[MapReduce_add_3] MapReduce 通过分区解决数据倾斜
0. 说明
数据倾斜及解决方法的介绍与代码实现
1. 介绍
【1.1 数据倾斜的含义】
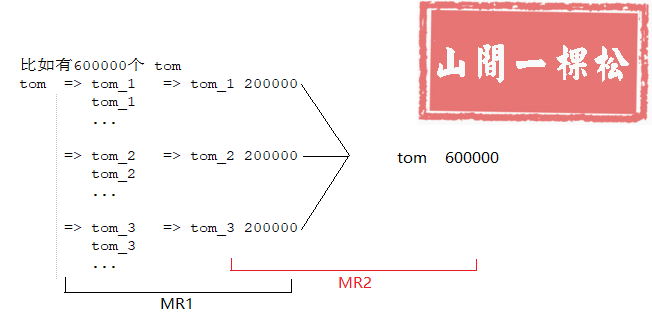
大量数据发送到同一个节点进行处理,造成此节点繁忙甚至瘫痪,而其他节点资源空闲
【1.2 解决数据倾斜的方式】
重新设计 Key(配合二次 MR 使用)
随机分区
伪代码如下:
RandomPartition extends Partitioner{ return r.nextInt() }
2. 重新设计 Key 代码编写
[2.1 WCMapper.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.Random; /** * Mapper 程序 * 重新设计 Key */ public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Random r = new Random(); int i; @Override protected void setup(Context context) throws IOException, InterruptedException { // 获取 reduce 的个数 i = context.getNumReduceTasks(); } /** * map 函数,被调用过程是通过 while 循环每行调用一次 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将 value 变为 String 格式 String line = value.toString(); // 将一行文本进行截串 String[] arr = line.split(" "); for (String word : arr) { String newWord = word + "_" + r.nextInt(i); context.write(new Text(newWord), new IntWritable(1)); } } }
[2.2 WCReducer.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer 类 */ public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * 通过迭代所有的 key 进行聚合 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } context.write(key,new IntWritable(sum)); } }
[2.3 WCMapper2.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper 程序2 * 重新设计 Key */ public class WCMapper2 extends Mapper<LongWritable, Text, Text, IntWritable> { /** * map 函数,被调用过程是通过 while 循环每行调用一次 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将 value 变为 String 格式 String line = value.toString(); // 切割一行文本分为 key 和 value String[] arr = line.split("\t"); String word = arr[0]; Integer count = Integer.parseInt(arr[1]); // 重新设计 Key String newWord = word.split("_")[0]; context.write(new Text(newWord), new IntWritable(count)); } }
[2.4 WCReducer2.java]
package hadoop.mr.dataskew; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer 类2 */ public class WCReducer2 extends Reducer<Text, IntWritable, Text, IntWritable> { /** * 通过迭代所有的 key 进行聚合 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } context.write(key,new IntWritable(sum)); } }
[2.5 WCApp.java]
package hadoop.mr.dataskew; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 解决数据倾斜 */ public class WCApp { public static void main(String[] args) throws Exception { // 初始化配置文件 Configuration conf = new Configuration(); // 仅在本地开发时使用 conf.set("fs.defaultFS", "file:///"); // 初始化文件系统 FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job Job job = Job.getInstance(conf); // 设置 job 名称 job.setJobName("data skew"); // job 入口函数类 job.setJarByClass(WCApp.class); // 设置 mapper 类 job.setMapperClass(WCMapper.class); // 设置 reducer 类 job.setReducerClass(WCReducer.class); // 设置分区数量 job.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径 Path pin = new Path("E:/test/wc/dataskew.txt"); Path pout = new Path("E:/test/wc/out"); // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); FileInputFormat.addInputPath(job, pin); FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout)) { fs.delete(pout, true); } // 执行 job boolean b = job.waitForCompletion(true); if (b) { // 通过配置文件初始化 job Job job2 = Job.getInstance(conf); // 设置 job 名称 job2.setJobName("data skew2"); // job 入口函数类 job2.setJarByClass(WCApp.class); // 设置 mapper 类 job2.setMapperClass(WCMapper2.class); // 设置 reducer 类 job2.setReducerClass(WCReducer2.class); // 设置分区数量 // job2.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型 job2.setMapOutputKeyClass(Text.class); job2.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径 Path pin2 = new Path("E:/test/wc/out"); Path pout2 = new Path("E:/test/wc/out2"); // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); FileInputFormat.addInputPath(job2, pin2); FileOutputFormat.setOutputPath(job2, pout2); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout2)) { fs.delete(pout2, true); } // 执行 job job2.waitForCompletion(true); } } }
