
hive+mysql的伪分布式数据仓库搭建
1.前言
1.1所使用的配置
VMware 16pro #虚拟机
sudo apt-get install mysql-server
sudo apt-get install mysql-client
2.2修改密码
打开cnf文件新增一行 skip-grant-tables ,重启mysql然后登陆,无密码直接登陆
vim /etc/mysql/mysql.conf.d/mysqld.cnf
service mysql restart
mysql -u root -p
然后切换到mysql的数据库修改密码,然后输入 quit;退出,再删除skip-grant-tables
use mysql update user set authentication_string='123456' where user = 'root'; flush privileges; ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
启动navicat代码
chmod +x navicat16-premium-en.AppImage ./navicat16-premium-en.AppImage
tar -xvf jdk-8u202-linux-x64.tar.gz -C #记得切换到tar所在目录下
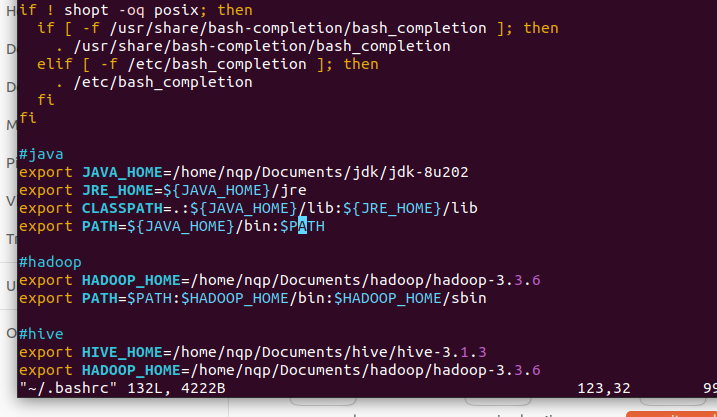
#java
export JAVA_HOME=/home/nqp/Documents/jdk/jdk-8u202
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
sudo tar -xvf ~/soft/hadoop-3.3.6.tar.gz -C
3.2修改配置
修改~/.bashrc
#hadoop export HADOOP_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

