
spark记录
1.1 官网
https://spark.apache.org/docs/2.1.1/sql-programming-guide.html#upgrading-from-spark-sql-16-to-20
1.2 初始化sparkContext
val conf=new SparkConf().setMaster("local") conf.setAppName("app") val sc=new SparkContext(conf)
//local的位置可以用集群的url代替,写成local是因为在本地,只需单机运行无需集群。
1.3 spark的rdd有两种创建方式
(1)读取文件数据
val lines = sc.textFile(“test.txt”)
(2)new集合去分发
val lines = sc.parallelize(List(“pandas”,”I like pandas”))
Rdd的概念:是一个分布式不可变的分布式数据集合,被分为多个分区,每个分区运行在集群不同的节点上。
辅助理解:rdd自定义器在未进行行动操作时rdd更像是通过转化操作构建出来的记录了如何计算数据的指令列表。
1.4 rdd的两种操作类型
1.4.1 转化操作
由一个或多个(union)rdd生成一个新的rdd。例如:map filter等API
转化操作是惰性的,但是我们可以通过强制行动count来测试我们的rdd
常用api:
Map:接收函数对每个rdd元素进行某种操作,从而得到一个新的rdd,存在以对应的变更关系
Fiter:接收一个函数,并将rdd中满足该函数的元素返回作为一个新的rdd,数据量会变少。
FlaMap:对每个元素通过某种函数转化,变更为一对多个元素,形成一个新的rdd
下面四中操作中两个集合之间数据类型必须相同
Distinct:返回一个只包含不同元素的行集合 两个集合之间数据类型必须相同
Union:合并两个rdd 为一个新的rdd,不会去重原样合并
intersection:返回两个rdd的交集元素
subtract:返回只在第一个rdd中有第二个rdd中没有的新的rdd的集合
Cartesian: 笛卡尔积
1.4.2 行动操作
行动操作会对rdd计算出一个结果,并把结果(其他数据类型)返回到驱动程序中(driver)或文件系统(数据库或hdfs)中。
例如:count first等API
行动操作注意:collect在单台机器内存中能够放的下是才能用collect函数。所以大规模数据集要用hdfs的api如saveAsTextFile()..等
常用api:
Reduce: 示例求和val sum = rdd.reduce((x+y) => x+y)
Collect:将rdd中的全部程序返回到驱动中(单台机器)
Top:从rdd中获取最前面的几个元素
Foreach:行动操作每个rdd的元素,进行发送存储等操作。如果这种场景用map就不会达到预期效果。因为rdd可能还未被计算过,所以可能还没有对应的结果集(只有经历了行动操作才会计算)
Count:统计个数
CountByValue:按照值统计每个值得个数 {1,2,3,3} -> {(1,1),(2,1),(3,2)}
Take:从rdd中取出n个元素 按照默认顺序
TakeSameple: 采样,返回随机的几个元素
1.4.3 两种操作的区别
转化操纵都是惰性流程,只有第一个这个rdd遇到行动操作是才会正真计算。rdd每次行动动作是都会重新计算。
1.5 数据持久化
Persist:会把数据以序列化的形式缓存到jvm的对空间中。
例如:
val result = input.map(x=> x*x)
println(result.count())
println(result.coollect().mkString(“,”))
这里有两个行动操作,导致了rdd被重复计算,导致资源消耗和浪费
做如下改动解决上述问题:
val result = input.map(x=> x*x)
Result.persist(StoregeLevel.DISK_ONLY)
println(result.count())
println(result.coollect().mkString(“,”))
1.6 键值对操作
Pair rdd:在spark中对含有键值对的rdd的一种称呼
创建pair rdd:
val pairs= lines.map(x=>(x.split(“ ”)(0),x)) //使用第一个单词作为键创建pair rdd
Api操作示例:
rdd原始数据{(1,2),(3,4),(3,6)}
针对两个pair rdd 的操作:rdd={(1,2),(3,4),(3,6)} other={(3,9)}
subtractByKey:rdd.subtractByKey(other) //{(1,2)} 删掉rdd中与other键相同的元素
join: rdd.join(other) //{(3,(4,9)),(3,(6,9))} 对两个rdd进行内连接
1.7 数据读取与保护
1.7.1 文本文件
读取文本文件
一般默认用sc.textFile(“file:///home/.../readme.md”)
当目标文件比较小时可用sc.wholeTextFiles(“file///…..”)
