程调用服务网站就是3.0版了,3.0版的架构带来的好处就是可以将N多的前端系统和N多的业务服务端系统融为一个整体,网站的规模会越来越大,提供的服务也会越来越多,这既避免重复造轮子的问题还使得网站规模越来越大。
3.0版本的网站架构带来了新的网站架构总图,如下所示:
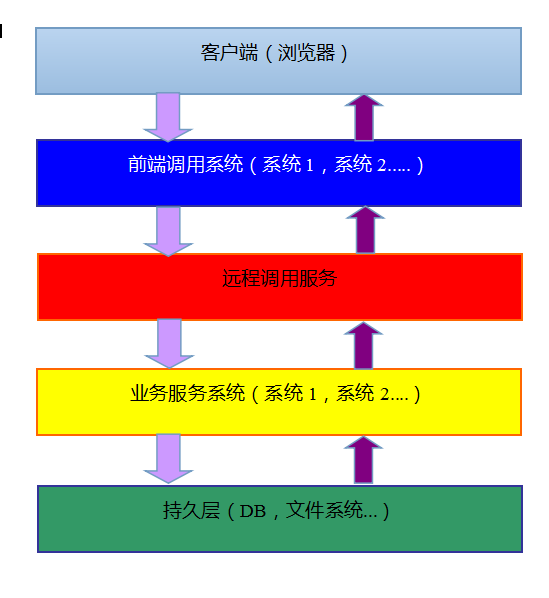
有了远程调用服务,我们可以做到业务级别的集群,例如:一个制造企业,一般都会有采购业务,生产业务、销售业务以及财务业务,按照传统的思路我们都会给每个业务独立开发一个系统,如果引用了远程调用服务,我们可以将这些业务都做成独立的服务,这些服务组成业务集群,而这些服务都是用统一的远程调用服务作为操作的入口,换句话说不管什么样的服务对于调用者来说都是统一的,这样前端的调用者可以做到应用的统一,所谓的应用的统一淘宝网站是最典型的代表,我们在一个同一的网站里可以操作各种不同的应用,而不会发生因为应用的不同我们就得重新访问新的地址或者重新登录到另外一个系统里做其他业务的操作。而服务端这边,完全可以摆脱传统的客户端和服务端耦合的开发,增强了整个服务端的专业性和稳定性,这样更易于服务端的扩展性和可维护性。如果服务端之间也需要相互调用也可以通过远程调用服务实现,由于远程调用服务的统一性,这样就避免了服务调用之间报文和调用方式的不统一,规范了整个开发的流程。如果远程调用服务还有负载均衡功能,整个服务集群就变成了一个私有的云,所以说远程调用服务是云计算的重要组成部分,这个说法一点都不为过。
远程调用服务的理论依据是什么,这个问题的表述可能有点问题,其实我要讲的是远程调用服务的技术原型就是SOA(Service-Oriented Architecture),在云计算出现前,SOA曾一度是IT的技术热点,虽然之后很多人说中国的SOA做的一点不好,就和早年的DHTML一样,诟病远多于赞赏,写本文时候我在京东里搜索了下SOA,从书籍的出版日期和书籍评价数就可以看出SOA已经有点无人问津的凄凉了。下面我要简单介绍下SOA,SOA的定义:
SOA是一个软件架构,它包含四个关键概念:应用程序前端、服务、服务库和服务总线。一个服务包含一个合约、一个或多个接口以及一个实现。
应用程序前端可以理解为我上面所讲述的调用者和前端系统,服务库可以理解为服务集群,这里还有个服务是什么呢?服务就是调用者和服务提供者完成某一个特定业务的合约,换句话说就是封装的业务规则,打个比方,我们在淘宝去购物,下订单,付款,查物流,确定付款这些操作在服务端都有独立的服务提供,但是从购物这个概念去理解,这些独立的服务才能构成这个完整的购物行为,如果其中有地方出了问题,会有相应不同的操作,那么这个就绝对不是调用者简单调用服务接口的问题,需要更高层次的业务封装,将上面这些操作封装为一个统一的服务,这个就是所谓的服务。最后一个要素服务总线,这就是我们本文所谈的重要主题:远程调用服务了。
这里谈谈SOA的目的是想起到抛砖引玉的作用,让那些想深入研究远程调用服务的人可以从SOA的角度理解远程调用服务,而那些还是不明白远程调用是何物的童鞋可以通过SOA的概念来理解远程调用服务。
三、远程调用服务技术详解
远程调用服务技术详解,详解,呜呜~~,这两个字很有压力,我怕有童鞋看了这个标题会以为我会将整套技术实现方案写到里面,这个难度太高了,写几万字估计都说不清楚,再说真的写的那么细致,估计很多人都看不懂了(嘿嘿,我自己也没有技术实现过哦,这些都是构思,构思哦),所以详解就是详解原理。
下面我将上篇文章的架构图放进来,大家再仔细看看这张图:
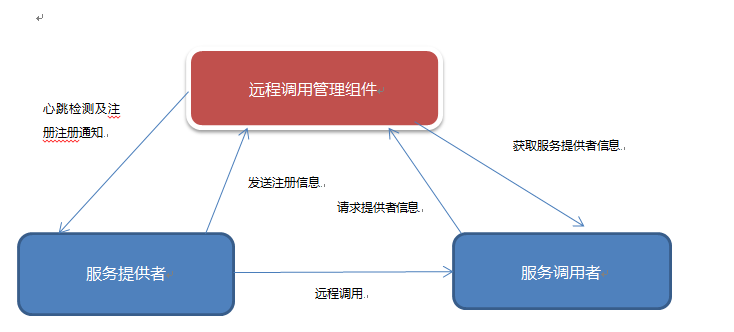
传统的服务调用都是服务提供者和服务调用者的直接调用,从架构图里我们看到这里多了一个远程调用管理组件,远程调用管理组件是一个独立的服务系统,为了保证该系统的稳定性,它也一定是一个分布式的系统,但是这个分布式系统和Web的分布式系统是完全不同的分布式系统,传统Web应用集群是基于HTTP协议的无状态的特点设计的,因为每个HTTP请求都是一个独立的事务,不同请求之间是没有任何关系的,所以我们可以将Web应用部署到不同服务器上,请求不管到了那台服务器,都能正常的给用户提供相应的服务,但是Web应用的session机制是有状态的,所以传统Web集群都是要有session同步的操作,大型网站往往会把session功能抽象为独立的缓存系统,但是这里的远程调用管理组件的集群原理或者说分布式原理是有别于Web应用集群分布式原理的,远程调用管理组件可以当做一个注册中心,它会记录下服务提供者和服务调用者的相关信息,并将这些信息推送给服务提供者或者服务调用者,为了保证系统的执行效率,这些注册信息都是记录在内存里,我们试想下,如果这些注册信息丢失,整个系统将会不可用,因此远程调用管理组件的集群是一种保证数据可靠性和服务提供健壮性的集群,而不是建立在HTTP无状态特性基础上的集群。