[SequenceFile_1] Hadoop 序列文件
1. 关于 SequenceFile
对于日志文件来说,纯文本不适合记录二进制类型数据,通过 SequenceFile 为二进制键值对提供了持久的数据结构,将其作为日志文件的存储格式时,可自定义键(LongWritable)和值(Writeable的实现类)的类型。
多个小文件在进行计算时需要开启很多进程,所以采用容器文件 SequenceFile 按固定大小将多个小文件包装起来,使存储和处理更高效。
2. SequenceFile 说明
【SequenceFile 序列文件】
是由序列化 K-V 对组成,而 K 和 V 即 Hadoop 的 Writable 格式
【为什么使用序列文件】
1、纯文本文件(日志文件)占用了磁盘空间较大
2、将日志文件通过序列文件进行包装,可以获得更好的性能(处理速度和磁盘空间的压缩)
3. SequenceFile 特性
1、扁平化文件,包括二进制的 K-V(将多行纵向的日志文件变成纵向的文件)
2、可读、可写、可排序
3、有三种压缩方式来压缩 K-V 对
1)不压缩
2)记录压缩:只压缩 value
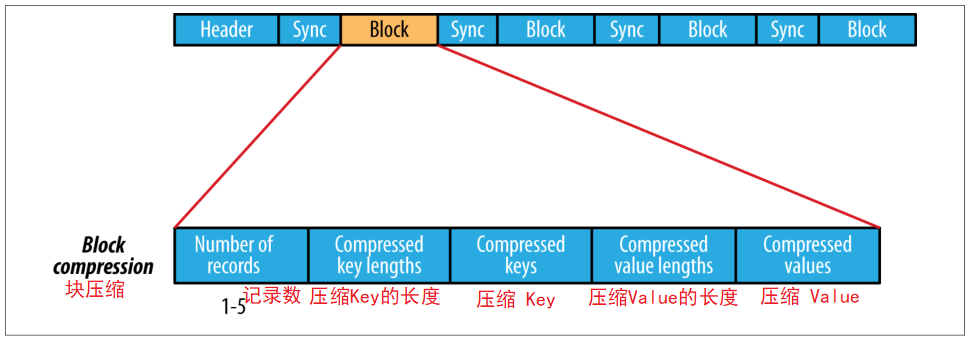
3)块压缩:将多组 K-V 聚集成一个 "block" 然后进行压缩
4、seqFile 格式
1)SEQ 三字节的头 + 数字(如6)作为版本号
2)Key 的完整类名
3)Value的完整类名
4)Boolean 值,指定了 seqFile 是否采用压缩
5)Boolean 值,指定了 seqFile 是否采用块压缩
6)压缩编解码器类
7)metadata: 源数据
8)sync: 同步点
4. SequenceFile 的基本操作
内容如下:
测试序列文件的读写操作 && 测试序列文件的排序操作 && 测试序列文件的合并操作 && 测试序列文件的压缩方式 && 测试将日志文件转换成序列文件
详情链接:
5. SequenceFile 的特性
【Write】
写
【Read】
读
//seek => 将读取指针手动移动,如果指针不在文件头,则会报错
//getPosition => 得到当前指针位置
//sync => 获取下一个同步点位置
【Sort】
//sort => 对sequenceFile进行排序
//merge => 合并+排序
【SequenceFile 压缩说明】
SequenceFile 压缩分为不压缩、记录压缩(默认)、块压缩
记录压缩只压缩值,详情如下:
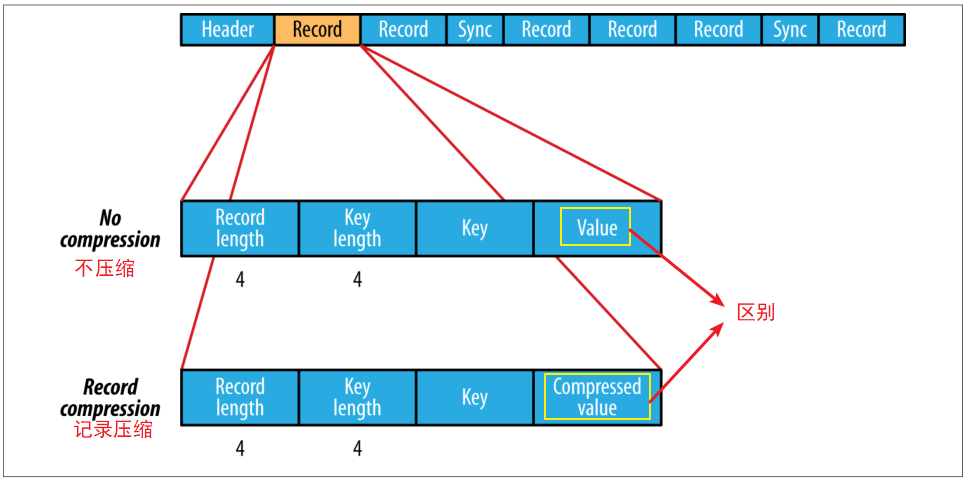
块压缩:将多组 K-V 聚集成一个 "block" 然后进行压缩
块压缩是指一次性压缩多条记录,利用记录间的相似性进行压缩,压缩效率高,压缩的块大小默认 1MB
在块压缩中,同步点与同步点之间是以块为单位进行存储的,块是多个 K-V 聚集的产物
Windows 下查看压缩后的 seqfile :
hdfs dfs -text file:///D:/seq/random.seq

 浙公网安备 33010602011771号
浙公网安备 33010602011771号