示例:求取每个文件每行的平均值
val input = sc.wholeTectFile(“file:///home/holden/salesFiles”) val result= input.mapValues{y=> val nums = y.split(“ ”).map(x=>x.toDounble) nums.sum/nums.size.toDouble }
注:也可以用通配符(part-*.txt)
保存文本文件
result.SaveAsTextFile(outputFile)
csv文件读取(无换行),内容有换行时需要整个文件读取
val input= sc.textFile(inputFile) val result=input.map{line=> val reader= new CSVReader(new StringReader(line)); reader.readNext(); }
Hive Sql
处理hive sql/有hive映射的hbase
val hiveContext=new HiveContext(sc); val rows = hiveContext.sql(“select name ….”) val firstRow = rows.first(); println(firstRow.getString(0))//字段0是name字段
处理json
{“user”:{“name”:”holden”,”localtion”:”san francisco”},”text”:”nice day out today”}
val tweets=hiveContext.jsonFile(“tweets.json”) tweets.registerTempTable(“tweets”) val tesults=hiveContext.sql(“select user.name,text from tweets”)
1.8 spark的共享变量累加器与广播变量
累加器:将工作节点中的值聚合到驱动程序的简单语法;
常见用法是在调试时对作业执行过程计数;
示例:统计有多少个空行
val file = sc.textFile(“file.txt“) val blankLines= sc.acumulator(0) val callSigns= file.flatMap(line=>{ If(line==””){ bkankLines +=1 } line.split(“”) }) callSigns.saveAsTextFile(“output.txt”)//使用此行动操作才能看到blankLines的值
广播变量:可以高效的让程序向所有工作节点发送一个较大的只读值(例如只读查询表)。不需要每个task带上一份变量副本,而是变成每个节点的executor才一份副本。可节约资源,提高网略传输速度,从而达到提高模型运行效率。
不适用广播变量的话,每个task都会执行同样的获取数据的方法,从而导致每个task都有这样一个数据的副本导致每个task节点占用的内存空间偏大,如果数据特别大的话网略传输压力也会很大。
建议广播数据大小控制在300M以内
它为spark.broadcast.Broadcast[T]的一个对象,其中存放着类型为T(T必须是可序列化)的值。
示例:
Val signPrefixes= sc.broadcast(loadCallSignTable()) Val countryContactCounts= contactCounts.map{map(sign,count)=>{ Val country = lookupInArray(sign,signPrefixes.value) (country,count) } }
广播标量的值修改后,值改变当前节点的值,其他节点不会改变。
闭包:简单的认为是一个可以访问另一个函数里面局部变量的另外一个而函数。
1.9 分区操作
基于分区的操作可以让我们避免为每个数据元素进行重复的配置,如打开数据库连接或者创建随机数生产器等
安分区执行的api:
mapPartitions()
mappartitionsWithIndex()
foreachPartitions()
1.10 Spark Sql
Spark.sql.codegen:设置为true时,spark sql会把每条查询语句运行时编译为Java 的二进制代码,这样可以提高大型查询性能,但是小规程查询是会变慢。Conf.set(“spark.sql.codegen”,”true”)。首次开启时前几条查询会特别慢,因为spark需要初始化编译器。
Beeline
执行beeline后,如果想在某个队列下的空间执行sql,运行如下命令:
set mapreduce.job.queuename=QueueE;
1.11 Spark streaming
//制定60秒的批处理
val freq = params.getOrElse("freq", "60").toInt
val sparkConf = new SparkConf().setAppName("myTest")
val ssc:StreamingContext = new StreamingContext(sparkConf, Seconds(freq))
//连接到本地7777端口,使用受到的数据创建DStream
val lines=ssc.socketTextStream(“localhost”,7777) val errorLines=lines.filter(_.contains(“error”)) errorLines.print()
ssc.start()//启动计算环境StreamingContext(一个只能启动一次),开始接收数据
ssc.awaitTermination()//等待作业完成,防止应用退出
linux/mac:windows用户用ncat 代替nc
$ spark-submit --class com……我们的模型
$ nc localhost 7777
输入数据 测试
2 基础操作示例
2.1 基础api常用操作
val textFile = sc.textFile("README.md")
textFile.count() // RDD 的数据条数
textFile.first() // RDD 的第一行数据
val linesWithSpark = textFile.filter(line => line.contains("Spark"))//transformation,我们将使用 filter 在这个文件里返回一个包含Spark子数据集的新 RDD
textFile.filter(line => line.contains("Spark")).count() // 有多少行包括 "Spark"
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b)// transformations和actions能被用在更多的复杂计算中,找到一行中最多的单词数量
textFile.map(line => line.split(" ").size).reduce((a, b) => Math.max(a, b))//作用同上
