


Scala——的并行集合
当出现Kafka单个分区数据量很大,但每个分区的数据量很平均的情况时,我们往往采用下面两种方案增加并行度:
l 增加Kafka分区数量
l 对拉取过来的数据执行repartition
但是针对这种情况,前者的改动直接影响所有使用消费队列的模型性能,后者则存在一个shuffle的性能消耗。有没有既不会发生shuffle,又能成倍提升性能的方法呢?
/*
推荐使用Scala的并行集合:
在上述场景中存在的情况是,单核数据量很大,但是又由于分区数量限制导致多核无法分配到数据。因此如果使用foreachPartition算子,就可以获取到每个分区的数据集,对这些数据集使用多线程并行执行。
*/
//具体代码如下:
rdd.foreachPartition(datas=>{
//使用一个集合创建对应的并行集合
val seqPar = datas.toSeq.par
//为并行集合设置线程池,默认的参数是CPU的核数
seqPar.tasksupport = new ForkJoinTaskSupport(new ForkJoinPool())
//执行遍历逻辑,自动实现多线程并行
seqPar.foreach{...}
})
//经本地测试,该方法有效。但没有测试复杂的逻辑,如:多个遍历算子、Kafka场景等
如果Spark会优先为每个executor拉取数据,就可以通过设置executor num=Kafka分区数,然后为每个executor设置多个cpu core的方式实现成倍的处理速度。
经实验,Spark在拉取Kafka数据时,不管Cpu核数多少,会优先为每个executor分配一份Kafka分区,只有当总executor数量<Kafka分区时,才会分配多份数据到同一个节点上。
以下是我使用10个节点,每个节点分配4个线程拉取一个分区数量为10的Kafka时,Task的分布情况:

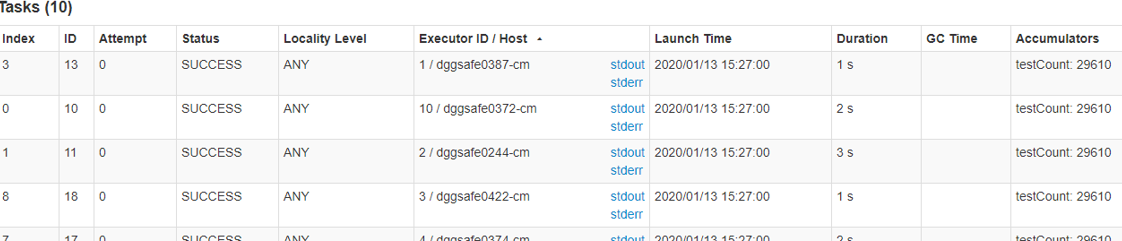
可以看到,数据被很好的分散到了十个节点上。并且在这个测试模型中,我使用了并行集合执行累加器操作。可以看到,并行集合并没有造成数据丢失,而是正常的执行了计算逻辑。
可惜从少量的数据中看不出并行集合带来的提升。此外,关于该方案是否适用于复杂逻辑和持久稳定运行,还需要后续观察。

