Hadoop 完全分布式安装
相关链接
0. 说明
准备 5 台服务器
分别按照 Hadoop 伪分布式安装 那样配置
集群规划如下
| 服务器主机名 | ip | 节点配置 |
| s101 | 192.168.23.101 | NameNode / ResourceManager / SecondaryNameNode |
| s102 | 192.168.23.102 | DataNode / NodeManager |
| s103 | 192.168.23.103 | DataNode / NodeManager |
| s104 | 192.168.23.104 | DataNode / NodeManager |
| s105 | 192.168.23.105 | 待定 |
1. 前期准备
1.0 准备 5 台服务器
略
1.1 更改主机名
分别为 5 台服务器更名
# 编辑主机名配置文件 sudo vi /etc/hostname # 设置主机名,将 localhost.localdomain 改为 s101 s101 # 重启服务器 init 6
1.2 配置静态 ip
1.3 安装 JDK
1.4 安装 Hadoop
只需要先配置 [ s101 ]
在伪分布式的基础上进行以下操作
在 /soft/hadoop/etc 目录下
cp -r pseudo full // 创建 full 目录
ln -s full hadoop // 创建hadoop符号链接指向full
ln -sfT /soft/hadoop/etc/full /soft/hadoop/etc/hadoop
// 强制修改hadoop符号链接,指向full,适用于已存在 hadoop 符号链接的情况
1.5 修改hosts文件
为每个服务器都作如下配置
# 修改主机名和ip的映射 sudo vi /etc/hosts # 配置如下 192.168.23.101 s101 192.168.23.102 s102 192.168.23.103 s103 192.168.23.104 s104 192.168.23.105 s105
2. 修改配置文件
2.1 配置文件 [ core-site.xml ]
<configuration> <!-- value标签需要写本机ip --> <property> <name>fs.defaultFS</name> <value>hdfs://s101</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/centos/hadoop</value> </property> </configuration>
2.2 配置文件 [ hdfs-site.xml ]
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
2.3 配置文件 [ mapred-site.xml ]
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
2.4 配置文件 [ yarn-site.xml ]
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>s101</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
2.5 配置文件 [ hadoop-env.sh ]
# 第25行修改如下
export JAVA_HOME=/soft/jdk
2.6 修改 [ slaves ] 文件
# 将 localhost 改为
s102
s103
s104
3. 同步配置文件
3.1 配置 SSH 免密登陆
在 s101 生成公私密钥对
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

分别将公钥拷贝到其他节点
ssh-copy-id centos@s101
ssh-copy-id centos@s102
ssh-copy-id centos@s103
ssh-copy-id centos@s104
ssh-copy-id centos@s105
3.2 同步配置文件( 若其他节点已配置过 Hadoop )
将其他节点的 /soft/hadoop/etc 删掉
ssh s102 rm -rf /soft/hadoop/etc ssh s103 rm -rf /soft/hadoop/etc ssh s104 rm -rf /soft/hadoop/etc ssh s105 rm -rf /soft/hadoop/etc
将本机的 /soft/hadoop/etc 分发到其他节点
scp -r /soft/hadoop/etc centos@s102:/soft/hadoop/ scp -r /soft/hadoop/etc centos@s103:/soft/hadoop/ scp -r /soft/hadoop/etc centos@s104:/soft/hadoop/ scp -r /soft/hadoop/etc centos@s105:/soft/hadoop/
3.3 同步配置文件( 若其他节点没配置过 Hadoop )
将本机的 /soft 分发到其他节点
scp -r /soft centos@s102:/ scp -r /soft centos@s103:/ scp -r /soft centos@s104:/ scp -r /soft centos@s105:/
4. 启动 Hadoop
4.1 格式化 Hadoop 文件系统
hdfs namenode -format
4.2 启动 Hadoop
start-all.sh
4.3 关闭防火墙
参照 Linux 防火墙配置
5. 体验 Hadoop 完全分布式
5.1 打开 Web 界面
192.168.23.101:50070

5.2 将 hadoop.txt 上传到 HDFS
hdfs dfs -put hadoop.txt /
5.3 使用 Hadoop 自带的 demo 进行词频统计
hadoop jar /soft/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /hadoop.txt /out
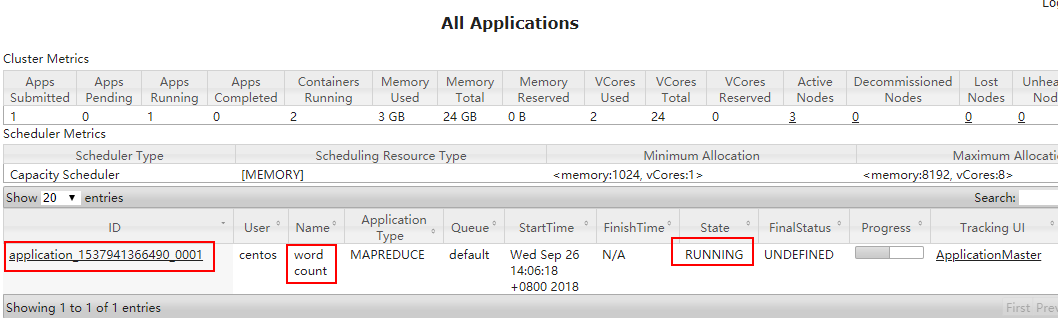
5.4 通过 Web 界面查看 Hadoop 运行状态
http://192.168.23.101:8088

 浙公网安备 33010602011771号
浙公网安备 33010602011771号