我们这里假想下远程调用服务的集群运行场景,我们假如有5台服务器作为远程调用服务运行的服务器,那么每台服务器都必须有注册信息的冗余备份,当服务运行时候其中一台服务器发生了故障,这台故障的服务器上的数据不会丢失,此外集群应该还要有一个检查故障的机制,当发现有台服务器不可用的时候,能及时剔除该服务器,而zookeeper就是解决这种问题的技术框架。此外除了保证系统的稳定性和可用性外,集群的数据存储方式也是很重要的,前面我讲到集群的数据存储要有一个冗余机制,除了冗余机制还要有一个很适合快速访问和读写的数据模型,而zookeeper正好包含这种数据模型,所以我设计的远程调用服务是一个很适合zookeeper应用的场景,至于zookeeper的详细知识我会在下篇里详细讲到。
远程调用管理组件还有一个心跳机制,心跳机制的作用是检测服务提供者的健康性及服务提供者是否可用,服务提供者启动时候会将自己的注册信息发送给远程调用管理组件,这个注册信息里包含服务端的ip地址和端口号,远程调用管理组件会启动一个线程,根据定时对这个ip地址和端口号去ping这个ip和端口号对应的应用是否可用,如果不可用远程调用管理组件会反复尝试几次,这个次数和多久检测心跳都是可以配置的,如果反复几次还是不通,那么就认定该服务不可用了。有网友在QQ上问我,为什么不检测服务调用者的心跳,这个完全没必要哦,调用者是主动方,提供者是被动方,这就好比你访问网站,如果你生病了不去访问了,系统没有必要检查你是否已经生病了。
远程调用框架需要使用序列化和反序列化技术,这点也让很多童鞋不太理解,不理解的原因还是对序列化和反序列化技术的不理解,序列化技术主要是应用与数据持久化(数据存到硬盘)或者网络通讯,不管是数据存储到硬盘还是进行网络通讯,这些数据都会转化为二进制,序列化就是将正在运行的对象转化为可以存储和传输的二进制数据,而反序列化是可以将这些二进制数据反向还原成原来的对象信息,还原的对象还是可以被程序操作的,而我们设计的远程调用框架传递就是不同系统之间可以相互使用的程序代码,所以我们需要使用序列化和反序列化技术。这里就有一个问题,例如我们传输一个对象,这个对象对应的类是N多个类的继承子类,而且这个对象里可能还会引用其他的对象例如String,ArrayList等等,那么为了让反序列化的对象可用,序列化的时候就会将这些信息也包含在二进制数据里,并且这些信息一起进行网络传输,这就导致数据传输量特别大,而jdk自带的序列化机制会导致这些附带信息更大,所以有必要使用比jdk更好的序列化机制,让数据量变小,并且序列化和反序列化的效率更高,上篇文章里我推荐了一种序列化框架hession,当然用户想使用什么序列化机制这个我也让用户可以自己配置,这也是外部配置文件的一个选项。
前面文章里我还讲到了压缩技术并且推荐了google公司使用snappy,这个压缩技术也是为了让网络传输的数据量变小,提升网络的传输效率。
对于服务提供者和服务调用者我会提供一个jar包,这些工程都要引入这个jar包,同时还需要一个配置文件来定义一些需要用户定义的参数,例如我们使用一个名字叫ycdy_config.properties配置文件,里面的key值介绍如下:
Config_center_url=ip:port;这个就是配置远程管理中心的ip地址和端口号; Server_type=provider/consumer;配置是服务调用者还是提供者,不配置默认是提供者; Provider_post=9999,这是服务提供者的端口号,调用者可以不配置,其实调用配置了也没啥用,如果提供者不配置,会有默认值的; Provider_session_timeout=9000;服务提供者的超时时间,如果实际调用超过了这个时间,那么说明服务调用超时,适用于服务调用者,提供者无效 Tick_time=3000;心跳时间,这是远程调用中心检测服务端心跳的间隔时间,适用于服务提供者; Again_time=3;当服务提供者不通的时候,心跳反复检测的次数,超过了次数就标记该服务不可用;Provider_session_timeout、Tick_time和Again_time三者之间是有一定关系,这个关系要实现这具体把控了; Ip_include_pattern=172\\.17\\.138.*|192\\.168\\.0\\..*,这个适用于服务提供者,因为一台服务器可能存在多个ip地址,当远程调用服务组件接收到提供者的ip,用这个配置项来辨认那个ip可用,这里采用正则表达式的方式; Ip_exclude_pattern=用于服务提供者,需要忽略的ip; Consumer_policy=random/rotate;适用于调用者,调用者向提供者请求的负载均衡策略,我熟悉的只有两种一种是使用随机数,一种使轮询,所以这里目前就这两种选项; Monitor_log=true/false;是否开启监控日志,适用于服务提供者,任何系统日志时最重要的,否则没法查生产问题,其实这个配置项应该可以充实点,但是我现在还没想好,所以先给个提示,具体到了生产看如何实现吧。
