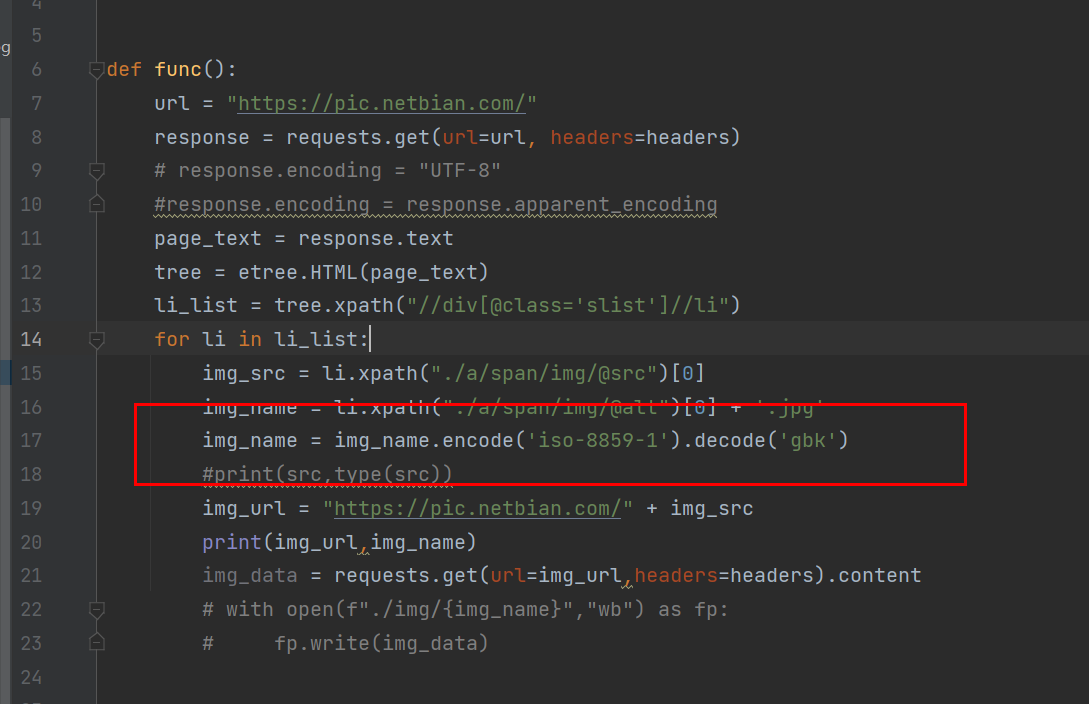
在爬虫过程中出现乱码,那么如何处理?
在爬虫中很容易出现乱码现象,那么具体如何处理呢?以下有几种方式,记录下。
方式一:给响应对象添加encoding
response = request.get(url=url,headers=headers) response.encoding = "utf-8"

或者手动指定网页编码:
