[MapReduce_7] MapReduce 中的排序
0. 说明
部分排序 && 全排序 && 采样 && 二次排序
1. 介绍
sort 是根据 Key 进行排序
【部分排序】
在每个分区中,分别进行排序,默认排序即部分排序
【全排序】
在所有的分区中,整体有序
实现全排序的方案:
1. 使用一个 reduce
2. 自定义分区函数
3. 采样
【3.1 随机采样】
对于纯文本数据支持不友好
0. 纯文本建议使用 KeyValueTextInputFormat
1. 设置分区类 TotalOrderPartition(MR中存在此类 )
2. 初始化采样器 (RandomSampler) => InputSampler.RandomSampler<Text,Text> sampler = new InputSampler.RandomSampler<Text,Text>(0.01,10);
3. 设置采样数据地址 => TotalOrderPartitioner.setPartitionFile(job.getConfiguration(),new Path("E:/test/wc/out3"));
4. 写入采样数据 => InputSampler.writePartitionFile(job,sampler);
5. 注意1-4步必须写在配置文件之后,job 执行之前
// new InputSampler.RandomSampler<Text,Text>(0.01,10);
// 0.01(freq) 每个 Key 被选中的概率
// 对于每个key都会产生一个0-1之间的浮点数,小于此浮点数的key会被选中
// 10(numSamples) 样本个数
// 定义一个10长度的数组,被选中的 Key 回到此数组中
// 最终从数组中随机选择2个样本
【3.2 切片采样】
对每个数据切片取前n个值
first numSamples / numSplits
10 / 3
【3.3 间隔采样】
每隔一段间隔采样数据 => new InputSampler.IntervalSampler<Text,Text>(0.01);
对于每个切片样本,当保留的记录数与总记录计数之比小于指定频率时发出
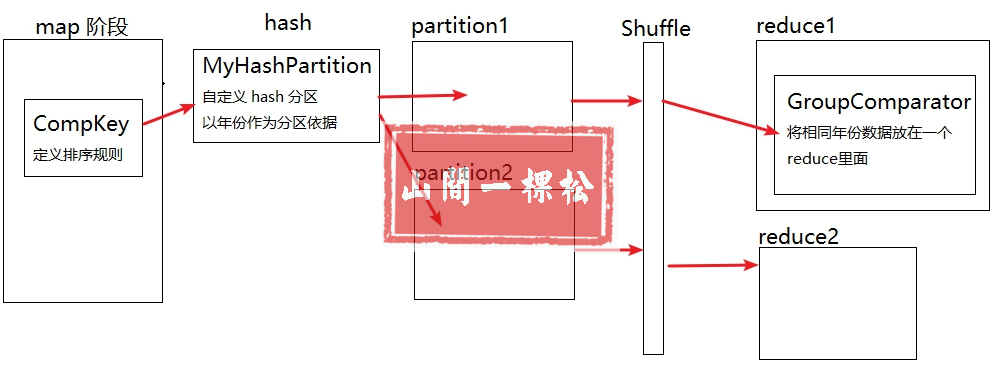
【二次排序】
在对 Key 进行排序的基础上,对 Value 进行排序
1. 重写组合 Key (Compkey) Year+Temp //在对key进行排序的基础上,对 Value 进行排序
2. 重写分组对比器,使得在 year 相等的情况下则证明 Compkey 相等 //GroupComparator
流程图如下
2. 全排序(自定义分区函数)
[2.1 PassMapper.java]
package hadoop.mr.sort.total; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * mapper 类 * 对原始数据进行预处理 */ public class PassMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 将 value 变为 String 格式 String line = value.toString(); // 将一行文本进行截串 String[] arr = line.split("\t"); // 过滤不符合规范的数据 if (arr.length >= 3) { String pass = arr[2]; if (pass != null) { context.write(new Text(pass), new IntWritable(1)); } } } }
[2.2 PassReducer.java]
package hadoop.mr.sort.total; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class PassReducer extends Reducer<Text,IntWritable,Text,IntWritable> { /** * 通过迭代所有的key进行聚合 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for(IntWritable value : values){ sum += value.get(); } context.write(key,new IntWritable(sum)); } }
[2.3 PassPartition.java]
package hadoop.mr.sort.total; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 自定义分区实现全排序 */ public class PassPartition extends Partitioner<Text, IntWritable> { @Override public int getPartition(Text text, IntWritable intWritable, int numPartitions) { String key = text.toString(); if (key.compareTo("9") < 0) { return 0; } if (key.compareTo("f") < 0) { return 1; } else return 2; } }
[2.4 PassApp.java]
package hadoop.mr.sort.total; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 对密码进行全排序 * 通过自定义分区实现全排序 */ public class PassApp { public static void main(String[] args) throws Exception { // 初始化配置文件 Configuration conf = new Configuration(); // 仅在本地开发时使用 conf.set("fs.defaultFS", "file:///"); // 初始化文件系统 FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job Job job = Job.getInstance(conf); // 设置 job 名称 job.setJobName("pass count"); // job 入口函数类 job.setJarByClass(PassApp.class); // 设置 mapper 类 job.setMapperClass(PassMapper.class); // 设置 reducer 类 job.setReducerClass(PassReducer.class); // 设置 partition 类 job.setPartitionerClass(PassPartition.class); // 设置 combiner 类 // job.setCombinerClass(PassReducer.class); // 设置分区数量 job.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入路径和输出路径 Path pin = new Path("E:/file/duowan_user.txt"); Path pout = new Path("E:/test/wc/out"); // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); FileInputFormat.addInputPath(job, pin); FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout)) { fs.delete(pout, true); } // 执行 job job.waitForCompletion(true); } }
3. 采样 (随机采样、切片采样、间隔采样)
[3.1 PassMapper.java]
