[MapReduce_4] MapTask 并发数的决定机制
0. 说明
介绍 && Map 个数 & Reduce 个数指定 && Map 切片计算
1. 介绍
一个 job 的 Map 阶段并行度由客户端在提交 job 时决定
客户端对 Map 阶段并行度的规划基本逻辑为:
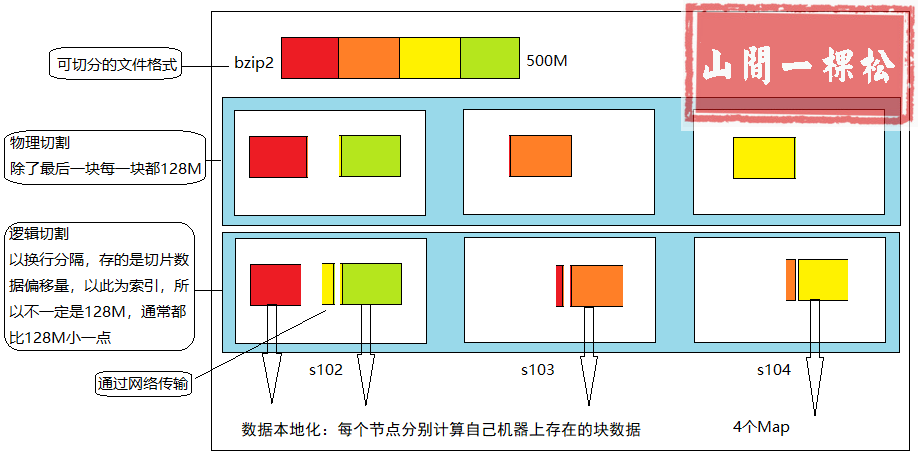
1. 将待处理的文件进行逻辑切片(根据切片大小,逻辑上划分多个 split ),然后每一个 split 分配一个 MapTask 并行处理实例
2. 具体切片规划是由 FileInputFormat 实现类的 getSplits()方法 完成
2. Map 个数 & Reduce 个数指定
Map个数指定:
- 根据文件个数指定
- 根据压缩文件可切割性
Reduce个数指定:
job.setNumReduceTasks(3);
3. Map 切片计算
【3.1 通过文件类型判断是否可切片】
判断文件类型(是否可切割),通过文件名后缀的反转来进行编解码器的判断
- 无压缩编解码器 // 可切割
- 可切割的压缩编解码器 // 可切割
- 不可切割的压缩编解码器 // 不可切割,切片大小即文件大小
SequenceFile
可切割,无论用什么压缩方式,或压缩编解码器
【3.2 切片计算】
最大切片值(MaxValue): Long.MAX_VALUE
最小切片值(MinValue): 1
块大小(BlockSize ): 32M(本地模式) 128M(分布式)
切片计算
Math.max(MinValue , Math.min(MaxValue,BlockSize));
通过设置最大切片值和最小切片值确定切片大小
// 设置最大切片大小 FileInputFormat.setMaxInputSplitSize(job,100); // 设置最小切片大小 FileInputFormat.setMinInputSplitSize(job,100);
【3.3 总结逻辑切割】
1、先进行数据切片,切片结果保留在 temp 下,job.split,里面存有切片数据偏移量索引
2、每个 Map 通过此索引来计算属于自己的切片数据
且将新火试新茶,诗酒趁年华。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号