构建Dataframe格式的数据
构建Dataframe格式的数据
数据集中的数据:
intereset-rates.csv

populations.csv
# Load the data into Python lists
with open('../data/countries/interest-rates.csv', 'r') as f:
int_rates_col_names = next(f).strip().split(';')
int_rates = [line.split(';') for line in f.read().splitlines()]
with open('../data/countries/populations.csv', 'r') as f:
populations_col_names = next(f).strip().split(';')
populations = [line.split(';') for line in f.read().splitlines()]
import pandas as pd
df_int_rates= pd.DataFrame(int_rates, columns=int_rates_col_names)
df_populations=pd.DataFrame(populations, columns=populations_col_names)
pd.options.diaplay.max_rows=10000
#更改数据的类型
df_int_rates['']=df_int_rates[''].astype(float, copy=False)
df_int_rates['']=pd.to_datetime(df_int_rates[''])
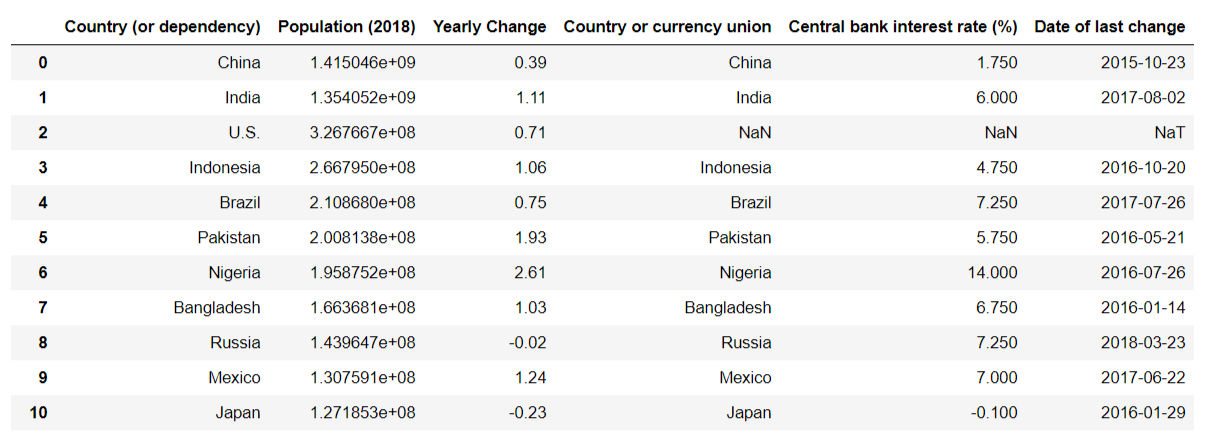
#合并两个DataFrame数据集
df_merge=pd.merge(
df_populations,
df_int_rates,
#按照两个表中的哪两列进行合并
left_on='Country(or dependency)'
right_on='Country or currency union',
#连接的方式,类似于数据库
how='outer'
)
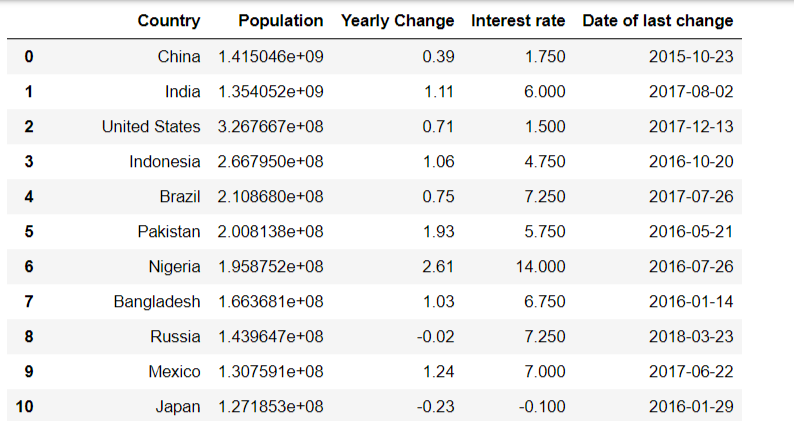
#更改数据集中某一个位置的值
#比如讲U.S.更改为United States
col='Country(or dependency)'
#对于下一句代码的理解:判断col这一列所有元素是否等于'U.S.',等于就是true,否则是false, 返回的是行号和真假值
mask= df.populations[col]=='U.S.'
df_populations.loc[mask, col]='United States'
#更改列的名字
del df_merge['Country or currency union']
name_map = {'Country (or dependency)': 'Country',
'Population (2018)': 'Population',
'Central bank interest rate (%)': 'Interest rate'}
df_merge=df_merge.rename(columns=name_map)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号