package hadoop.mr.sort.sampling; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * mapper 类 * 对原始数据进行预处理 */ public class PassMapper extends Mapper<Text, Text, Text, IntWritable> { @Override protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { context.write(key, new IntWritable(Integer.parseInt(value.toString()))); } }
[3.2 PassReducer.java]
package hadoop.mr.sort.sampling; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class PassReducer extends Reducer<Text,IntWritable,Text,IntWritable> { /** * 通过迭代所有的key进行聚合 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for(IntWritable value : values){ sum += value.get(); } context.write(key,new IntWritable(sum)); } }
[3.3 PassApp.java]
package hadoop.mr.sort.sampling; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.partition.InputSampler; import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner; /** * 对密码进行全排序 * 通过自定义分区实现全排序 * <p> * 先通过部分排序得到数据 * 将输入路径指向部分排序结果输出路径 */ public class PassApp { public static void main(String[] args) throws Exception { // 初始化配置文件 Configuration conf = new Configuration(); // 仅在本地开发时使用 conf.set("fs.defaultFS", "file:///"); // 初始化文件系统 FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job Job job = Job.getInstance(conf); // 设置 job 名称 job.setJobName("pass count"); // job 入口函数类 job.setJarByClass(PassApp.class); // 设置 mapper 类 job.setMapperClass(PassMapper.class); // 设置 reducer 类 job.setReducerClass(PassReducer.class); // 设置 combiner 类 // job.setCombinerClass(PassReducer.class); // 设置全排序采样类 TotalOrderPartitioner.class job.setPartitionerClass(TotalOrderPartitioner.class); // 设置分区数量 job.setNumReduceTasks(3); // 设置 map 的输出 K-V 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置 reduce 的输出 K-V 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置输入格式 job.setInputFormatClass(KeyValueTextInputFormat.class); // 设置输入路径和输出路径 Path pin = new Path("E:/test/wc/out"); Path pout = new Path("E:/test/wc/out2"); // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); FileInputFormat.addInputPath(job, pin); FileOutputFormat.setOutputPath(job, pout); /** * 随机采样,比较浪费性能,耗费资源 * @param freq 每个key被选择的概率 ,大于采样数(2) / 所有key数量(n) * @param numSamples 所有切片中需要选择的key数量 */ // 设置采样器类型,随机采样 // InputSampler.RandomSampler<Text, Text> sampler = new InputSampler.RandomSampler<Text, Text>(0.01, 10); // 设置采样器类型,切片采样,对有序的数据不友好 // InputSampler.SplitSampler<Text, Text> sampler = new InputSampler.SplitSampler<Text, Text>(10, 3); // 设置采样器类型,间隔采样 InputSampler.IntervalSampler<Text,Text> sampler = new InputSampler.IntervalSampler<Text, Text>(0.01,3); // 设置采样数据地址 TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path("E:/test/wc/out3")); // 写入采样数据 InputSampler.writePartitionFile(job, sampler); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout)) { fs.delete(pout, true); } // 执行 job job.waitForCompletion(true); } }
4. 二次排序
[4.1 CompKey.java]
package hadoop.mr.sort.secondary; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 组合 Key , 包含自定义的排序规则 && 序列反序列化 */ public class CompKey implements WritableComparable<CompKey> { private String year; private int temp; // 定义排序规则 public int compareTo(CompKey o) { String oyear = o.getYear(); String tyear = this.getYear(); int otemp = o.getTemp(); int ttemp = this.getTemp(); // 如果传入的参数 year 和本身的 year 相同,则比较温度 if (oyear.equals(tyear)) { return otemp - ttemp; } // 年份不同,则返回两个 year 的比较值 return oyear.compareTo(tyear); } // 串行化 public void write(DataOutput out) throws IOException { out.writeUTF(year); out.writeInt(temp); } // 反串行化 public void readFields(DataInput in) throws IOException { this.setYear(in.readUTF()); this.setTemp(in.readInt()); } @Override public String toString() { return "CompKey{" + "year='" + year + '\'' + ", temp=" + temp + '}'; } public CompKey() { } public CompKey(String year, int temp) { this.year = year; this.temp = temp; } public String getYear() { return year; } public void setYear(String year) { this.year = year; } public int getTemp() { return temp; } public void setTemp(int temp) { this.temp = temp; } }