3. 随机分区代码编写
[3.1 WCMapper.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper 程序 * 重新设计 Key */ public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * map 函数,被调用过程是通过 while 循环每行调用一次 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将 value 变为 String 格式 String line = value.toString(); // 将一行文本进行截串 String[] arr = line.split(" "); for (String word : arr) { context.write(new Text(word), new IntWritable(1)); } } }
[3.2 WCReducer.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer 类 */ public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * 通过迭代所有的 key 进行聚合 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } context.write(key, new IntWritable(sum)); } }
[3.3 WCMapper2.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper 程序2 * 重新设计 Key */ public class WCMapper2 extends Mapper<LongWritable, Text, Text, IntWritable> { /** * map 函数,被调用过程是通过 while 循环每行调用一次 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将 value 变为 String 格式 String line = value.toString(); // 切割一行文本分为 key 和 value String[] arr = line.split("\t"); String word = arr[0]; Integer count = Integer.parseInt(arr[1]); context.write(new Text(word), new IntWritable(count)); } }
[3.4 RandomPartitioner.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; import java.util.Random; /** * 随机分区类 */ public class RandomPartitioner extends Partitioner<Text, IntWritable> { Random r = new Random(); @Override public int getPartition(Text text, IntWritable intWritable, int numPartitions) { return r.nextInt(numPartitions); } }
[3.5 WCApp.java]
package hadoop.mr.dataskew2; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 随机分区解决数据倾斜 */ public class WCApp { public static void main(String[] args) throws Exception { // 初始化配置文件 Configuration conf = new Configuration(); // 仅在本地开发时使用 conf.set("fs.defaultFS", "file:///"); // 初始化文件系统 FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job Job job = Job.getInstance(conf); // 设置 job 名称 job.setJobName("data skew"); // job 入口函数类 job.setJarByClass(WCApp.class); // 设置 mapper 类 job.setMapperClass(WCMapper.class); // 设置 reducer 类 job.setReducerClass(WCReducer.class); // 设置 partition 类 job.setPartitionerClass(RandomPartitioner.class); // 设置分区数量 job.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径 Path pin = new Path("E:/test/wc/dataskew.txt"); Path pout = new Path("E:/test/wc/out"); // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); FileInputFormat.addInputPath(job, pin); FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout)) { fs.delete(pout, true); } // 执行 job boolean b = job.waitForCompletion(true); if (b) { // 通过配置文件初始化 job Job job2 = Job.getInstance(conf); // 设置 job 名称 job2.setJobName("data skew2"); // job 入口函数类 job2.setJarByClass(hadoop.mr.dataskew.WCApp.class); // 设置 mapper 类 job2.setMapperClass(WCMapper2.class); // 设置 reducer 类 job2.setReducerClass(WCReducer.class); // 设置分区数量 // job2.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型 job2.setMapOutputKeyClass(Text.class); job2.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job2.setOutputKeyClass(Text.class); job2.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径 Path pin2 = new Path("E:/test/wc/out"); Path pout2 = new Path("E:/test/wc/out2"); // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); FileInputFormat.addInputPath(job2, pin2); FileOutputFormat.setOutputPath(job2, pout2); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout2)) { fs.delete(pout2, true); } // 执行 job job2.waitForCompletion(true); } } }
且将新火试新茶,诗酒趁年华。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号