[Spark Core] 在 Spark 集群上运行程序
0. 说明
将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行。
1. 打包程序
1.0 前提
搭建好 Spark 集群,完成代码的编写。
1.1 修改代码
【添加内容,判断参数的有效性】
// 判断参数的有效性 if (args == null || args.length == 0) { throw new Exception("需要指定文件路径") ; }
【注释掉 conf.setMaster("...")】
// 不用写,在提交代码的时候通过 spark-submit --master ... 自动生成 // conf.setMaster("spark://s101:7077")
【将加载文件部分由固定路径改为读取传入的路径参数】
// 1. 加载文件 val rdd1 = sc.textFile(args(0))
【原代码参考】
Spark 实现标签生成 中 Scala 代码部分
【修改过的代码如下】
import java.util import com.share.util.TagUtil import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD /** * 标签生成 */ object TaggenCluster { def main(args: Array[String]): Unit = { // 判断参数的有效性 if (args == null || args.length == 0) { throw new Exception("需要指定文件路径") ; } // 创建 spark 配置对象 val conf = new SparkConf() conf.setAppName("TaggenScalaApp") // 不用写,在提交代码的时候通过 spark-submit --master ... 自动生成 // conf.setMaster("spark://s101:7077") // 创建上下文 val sc = new SparkContext(conf) // 1. 加载文件 val rdd1 = sc.textFile(args(0)) // 2. 解析每行的json数据成为集合 val rdd2: RDD[(String, java.util.List[String])] = rdd1.map(line => { val arr: Array[String] = line.split("\t") // 商家id val busid: String = arr(0) // json val json: String = arr(1) val list: java.util.List[String] = TagUtil.extractTag(json) Tuple2[String, java.util.List[String]](busid, list) }) // 3. 