[4.2 MyHashPartition.java]
package hadoop.mr.sort.secondary; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Partitioner; /** * 自定义 hash 分区 */ public class MyHashPartition extends Partitioner<CompKey, NullWritable> { public int getPartition(CompKey compKey, NullWritable nullWritable, int numPartitions) { String year = compKey.getYear(); return (year.hashCode() & Integer.MAX_VALUE) % numPartitions; } }
[4.3 SortMapper.java]
package hadoop.mr.sort.secondary; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * Mapper 程序 */ public class SortMapper extends Mapper<LongWritable, Text, CompKey, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] arr = value.toString().split("\t"); String year = arr[0]; int temp = Integer.parseInt(arr[1]); CompKey ck = new CompKey(year, temp); context.write(ck, NullWritable.get()); } }
[4.4 SortReducer.java]
package hadoop.mr.sort.secondary; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * Reducer 程序 */ public class SortReducer extends Reducer<CompKey, NullWritable, Text, IntWritable> { @Override protected void reduce(CompKey key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { for (NullWritable value : values) { String year = key.getYear(); int temp = key.getTemp(); context.write(new Text(year), new IntWritable(temp)); } } }
[4.5 MyGroupComparator.java]
package hadoop.mr.sort.secondary; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * 分组对比器,自定义 key 业务逻辑,将 1902 20 1902 30 识别为同一个 key */ public class MyGroupComparator extends WritableComparator { // 必须写,创建实例必须写 true protected MyGroupComparator() { super(CompKey.class, true); } // 比较算法,只要 year 相等则证明 key 相等 @Override public int compare(WritableComparable a, WritableComparable b) { CompKey ck1 = (CompKey) a; CompKey ck2 = (CompKey) b; return ck1.getYear().compareTo(ck2.getYear()); } }
[4.6 SortApp.java]
package hadoop.mr.sort.secondary; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 二次排序 App */ public class SortApp { public static void main(String[] args) throws Exception { // 初始化配置文件 Configuration conf = new Configuration(); // 仅在本地开发时使用 conf.set("fs.defaultFS", "file:///"); // 初始化文件系统 FileSystem fs = FileSystem.get(conf); // 通过配置文件初始化 job Job job = Job.getInstance(conf); // 设置 job 名称 job.setJobName("Secondary Sort"); // job 入口函数类 job.setJarByClass(SortApp.class); // 设置 mapper 类 job.setMapperClass(SortMapper.class); // 设置 reducer 类 job.setReducerClass(SortReducer.class); // 设置自定义分区 job.setPartitionerClass(MyHashPartition.class); // 设置分区数量 job.setNumReduceTasks(3); // 设置分组对比器 job.setGroupingComparatorClass(MyGroupComparator.class); // 设置 map 的输出 K-V 类型 job.setMapOutputKeyClass(CompKey.class); job.setMapOutputValueClass(NullWritable.class); // 设置 reduce 的输出 K-V 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 新建输入输出路径 Path pin = new Path("E:/file/kv.txt"); Path pout = new Path("E:/test/wc/out"); // 打包后自定义输入输出路径 // Path pin = new Path(args[0]); // Path pout = new Path(args[1]); // 设置输入路径和输出路径 FileInputFormat.addInputPath(job, pin); FileOutputFormat.setOutputPath(job, pout); // 判断输出路径是否已经存在,若存在则删除 if (fs.exists(pout)) { fs.delete(pout, true); } // 执行 job job.waitForCompletion(true); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号