大家看到了不管是作为服务提供者还是服务调用者使用的配置文件是一致的,而且一个应用既可以配置成服务的调用者也可以配置成服务的提供者,非常的灵活。
远程调用服务还需要一个重要的技术就是通讯技术,这里的通讯技术我推荐netty,netty是个非常好的选择,讲到通讯是个复杂的课题,如果以后有空我再做详细介绍,通讯层的东西是封装到服务提供者和服务调用者引入的jar包里,但是通讯的ip地址和端口号则是需要远程调用管理组件推送过来的。
那么在应用里远程调用服务到底如何使用了?哈哈,这时候spring就要上场了,我们看看服务调用者和服务提供者的spring配置,如下所示:
<!-- 服务提供者配置 --> <bean id="serverProvider" class="cn.com.sharpxiajun.RmifSpringProviderBean"> <property name="interfaceName" value="cn.com.ITest"></property><!-- 远程调用的接口 --> <property name="target" ref="clsTest"></property><!-- clsTest实现ITest的实现类,clsTest这里是一个bean的id值 --> </bean> <!-- 服务调用者配置 --> <bean id="clientConsumer" class="cn.com.sharpxiajun.RmifSpringConsumerBean"> <property name="interfaceName" value="cn.com.ITest"></property><!-- value就是Provider定义的target的接口实现类 --> <property name="serialType" value="hessian"></property><!--序列化方式 --> <property name="compressEnabled" value="true"></property><!-- 压缩标记 --> </bean>
我们发现这个新配置和以前不同了,这个配置将更加适合生成的开发。
我们首先看看serverProvider的设计,这个bean对应的class是cn.com.sharpxiajun.RmifSpringProviderBean,里面有个参数是一个interfaceName即提供者对外的接口,这里我会使用反射机制将接口注入到RmifSpringProviderBean,而target则是具体的实现对象了,这就是业务对象,注意interfaceName一定要是接口,因为调用者会根据接口进行转化,如果是类的话,那么通用性就很差了。
clientConsumer的设计,这个bean所对应的class是cn.com.sharpxiajun.RmifSpringConsumerBean,其中interfaceName的value值对应的就是远程定义的接口,和提供者的interfaceName保持一致,当提供者的数据传导调用者后,就会根据这个双方约定好的接口反序列化成可以操作的对象,serialType是选择序列化机制,不写的话就是调用jdk的序列化机制,这里附带提下啊,外部的序列化程序也是放到jar包里的哦,还有一个选项是compressEnabled作用是是否启用传输报文压缩。
当调用者调用提供者服务时候,jar包里netty程序会根据推送的信息(主要是ip,端口)和spring配置的bean结合起来就可以完成一次服务的调用。
好了,上篇写好了,本篇主要是讲解远程调用服务的架构设计,我自我感觉这篇文章比上篇更接地气,希望看了本文的童鞋,能对远程调用框架设计的原理更加清晰。
其实netty的使用学问也很大,也是远程调用服务的核心之一,本文这块讲的比较少,以后有时间我尽量补充上这块知识。
下篇文章我将详细介绍远程调用框架里使用到的zookeeper技术。
这是2013年的最后一篇博文了,祝大家新年快乐哦。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号