hadoop集群搭建
准备工作
先说明我用的是centos7,
并且准备了四台虚拟机 ip分别是
192.168.36.140
192.168.36.141
192.168.36.142
192.168.36.143
一、java环境安装
1.下载jdk
去jdk下载地址下载或者在服务器中用命令下载
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" https://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-linux-x64.tar.gz
注意,以上jdk-8u191-linux-x64.tar.gz的地址是会变的,所以下载地址需要替换成自己的。
2.安装
创建目录
cd /usr/local/ mkdir java cd java
接着把安装包上传到java文件夹中,解压
tar zxvf jdk-8u191-linux-x64.tar.gz
配置环境变量
vi /etc/profile
在文件的末尾输入
export JAVA_HOME=/usr/local/java/jdk1.8.0_191 export PATH=$PATH:$JAVA_HOME/bin
这里注意自己的是不是jdk1.8.0_191
使环境变量在当前bash中生效
source /etc/profile
java环境配置完毕,注意每台主机都要配置
二、hadopp下载和配置
1.下载hadoop
hadoop下载地址选择版本,这里我用的是3.1.1的
2.配置免密登录
因为启动hadoop集群我们通常是这样启动的,在主节点服务器上启动脚本,脚本里面的代码帮助我们启动我们事先配置好的从节点,这里我们如果不配置免密登录的话,早期的版本会需要自己手动输入每一台从节点主机的密码,至于这个3.1.1的版本,我发现直接报错了。(这里我也没确定是hadoop版本原因还是centos版本原因)
我选择主节点在192.168.36.140这台主机上,所以我需要在这台主机上启动
配置流程如下
在192.168.36.140这台主机上运行以下命令
ssh-keygen ssh-copy-id 192.168.36.140 ssh-copy-id 192.168.36.141 ssh-copy-id 192.168.36.142 ssh-copy-id 192.168.36.14
ssh-keygen命令的提示全部默认回车就可以了
3.配置环境
groupadd hadoop
useradd hadoop -g hadoop
此时 /home 文件下就会多出一个hadoop的文件夹,切换文件夹
cd /home/hadoop
把之前下载的hadoop安装包上传到该文件夹下,解压
同时创建几个文件夹,后面有用
mkdir /home/hadoop/datas mkdir /home/hadoop/datas/name mkdir /home/hadoop/datas/data
接着配置hadoop的环境变量
参考 1.2java环境配置
末尾添加如下代码
export HADOOP_HOME=/home/hadoop/hadoop-3.1.1 export PATH=$PATH:$HADOOP_HOME/bin

4.修改配置
切换到配置文件的文件夹下
cd /home/hadoop/hadoop-3.1.1/etc/hadoop
需要修改的文件有五个、hadoop-env.sh core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml
① 首先修改hadoop-env.sh
添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_191 export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root"
在低版本中不需要配置这五个user,但3.1.1版本中不配置的话会提示这些user未定义
② 修改 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.36.140:9000</value>
</property>
</configuration>
③ 修改 hdfs-site.xml
