

Django当中的数据库查询优化
了解Django框架中进行数据查询优化,需要了解几点:
1.查询集是惰性的,这意味着在你对查询集执行某些操作(例如对其进行迭代)之前,不会发出相应的数据库请求;
2.始终通过指定要返回的值的数量来限制数据库查询的结果;
3.在 Django 中,查询集可以通过迭代、切片、缓存和 python 方法(例如len()等)进行评估count()。确保充分利用它们;
4.Django 查询集被缓存,因此如果你重复使用相同的查询集,将不会发出多个数据库请求,从而最大限度地减少数据库访问;
5.一次检索你需要的所有内容,但请确保你只检索你需要的内容。
Django中的查询优化
数据库索引
# models.py from django.db import models class Sale(models.Model): sold_at = models.DateTimeField( auto_now_add=True, db_index=True, #DB Indexing ) charged_amount = models.PositiveIntegerField()
如果你为此模型运行迁移,Django 将在表 Sales 上创建一个数据库索引,并且它将被锁定直到索引完成。在本地开发设置中,数据量很少,连接很少,这种迁移可能感觉是瞬间的,但是当我们谈论生产环境时,有很多并发连接的大型数据集可能会导致停机,如获取锁和创建数据库索引可能需要很长时间。
数据库缓存
Django 提供了一种缓存机制,可以使用不同的缓存后端,如 Memcached 和 Redis,让你避免多次运行相同的查询。
Memcached 是一个开源的内存系统,可保证在不到一毫秒的时间内提供缓存结果。它易于设置和扩展。另一方面,Redis 是一种开源缓存解决方案,具有与 Memcached 相似的特性。大多数离线应用程序使用以前缓存的数据,这意味着大多数查询永远不会到达数据库。
要在 Django 中使用 Memcache,我们需要定义以下内容:
- BACKEND:定义要使用的缓存后端。
- LOCATION:ip:port 值 where ip 是 Memcached 守护程序的 IP 地址, port 是运行 Memcached 的端口,或者是指向你的 Redis 实例的 URL,使用适当的方案。
要使用 Memcached 启用数据库缓存,请pymemcache使用以下命令使用 pip 进行安装:
pip install pymemcache
然后,你可以settings.py按如下方式配置缓存设置:
CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyMemcacheCache', 'LOCATION': '127.0.0.1:11211', } }
在上面的示例中,Memcached 使用以下 pymemcache 绑定在 localhost (127.0.0.1) 端口 11211 上运行:
同样,要使用 Redis 启用数据库缓存,请使用以下命令使用 pip 安装 Redis:
pip install redis
settings.py然后通过添加以下代码来配置你的缓存设置:
CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.redis.RedisCache', 'LOCATION': 'redis://127.0.0.1:6379', } }
尽可能使用迭代器
Django 中的查询集通常会在评估发生时缓存其结果,对于该查询集的任何进一步操作,它首先检查是否有缓存的结果。但是,当你使用 时iterator(),它不会检查缓存并直接从数据库中读取结果,也不会将结果保存到查询集。
现在,你一定想知道这有什么帮助。考虑一个查询集,它返回大量具有大量内存的对象进行缓存,但只能使用一次,在这种情况下,你应该使用iterator()。
queryset = Product.objects.all().iterator() for each in queryset: do_something(each)
上述中我们使用了iterator(),Django 将保持 SQL 连接打开并读取每条记录,并 do_something() 在读取下一条记录之前调用。
使用持久性数据库连接
Django 为每个请求创建一个新的数据库连接,并在请求完成后关闭它。这种行为是由 引起的CONN_MAX_AGE,它的默认值为 0。但是应该设置多长时间呢?这取决于你网站上的流量;音量越高,维持连接所需的秒数就越多。通常建议从较低的数字开始,例如 60。
你需要将额外的选项包装在 中 OPTIONS,如留档中详细说明:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'dashboard', 'USER': 'root', 'PASSWORD': 'root', 'HOST': '127.0.0.1', 'PORT': '3306', 'OPTIONS': { 'CONN_MAX_AGE': '60', } } }
使用查询表达式