过滤空集合 (85766086,[干净卫生, 服务热情, 价格实惠, 味道赞]) val rdd3: RDD[(String, util.List[String])] = rdd2.filter((t: Tuple2[String, java.util.List[String]]) => { !t._2.isEmpty }) // 4. 将值压扁 (78477325,味道赞) val rdd4: RDD[(String, String)] = rdd3.flatMapValues((list: java.util.List[String]) => { // 导入隐式转换 import scala.collection.JavaConversions._ list }) // 5. 滤除数字的tag (78477325,菜品不错) val rdd5 = rdd4.filter((t: Tuple2[String, String]) => { try { Integer.parseInt(t._2) false } catch { case _ => true } }) // 6. 标1成对 ((70611801,环境优雅),1) val rdd6: RDD[Tuple2[Tuple2[String, String], Int]] = rdd5.map((t: Tuple2[String, String]) => { Tuple2[Tuple2[String, String], Int](t, 1) }) // 7. 聚合 ((78477325,味道赞),8) val rdd7: RDD[Tuple2[Tuple2[String, String], Int]] = rdd6.reduceByKey((a: Int, b: Int) => { a + b }) // 8. 重组 (83073343,List((性价比高,8))) val rdd8: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd7.map((t: Tuple2[Tuple2[String, String], Int]) => { Tuple2[String, List[Tuple2[String, Int]]](t._1._1, Tuple2[String, Int](t._1._2, t._2) :: Nil) }) // 9. reduceByKey (71039150,List((环境优雅,1), (价格实惠,1), (朋友聚会,1), (团建,1), (体验好,1))) val rdd9: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd8.reduceByKey((a: List[Tuple2[String, Int]], b: List[Tuple2[String, Int]]) => { a ::: b }) // 10. 