

(github:https://github.com/suferyang/KNN/tree/master/KNN)
识别手写的数字0-9,其中图片像素大小为32*32,源码中将像素值用文本格式存储了。
例如:
源代码中目录trainingDigits中包含2000个例子,testDigits中包含大约900个例子,两组数据没有覆盖。
首先我们要讲32*32的二进制图像矩阵转换成1*1024的向量。首先编写一段函数img2vector,打开给定的文件,循环读出文件的前32行,并将每行的头32个字符值存储在数组中。
# 测试0-1图像识别实现代码 def img2vector(filename): returnVec = np.zeros((1,1024)) fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVec[0,32*i+j]=int(lineStr[j]) return returnVec #testVector = img2vector('testDigits/0_13.txt') #print (testVector[0,0:31])
然后编写handwritingClassTest()函数用来测试分类器的代码
def handwritingClassTest(): hwLabels = [] trainingFileList = os.listdir('trainingDigits') m = len(trainingFileList) trainingMat = np.zeros((m,1024)) for i in range(m): filename = trainingFileList[i] fileStr = filename.split('.')[0] classNum = int(fileStr.split('_')[0]) hwLabels.append(classNum) trainingMat[i,:] = img2vector('trainingDigits\%s'%(filename)) testFileList = os.listdir('testDigits') errorCount = 0.0 mTest = len(testFileList) for i in range(mTest): filenames = testFileList[i] fileStr = filenames.split('.')[0] TestNum = int(fileStr.split('_')[0]) testVector = img2vector('testDigits\%s'%(filenames)) classiferResult = classify0(testVector,trainingMat,hwLabels,3) print ("the true num is %d,the classifer num is %d"%(TestNum,classiferResult)) if(classiferResult !=TestNum): errorCount +=1.0 print ("\n the total number of errors is :%d"%(errorCount)) print ("\nthe total error rate is:%f"%(errorCount/float(mTest)))
执行handwritingClassTest()得到运行的结果:
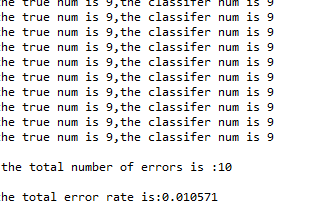
错误率大概为1.05%(其中分类算法,文件读取函数已在上一节中实现了)