<configuration> <!-- Configurations for NameNode: --> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/datas/name</value> <description>namenode产生的元数据信息保存目录</description> </property> <property> <name>dfs.blocksize</name> <value>268435456</value> <description>文件分块大小,决定map的数量</description> </property> <property> <name>dfs.namenode.handler.count </name> <value>100</value> </property> <!-- Configurations for DataNode: --> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/datas/data/</value> </property> <property> <name>dfs.replication</name> <value>3</value> <description>副本数量</description> </property> <property> <name>dfs.secondary.http.address</name> <value>192.168.36.141:50090</value> <description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description> </property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
</configuration>
标红的地方需要注意,因为我用的是ip,3.1.1版本默认拒绝无法解析的主机名,所以如果要使用ip配置,这里务必改成false,不过正式情况下还是建议使用主机名来配置
④修改 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.36.143</value>
<description>yarn resourcemanager的主机</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description>
</property>
</configuration>
⑤修改 mapred-site.xml
<configuration>
<!-- Configurations for MapReduce Applications: -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改完毕,最后确保每一台主机都如上配置,以上配置每台节点一模一样
修改192.168.36.140主节点文件夹下workers ,让主节点知道去哪台节点上启动从节点,这里如果需要把主节点也当成datanode的话,可以把主节点ip也加进去

5.格式化目录
192.168.36.140主节点上执行
hadoop namenode -format
最后记得关闭所有主机的防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
6 启动
在hadoop-3.1.1目录下执行命令
sbin/start-all.sh
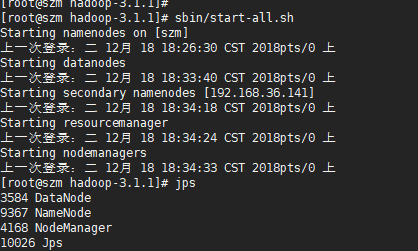
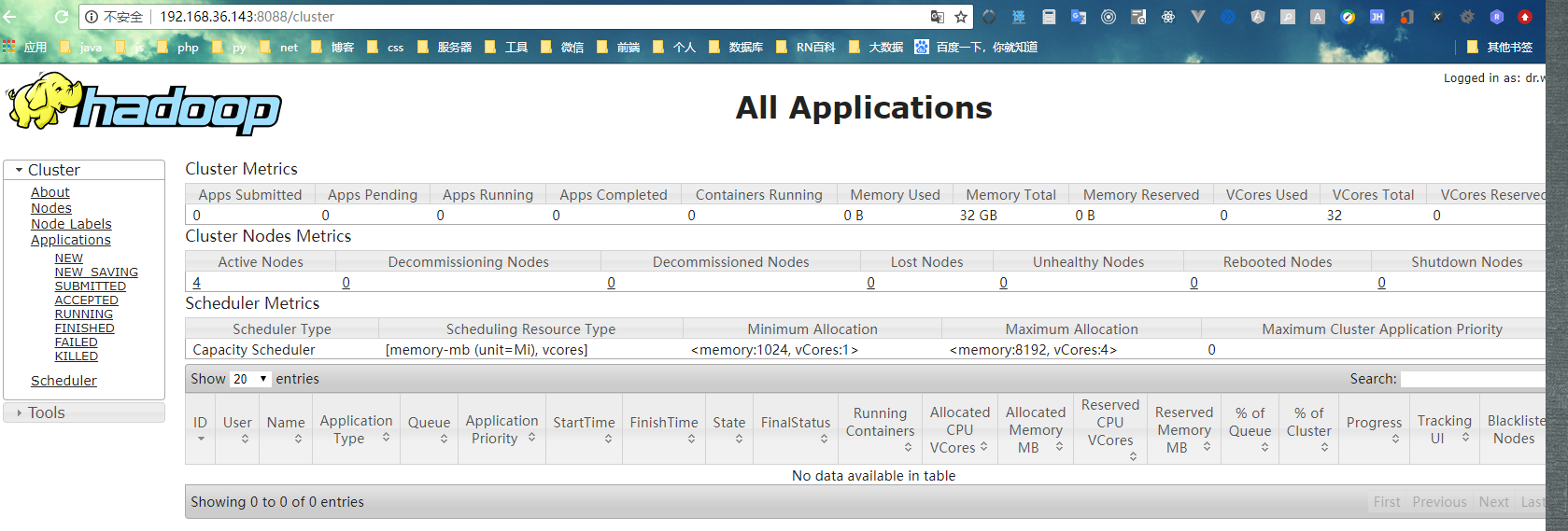
三、云服务器上搭建
如果选择使用云服务器玩hadoop集群的话,操作基本上是一样的,但有些地方需要注意了,一个服务器,会给你提供两个ip 外网类似 21.125.26.124(随便写的,以下都用这个举例公网ip),内网类似 172.0.0.16
这里值得注意的是有些需要配置ip或主机的地方,你可能经常在log中发现一大堆 port 9000或者几几几 in used 的错误信息,这时候你的网络肯定是都用公网配置的 21.125.26.124这个ip,当然如果你都使用内网172.0.0.16配置的话肯定也不对,外网访问不到主节点,所以需要这样配置。
例如,配置主节点,这时候core-site.xml的配置文件中namenode的地址是本机,所以在这台服务器上需要配置成内网172.0.0.16这个ip,而在配置从节点的时候,对于从节点来说主节点是在另外一台服务器上,这里就需要配置成外网 21.125.26.124。其他secondarynamenode 和resourcemanager配置都以此类推。
