

KNN应用例子:使用K-近邻算法改进约会网站的配对效果。
(github:https://github.com/suferyang/KNN/tree/master/KNN)
数据集训练样本中包括三个特征:飞行里程,每周消费冰淇淋公升数,玩游戏所耗时间百分比
数据集中包含标签数字1,2,3分别代表喜欢的程度 'not at all', 'in small doses','in large dases'
背景:一个女生想找对象,她根据一个男生的三个特征值会知道自己对这个男生的喜欢程度。所以她经过一段时间收集数据,得到了自己对于拥有不同特征值的男生的喜欢程度。
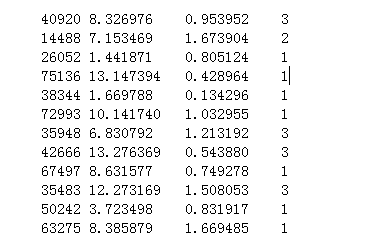
有了她收集的这一千条数据,等下次她再得到一个男生的特点时(特征值),她就会知道自己对这个男生是否有好感了。
第一步:准备数据,从文本文件中解析数据
文件名为datingTestSet2.txt的文件中每一行包括四个数值,1-3表示的是特征值,第4个是标签
#读取文件内容 def file2matrix(filename): fr = open(filename) array0Lines=fr.readlines() #读取全部文件内容,每一行是一个元素 numberoflines = len(array0Lines) #计算多少行 returnMat = np.zeros((numberoflines,3)) #存储特征 classLabelVector=[] #存储类型 index = 0 for line in array0Lines: line = line.strip() #去掉行首行尾删除空白符(包括'\n', '\r', '\t', ' ') listFromLine = line.split('\t') #将整行数据分割成一个元素列表 returnMat[index,0:3]=listFromLine[0:3]#将前三个数据赋值过去 classLabelVector.append(int(listFromLine[-1]))#将标签数据加入进去 index +=1 return returnMat,classLabelVector
可以用#datingDataMat,datingLabels = KNN.file2matrix('datingTestSet2.txt')
第二部:归一化处理
比如对于两组数据(20000,0,1.1)和(32000,67,0.1)计算之间的距离:
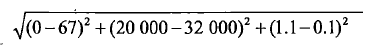
我们就会发现上面数字差值最大的属性对于计算结果的影响最大,也就是说,飞行里程对于计算结果的影响远大于其他两个特征。而我们可能认为这三个特征是同等重要的。
所以处理这种特征值是我们通常采用的方法是将数值归一化,将取值范围处理为0到1或者-1到1之间,下面的公式可以将任意取值范围的特征值归化为0-1区间内的值:
newValue = (oldValue-min)/(max-min)
其中min和max是数据集中的最小特征值
和最大特征值。我们通过autoNorm()函数将每个特征进行归一化处理。
#归一化处理 def autoNorm(dataSet): minVals = dataSet.min(0)#参数0表示每列最小值,参数1表示每行最小值 maxVals = dataSet.max(0) #参上 ranges = maxVals - minVals normDataSet = np.zeros(np.shape(dataSet)) m = dataSet.shape[0] normDataSet = dataSet - np.tile(minVals,(m,1)) normDataSet = normDataSet/np.tile(ranges,1) return normDataSet,ranges,minVals
现在KNN算法, 文件处理,数据归一化函数都有了,我们写一个测试函数试试。
#测试函数 def DataClassTest(): Ratio = 0.1; datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')#读取数据 normMat,ranges,minVals = autoNorm(datingDataMat)#数据归一化 m = datingDataMat.shape[0] numTestVecs = int(m*Ratio)#m*Ratio条数据用于测试数据 errorCount = 0.0 for i in range(numTestVecs): classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) print ("the classifier came back with:%d,the real label is :%d"%(classifierResult,datingLabels[i])) if (classifierResult !=datingLabels[i]): errorCount +=1.0; print ("the total error rate is :%f" %(errorCount/float(numTestVecs)))
我们可以设计一个交互式的函数,这样输入三个特征值,程序就会给出她对对方喜欢的程度。
#交互式测试函数 def classifyPerson(): resultList = ['not at all','in small doses','in large dases'] percentTats = float(input("percentage of time spent playing video games?:")) ffMiles = float(input("frequent flier miles earned per year?:")) iceCream = float(input("liters of ice cream consumed per year?")) datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') normMat,ranges,minVals = autoNorm(datingDataMat) inArr = np.array([ffMiles,percentTats,iceCream]) classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3) print ("you wile probably like this person:",resultList[classifierResult - 1])
结果如下:

目前为止我们已经看到了再数据上构建分类器了。