# 手动设定响应数据的编码格式 response.encoding = response.apparent_encoding
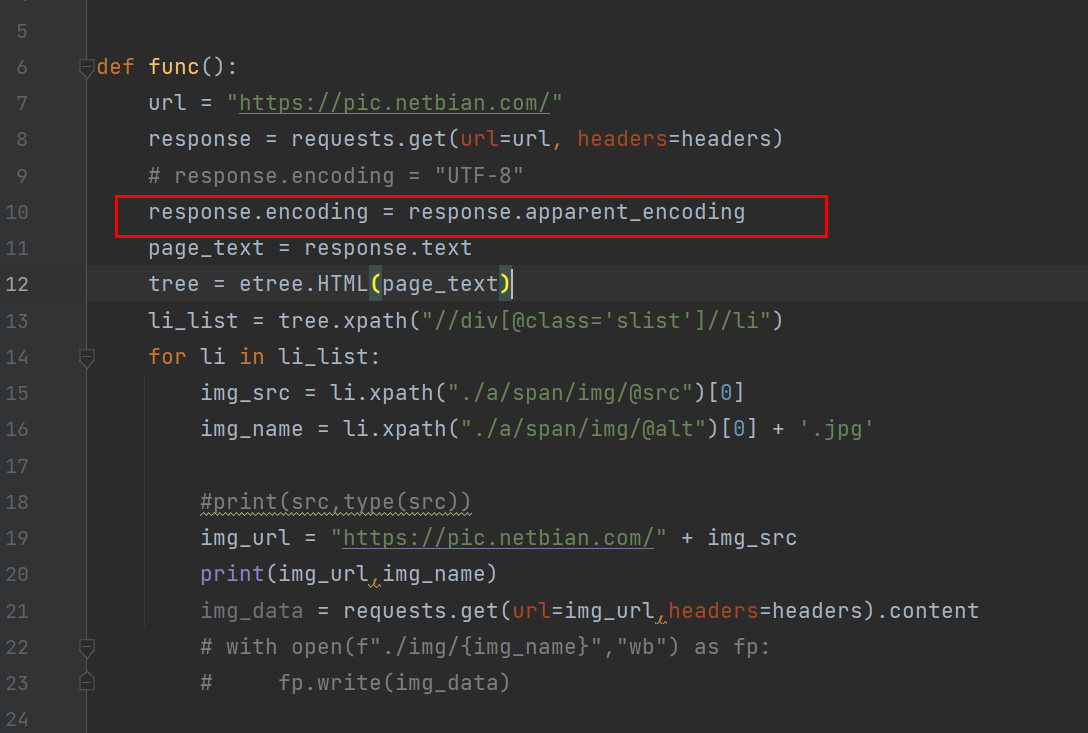
方式二:将requests.get().text改为requests.get().content
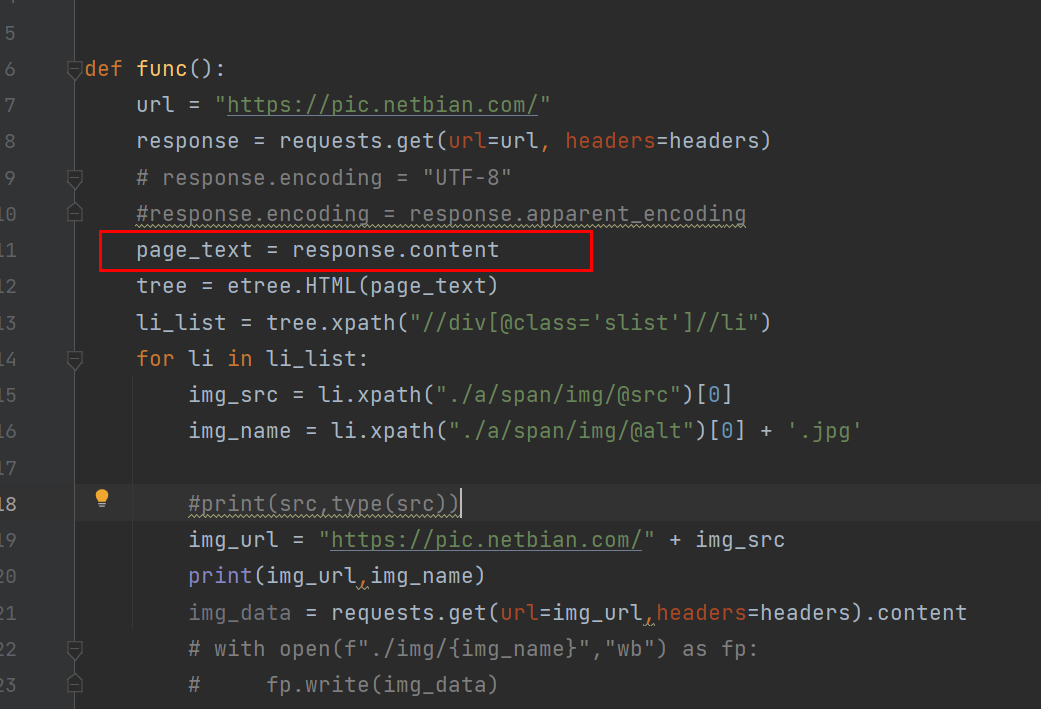
方法三:使用通用的编码方法
img_name.encode('iso-8859-1').decode('gbk')