hbase入门
1 Hbase特点
容量大:Hbase单表可以有百亿行、百万列,数据矩阵横向和纵向两个纬度所支持的数据量级都非常具有弹性。
面向列 :Hbase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。
多版本: Hbasel每一个列的数据存储有多个 Version
稀疏性:为空的列并不占用存储空间,表可以设计的非常稀疏
扩展性:底层依赖于HDFS
高可靠性:WAL机制保证了数据写入时不会因集群异常而导致写入数据丟失: Replication机制保证了在集群出现严重的问题时数据不会发生丢失或损坏。而且 Hbase底层使用DFS HDFS>本身也有备份
高性能:底层的LSM数结构和 Rowkey有序排列等架构上的独特设计,使得 Basel具有非常高的写入性能。 region切分、主键索引和媛存机制使得 Hbase在海量数据下具备一定的随机读取性能,该性能针对 Rowkey的查询能够到达亳秒级别。
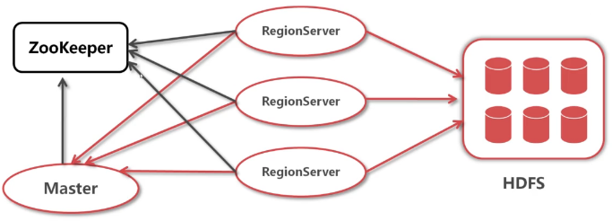
2 Hbase架构体系
3 Hbase表结构模型并举例说明
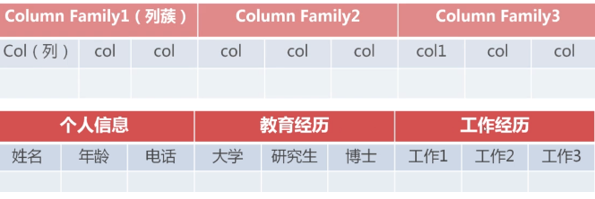
一个列簇表示这行数据的一个类别
4 Hbase数据模型及举例

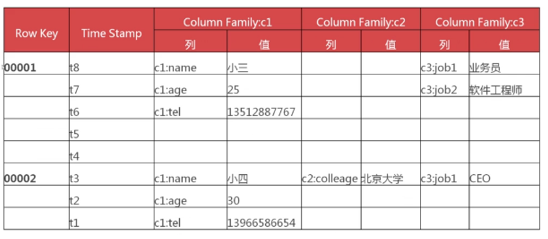
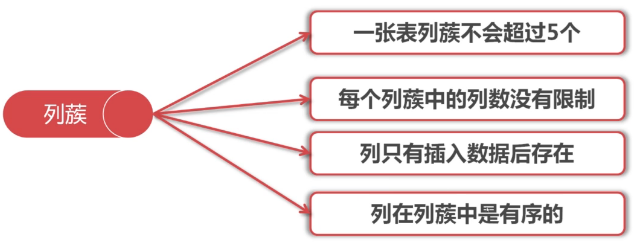
5 列簇
6 Hbase region

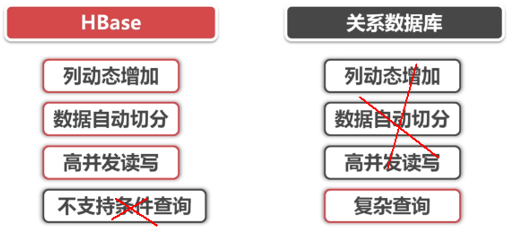
7 Hbase与关系型数据库对比
8 Hbase常用命令和演示
安装好hbase的相关环境后
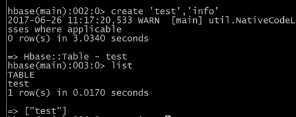
$:hbase shell
>create ‘test’,info //test表民,info为列簇
>put ‘test’,’0001’,’info:username’,’henry’ //插入(或更新)数据,test插入的表名,0001数据的rowkey,在rowkey为0001的数据上添加info列簇username为henry
>scan ‘test’ //查看表test的数据信息


>describe ‘test’查看test表结构

>disable ‘test’ //禁用后才可drop:

>is_enable ‘test’ //查看表状态

>drop ‘test’ //删除表


List 可以看到只有一个表


Get取出某一列的数据