分组内排序 (88496862,List((回头客,5), (服务热情,4), (味道赞,4), (分量足,3), (性价比高,2))) val rdd10: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd9.mapValues((list: List[Tuple2[String, Int]]) => { val list2: List[Tuple2[String, Int]] = list.sortBy((t: Tuple2[String, Int]) => { -t._2 }) list2.take(5) }) // 11. 商家间排序 (75144086,List((服务热情,38), (效果赞,30), (无办卡,22), (环境优雅,22), (性价比高,21))) val rdd11: RDD[Tuple2[String, List[Tuple2[String, Int]]]] = rdd10.sortBy((t: Tuple2[String, List[Tuple2[String, Int]]]) => { t._2(0)._2 }, false) rdd11.collect().foreach(println) } }
1.2 导出 Jar 包,并添加依赖的第三方类库
【打开 Project Structure】
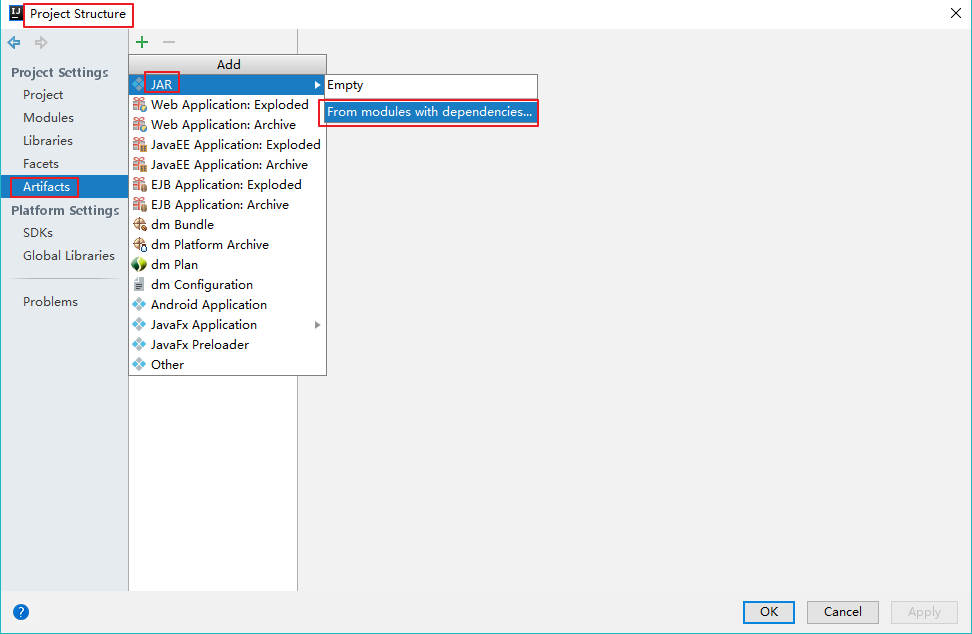
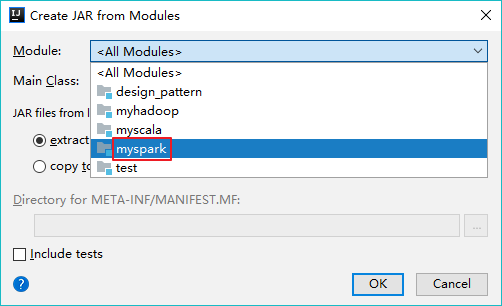
【添加模块】
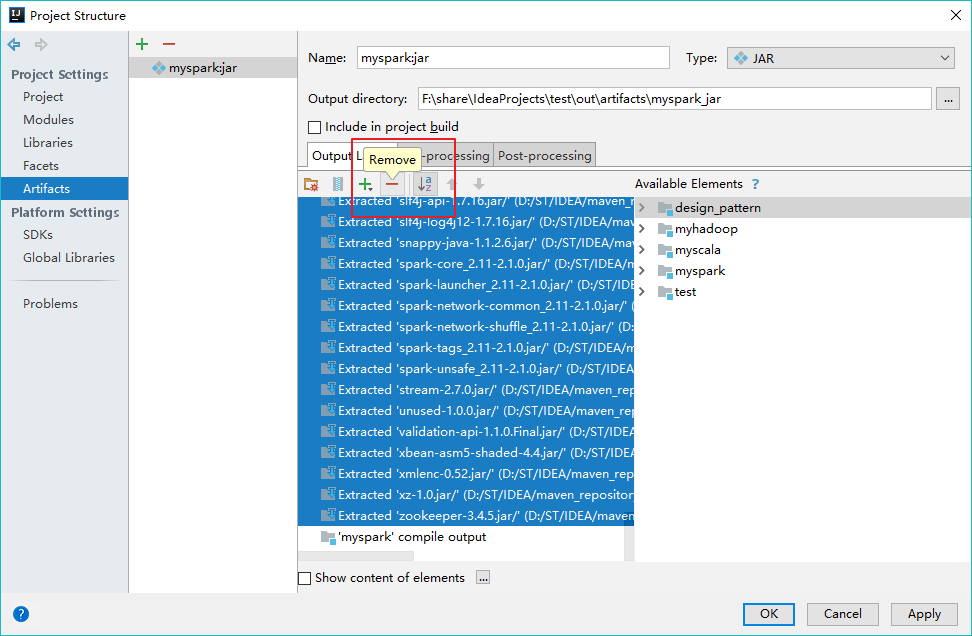
【移除第三方类库】
【添加第三方类库 fastjson】
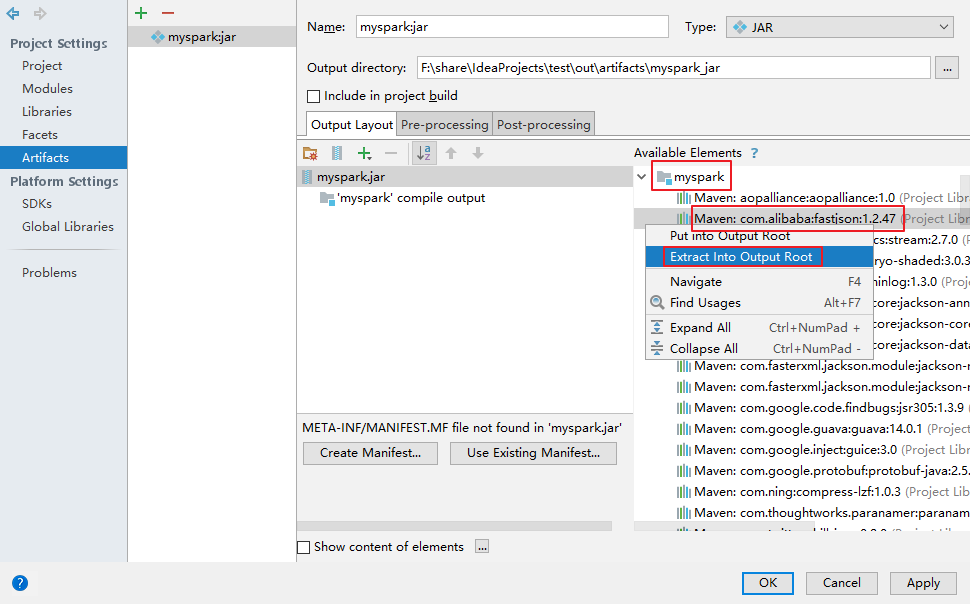
【导入完成】
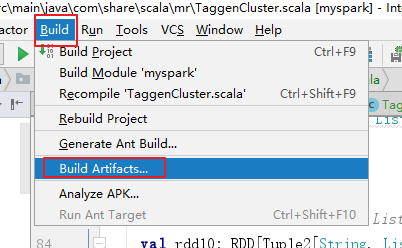
【构建 Jar 包】
【得到 Jar 包】
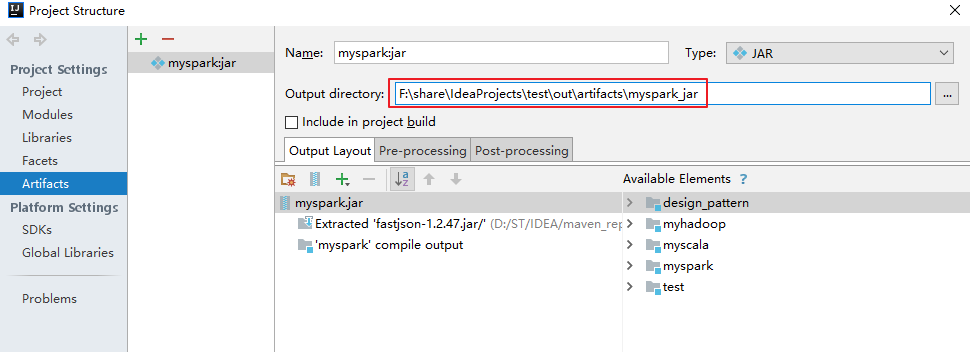

2. 运行程序
2.0 将 Jar 包传输到服务器
通过 Xftp 将 myspark.jar 传到服务器,过程略。
2.1 上传文件到 HDFS 中
hdfs dfs -put temptags.txt /user/centos
2.2 使用 spark-submit 提交应用(Scala)
spark-submit --class com.share.scala.mr.TaggenCluster --master spark://s101:7077 myspark.jar /user/centos/temptags.txt
2.3 使用 spark-submit 提交应用(Java)
spark-submit --class com.share.java.mr.TaggenCluster --master spark://s101:7077 myspark.jar /user/centos/temptags.txt
且将新火试新茶,诗酒趁年华。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号