面向对象设计与构造2019 第三单元总结博客作业
面向对象设计与构造2019 第三单元总结博客作业
作业回顾
- 3.1 JML(Path,PathContainer)
- 3.2 JML+(Graph)
- 3.3 JML++(RailwaySystem)
一、JML语言的理论基础和工具链
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言
(Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。所谓接口即一个方法或类型外部可见的内容通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。
一般而言,JML有两种主要的用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规
格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
JML以注释的形式存在于代码中,编译时不会对编译器产生影响,但是可以在程序员编程的时候给予提示。
JML常用的工具包括OpenJML,用于判断书写的JML语法正确性等;SMT Solver可以用于检查程序实现是否满足所设计的规格,封装在OpenJML中。JMLUnitNG可以自动生成测试用例,来测试程序实现的正确性。
二、使用JMLUnit对Graph接口进行测试
JMLUnitNG的使用步骤大致如下:
生成测试文件
jmlunitng MyPath.java
编译测试文件
javac MyPath_JML_Test.java
编译MyPath.java
javac MyPath.java
运行测试
java MyPath_JML_Test
测试结果如图所示:
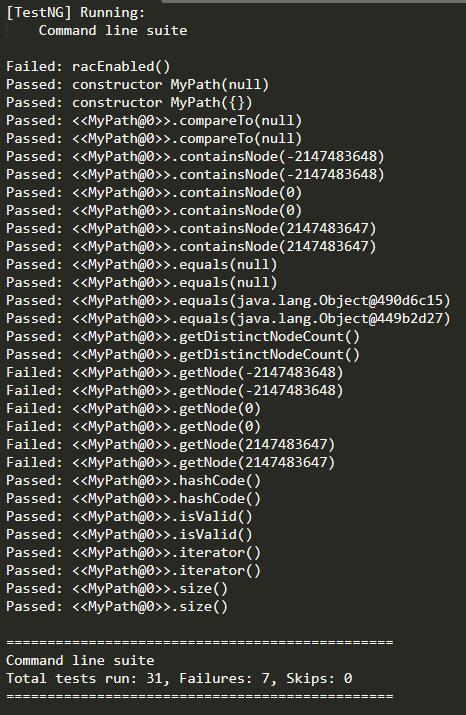
可见,由于JMLUnitNG测试了一些非法数据,导致我们的程序并没有完全通过。JMLUnitNG能够对一些极端情况进行测试,达到人工手动测试不容易达到的效果。
三、梳理自己的架构设计
这三次作业的每一次作业,我都是以接近重构的方法去完成。这一点可以通过我三次作业中类的不同属性看出来。
第一次:
public class MyPath implements Path {
private int[] nodes;
private HashMap<Integer, Integer> arr;
}
public class MyPathContainer implements PathContainer {
private HashMap<Path, Integer> plist;
private HashMap<Integer, Path> pidlist;
private int pidcount = 0;
private HashMap<Integer, Integer> arr;
}
第二次:
public class MyPath implements Path {
private int[] nodes;
private HashMap<Integer, Integer> arr;
}
public class MyGraph implements Graph {
private HashMap<Path, Integer> plist;
private HashMap<Integer, Path> pidlist;
private HashMap<Integer, Integer> arr;
private HashMap<Integer, Integer> dmap;
private Stack<Integer> freeList;
private int[][] gpmap = new int[260][260];
private int[][] shpath = new int[260][260];
private int pidcount = 0;
}
第三次:
public class MyPath implements Path {
private HashMap<Integer, Integer> indexes;
// <index, nodeID> to decrease the time complexity
private HashMap<Integer, Integer> distinct;
// <nodeID, index> to manage distinct nodes
private HashMap<int[], Integer> fullmap = new HashMap<>();
private HashMap<int[], Integer> valuemap = new HashMap<>();
}
public class MyRailwaySystem implements RailwaySystem {
private HashMap<Path, Integer> pathList; // <path, pathID>
private HashMap<Integer, Path> pidList; // <pathID, path>
private HashMap<Integer, Integer> nodeCount; // <nodeID, count>
private HashMap<Integer, Integer> mapList; // <nodeID, reflectNodeID>
private Stack<Integer> freeStack; // free node stack
private int[][] weightMap = new int[130][130];
private int[][] distanceMap = new int[130][130];
private int[][] priceMap = new int[130][130];
private int[][] transferMap = new int[130][130];
private int[][] valueMap = new int[130][130];
private int[] validNode = new int[130];
private int counter;
private int connected;
}
我并没有使用继承先前类的方法去做每一次的作业。因为每次作业都会在容器类中增加新的属性,而这些属性需要在add和remove的时候进行修改,需要重写这些方法。所以我以为,与其在继承的时候重写这些方法,不如直接开新的类去完成这些任务。
本质上,这三次作业的接口一脉相承,但是实现方法上却有很大不同。每一次作业对算法的要求都更进一步,对我们也是一种考验。因为我们需要用add和remove方法构建缓存,所以每次作业都要重写add和remove方法,而其他的查询方法只需要几笔带过。
四、分析代码的BUG与修复情况
这次作业,我没有在公测和互测中被检测出bug,但是本地调试也不是一遍过。本地出现的错误,更多是体现在“超时”上面。我认为,要做好本次作业,需要注意两点:
-
算法的选择
我们所选择算法的时间复杂度一定要控制好,比如第三次作业的算法,如果使用深度优先搜索无脑爆搜,时间复杂度只能是指数级增长,会造成非常严重的超时,根本无法完成本次作业。如果选择拆点法或者边合并法,能够非常有效的降低时间复杂度,减轻程序的负担。
-
善用缓存机制
第二、三次作业对图结构变更的指令条数有严格的限制,但对查询指令却没有。如果每次查询都是实时运算,那必然会导致超时。相反的,我们只要在图结构变更的时候就计算好结果并存入相应的数据结构中,查询时只需要访问那个结构就可以完成任务。第三次作业如果不使用这种方法,没有丝毫通过评测的可能。
五、阐述规格和理解的心得体会
这次作业更像是一次算法与数据结构的作业,思考量都集中在如何去降低我们程序的复杂度上,而不是怎么去实现我们的程序了。JML语言虽然能清楚地告诉我们“你要做什么”,却没有能力告诉我们“你要怎么做”。当然了,如果连这一点都告诉我们,那这门语言已经可以成为一门新的编程语言,也就失去了其规格的价值。
规格语言有其自己的侧重点,它更像是一张蓝图,为我们规划好程序的作用,却在实现上没有很大的帮助。打个比方,“在建党一百年时,全面建成小康社会;在建国一百年时,建成社会主义现代化强国”就像是咱们的规格语言,而具体的脱贫攻坚战打法,就类似于我们程序员的工作。这种契约化的编程模式,为需求者和实现者进行了很好的分工,具有可以预见的工业价值。