core-site.xml

<!-- 描述集群中NameNode结点的URI(包括协议、主机名称、端口号) -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-ubuntu:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/nqp/Documents/hadoop/hadoop-3.3.6/tmp</value>
</property>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/nqp/Documents/hadoop/hadoop-3.3.6/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/nqp/Documents/hadoop/hadoop-3.3.6/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
mapred-site.xml
#MapReduce的执行模式,默认是本地模式
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property>#当开启后,小作业会在一个JVM上顺序运行,而不需要额外申请资源 <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6</value> </property>
yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm-ubuntu</value>
</property>
<property>#NodeManager上运行的附属服务
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否开启聚合日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 存储容器日志的地方 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/nqp/Documents/hadoop/hadoop-3.3.6/logs</value>
</property>
3.3sqoop
export HADOOP_COMMON_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6
export HADOOP_MAPRED_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6
export HIVE_HOME=/home/nqp/Documents/hive/hive-3.1.3
#测试链接mysql
/home/nqp/Documents/sqoop/sqoop-1.4.7/bin/sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password 123456
1 | sudo tar -zxvf apache-hive-3.1.3-bin.tar.gz |
连接mysql数据库
schematool -dbType mysql -initSchema
--hive-overwrite --incremental append:使用此选项执行增量追加导入。Sqoop 将仅追加新的数据到现有的 Hive 表中,而不会删除或覆盖现有数据。这适用于源数据是递增的情况,例如每天追加一天的数据。
配置文件
修改~/.bashrc
#hive
export HIVE_HOME=/home/nqp/Documents/hive/hive-3.1.3
export HADOOP_HOME=/home/nqp/Documents/hadoop/hadoop-3.3.6
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_CLASSPATH=$HADOOP_HOME/lib/*
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
export HIVE_CONF_DIR=$HIVE_HOME/conf
<!-- 描述集群中NameNode结点的URI(包括协议、主机名称、端口号) -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?useSSL=False&createDatabaseIfNotExist=True</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/nqp/Documents/hive/hive-3.1.3/warehouse</value>
</property>
#使用内置derby
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:/path/to/metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/path/to/hive/warehouse</value>
</property>4.2配置驱动
更换common-lang-2.6的包
sudo dpkg -i mysql-connector-j_8.1.0-1ubuntu22.04_all.deb
cp mysql-connector-java-8.1.0.jar /home/nqp/Documents
5.建立ods层
#创建ods_user表
CREATE EXTERNAL TABLE IF NOT EXISTS ods_user (
createtime TIMESTAMP,
id INT,
usercode STRING,
username STRING,
userpwd STRING,
userstatus STRING
)
#创建ods_book表
CREATE EXTERNAL TABLE IF NOT EXISTS ods_book (
author STRING,
bookcode STRING,
bookcount INT,
bookname STRING,
booktype STRING,
createtime TIMESTAMP,
id INT
);
#创建ods_order表
CREATE EXTERNAL TABLE IF NOT EXISTS ods_order (
createtime TIMESTAMP,
id INT,
ordercode STRING,
remark STRING
)
#创建ods_book_order表
CREATE EXTERNAL TABLE IF NOT EXISTS ods_book_order (
bookid INT,
booknum INT,
createtime TIMESTAMP,
id INT,
lendtime INT,
orderid INT,
ordertype STRING,
saledamount DECIMAL
)
SET hive.cli.print.header=true;
#创建外部表的通用模板
CREATE EXTERNAL TABLE table_name (
column1 data_type,
column2 data_type,
...
)
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','
STORED AS ORC
LOCATION 'hdfs_path';
hdfs dfs -rm -r hdfs://vm-ubuntu:9000/user/nqp/sys_user
#导入ods_user
bin/sqoop import --connect jdbc:mysql://localhost:3306/mis --username root --password 123456 --table sys_user --hive-import --hive-database warehouse --hive-table ods_user --hive-overwrite
#导入ods_book
bin/sqoop import --connect jdbc:mysql://localhost:3306/mis --username root --password 123456 --table sys_book --hive-import --hive-database warehouse --hive-table ods_book
--hive-overwrite
#导入ods_order
bin/sqoop import --connect jdbc:mysql://localhost:3306/mis --username root --password 123456 --table sys_order --hive-import --hive-database warehouse --hive-table ods_order
--hive-overwrite
#导入ods_book_order
bin/sqoop import --connect jdbc:mysql://localhost:3306/mis --username root --password 123456 --table book_order --hive-import --hive-database warehouse --hive-table ods_book_order
--hive-overwrite
--check-column 在确定应该导入哪些行时,指定被检查的列。
--incremental 指定sqoop怎样确定哪些行是新行。有效值是append、lastmodified
--last-value 指定已经导入数据的被检查列的最大值(第一次需要指定,以后会自动生成)
#增量载入
CREATE TABLE IF NOT EXISTS lendbook (
lendId INT,
bookId INT,
bookName STRING,
bookType STRING,
lendTime INT,
orderId INT,
orderType STRING
);
INSERT INTO lendbook
SELECT
obo.id AS lendId,
obo.bookid AS bookId,
ob.bookname AS bookName,
ob.booktype AS bookType,
obo.lendtime AS lendTime,
obo.orderid AS orderId,
obo.ordertype AS orderType,
FROM
ods_book_order obo
JOIN
ods_book ob ON obo.bookid = ob.id
WHERE
obo.ordertype = 'lend';
CREATE TABLE IF NOT EXISTS salebook (
lendId INT,
bookId INT,
bookName STRING,
bookType STRING,
saledAmount DECIMAL,
orderId INT,
orderType STRING
);
INSERT INTO salebook
SELECT
obo.id AS lendId,
obo.bookid AS bookId,
ob.bookname AS bookName,
ob.booktype AS bookType,
obo.orderid AS orderId,
obo.ordertype AS orderType,
obo.saledamount AS saledAmount
FROM
ods_book_order obo
JOIN
ods_book ob ON obo.bookid = ob.id
WHERE
obo.ordertype = 'sale';


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现