查询表达式定义了可以在更新、创建、过滤、排序、注释或聚合操作中使用的值或计算。Django 中常用的内置查询表达式是 F 表达式。让我们看看它是如何工作的并且很有用。
在 Django Queryset API 中,F()表达式用于直接引用模型字段值。它允许你引用模型字段值并对它们执行数据库操作,而无需从数据库中获取它们并进入 Python 内存。相反,Django 使用该F()对象来生成定义所需数据库活动的 SQL 短语。
例如,假设我们想将所有产品的价格提高 20%,那么代码将如下所示:
from django.db.models import F Product.objects.update(price=F('price') * 1.2)
上述使用了F()查询表达式
使用 select_related() 和 prefetch_related()
Django 通过最小化数据库请求的数量来提供优化查询集select_related()的prefetch_related()参数。
根据官方 Django 文档:
select_related() “遵循”外键关系,在执行查询时选择其他相关对象数据。
prefetch_related() 对每个关系进行单独的查找,并在 Python 中进行“加入”。
select_related()
我们select_related()在要选择的项目是单个对象时使用,这意味着 forward ForeignKey、OneToOne和 backOneToOne字段。
你可以使用select_related()创建单个查询,该查询返回单个实例的所有相关对象,用于一对多和一对一连接。执行查询时,select_related()从外键关系中检索任何额外的相关对象数据。
select_related()通过生成 SQL 连接并在SELECT表达式中包含相关对象的列来工作。因此,select_related()在同一数据库查询中返回相关项目。
虽然select_related()会产生更复杂的查询,但获取的数据会被缓存,因此处理获取的数据不需要任何额外的数据库请求。
语法看起来像这样:
queryset = Tweet.objects.select_related('owner').all()
prefetch_related()
相反,prefetch_related()用于多对多和多对一连接。它生成一个查询,其中包括查询中给出的所有模型和过滤器。
语法看起来像这样:
Book.objects.prefetch_related('author').get(id=1).author.first_name
测试下prefetch_related()和select_related()
select_related():
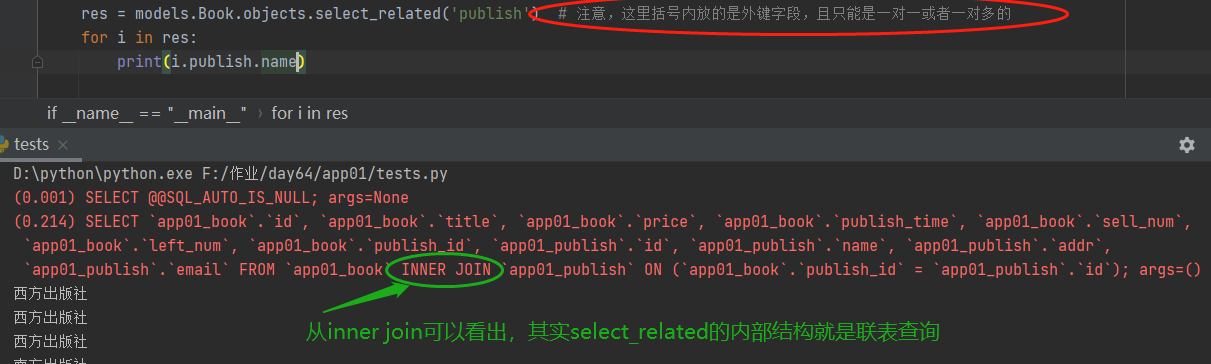
从上面的测试中可以看出,select_related方法的内部其实就是联表查询,而且每循环一次就需要调用一次数据库
prefetch_related():
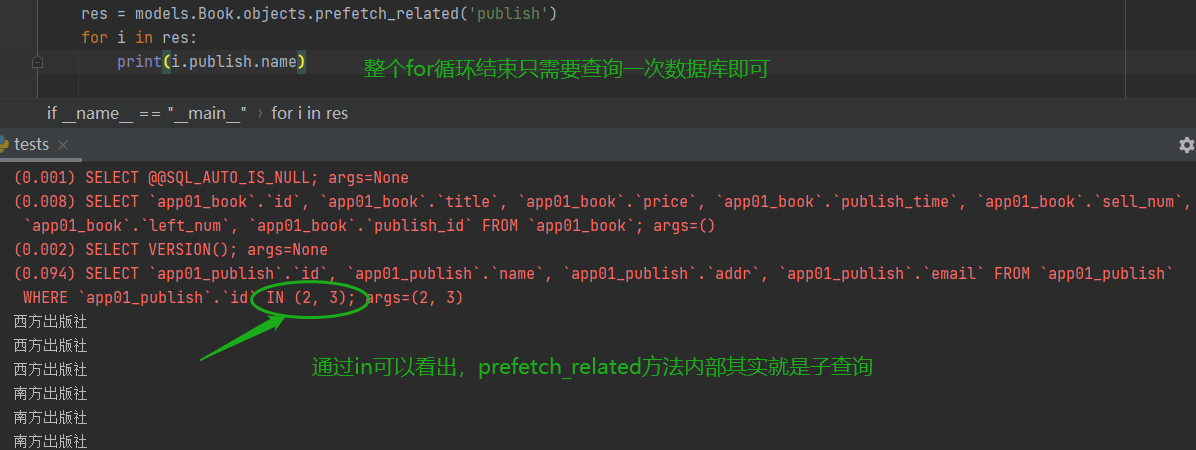
从上面的测试中,可以看出prefetch_related方法的内部其实就是子查询,而且整个循环只需要调用一次数据库即可
因此,prefetch_related()和select_related()的区别:
select_related:方法内部其实就是联表查询
prefetch_related:方法内部其实就是子查询
两者查询优势具体要看情况,如果表数据很多时,联表可能需要花费的时间比子查询花费的时间更多
使用bulk_create()和bulk_update()
bulk_create() 是一种通过一次查询将提供的对象列表创建到数据库中的方法。类似地,bulk_update() 是一种使用一个查询更新提供的模型实例上的给定字段的方法。
例如,如果我们有一个如下所示的帖子模型:
#articles articles = [Post(title="Hello python"), Post(title="Hello django"), Post(title="Hello bulk")] #insert data Post.objects.bulk_create(articles)
如果我们想更新数据,那么我们可以bulk_update()这样使用:
update_queries = [] a = Post.objects.get(id=14) b = Post.objects.get(id=15) c = Post.objects.get(id=16) #set update value a.title="Hello python updated" b.title="Hello django updated" c.title="Hello bulk updated" #append update_queries.extend((a, b, c)) Post.objects.bulk_update(update_queries, ['title'])
参考自:https://www.51cto.com/article/717666.html