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)//统计每个单词的数量,以key为基础将value进行相加
wordCounts.collect()//将rdd中的全部程序返回到驱动中, reduceByKey是转换操作,reduce是行动操作
linesWithSpark.cache()//缓存热点数据到内存
lineLengths.persist()//persist (或 cache)方法持久化(persist)一个 RDD 到内存中
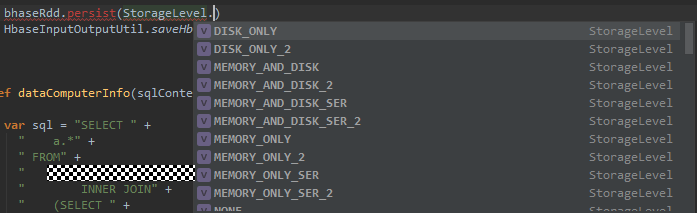
lineLengths.unpersist()//Spark自动的监控每个节点缓存的使用情况,利用最近最少使用原则删除老旧的数据,也可以手动删除用unpersist
rdd创建:
val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val distFile = sc.textFile("data.txt")
Spark Streaming
//创建了一个具有两个执行线程以及1秒批间隔时间(即以秒为单位分割数据流)的本地StreamingContext val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1)) //创建一个DStream,它表示从TCP源(主机位localhost,端口为9999)获取的流式数据。 val lines = ssc.socketTextStream("localhost", 9999) val words = lines.flatMap(_.split(" "))//将DStream中的每行文本都切分为单词 val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _)//类似之前的统计每个单词数量 ssc.start() // Start the computation 真正执行计算,需要调用 ssc.awaitTermination() // 等待处理被终止(手动或者由于任何错误)。 // ssc.stop() 来手动的停止处理
- 一旦一个 context 已经启动,将不会有新的数据流的计算可以被创建或者添加到它。
- 一旦一个 context 已经停止,它不会被重新启动。
- 同一时间内在 JVM 中只有一个 StreamingContext 可以被激活。
- 在 StreamingContext 上的 stop() 同样也停止了 SparkContext。为了只停止 StreamingContext,设置 stop() 的可选参数,名叫 stopSparkContext 为 false。
- 一个 SparkContext 就可以被重用以创建多个 StreamingContexts,只要前一个 StreamingContext 在下一个StreamingContext 被创建之前停止(不停止 SparkContext)。
2.2 DStreams 上的输出操作
有很多api可参考官网
重点foreachRDD 设计模式的使用
通常向外部系统写入数据需要创建连接对象(例如与远程服务器的 TCP 连接),并使用它将数据发送到远程系统。为此,开发人员可能会无意中尝试在Spark driver 中创建连接对象,然后尝试在Spark工作人员中使用它来在RDD中保存记录。例如(在 Scala 中):
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
这是不正确的,因为这需要将连接对象序列化并从 driver 发送到 worker。这种连接对象很少能跨机器转移。此错误可能会显示为序列化错误(连接对象不可序列化),初始化错误(连接对象需要在 worker 初始化)等。正确的解决方案是在 worker 创建连接对象。
但是,这可能会导致另一个常见的错误 - 为每个记录创建一个新的连接。例如:
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
通常,创建连接对象具有时间和资源开销。因此,创建和销毁每个记录的连接对象可能会引起不必要的高开销,并可显着降低系统的总体吞吐量。一个更好的解决方案是使用 rdd.foreachPartition - 创建一个连接对象,并使用该连接在 RDD 分区中发送所有记录。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
这样可以在多个记录上分摊连接创建开销。
最后,可以通过跨多个RDD /批次重用连接对象来进一步优化。可以维护连接对象的静态池,而不是将多个批次的 RDD 推送到外部系统时重新使用,从而进一步减少开销。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// 连接池是一个静态的懒加载的连接集合
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection)
}
}
请注意,池中的连接应根据需要懒惰创建,如果不使用一段时间,则会超时。这实现了最有效地将数据发送到外部系统.
- DStreams 通过输出操作进行延迟执行,就像 RDD 由 RDD 操作懒惰地执行。具体来说,DStream 输出操作中的 RDD 动作强制处理接收到的数据。因此,如果您的应用程序没有任何输出操作,或者具有 dstream.foreachRDD() 等输出操作,而在其中没有任何 RDD 操作,则不会执行任何操作。系统将简单地接收数据并将其丢弃。
- 默认情况下,输出操作是 one-at-a-time 执行的。它们按照它们在应用程序中定义的顺序执行。
2.3 DataFrame 和 SQL 操作
val words: DStream[String] = ... words.foreachRDD { rdd => val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() import spark.implicits._ // 将RDD[String] to DataFrame val wordsDataFrame = rdd.toDF("word") wordsDataFrame.createOrReplaceTempView("words")
// 利用sql 统计每个单词的数据量,打印
val wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word") wordCountsDataFrame.show() }
2.4 DataSet 和 SQL 操作
import org.apache.spark.sql.SparkSession val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("spark.some.config.option", "some-value") .getOrCreate() // For implicit conversions like converting RDDs to DataFrames import spark.implicits._

