大数据-2Linux基本命令
Linux基本命令
学习:
- 安装系统
- 简单命令
- 文件系统
- 文本操作
- vi
- 正则表达式
- 文本编辑
- 用户管理
- 权限管理
- 安装软件
- shell编程
查询可执行文件的命令
type
查询命令的位置
[root@MDNode01 ~]# type ifconfig
ifconfig is /sbin/ifconfig
##类似win的path环境变量下面配置了type的命令
file
[root@MDNode01 ~]# file /sbin/ifconfig
/sbin/ifconfig: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.18, stripped
##ELF代表是可执行程序的二进制编码格式
##类似win的exe文件
echo
输出变量
[root@MDNode01 ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
#bin(二进制可执行文件程序)
这样我们的系统中
外部命令:
[root@MDNode01 ~]# type ifconfig
ifconfig is /sbin/ifconfig
#is 某个目录下面的都是外部命令
下载yum
[root@MDNode01 ~]# file /usr/bin/yum
/usr/bin/yum: a /usr/bin/python script text executable
#显示的是 yum是一个文本的python的脚本文件
[root@MDNode01 ~]# vi /usr/bin/yum
###############################################################
#!/usr/bin/python
##指定执行文件的可执行的二进制程序
import sys
try:
import yum
except ImportError:
print >> sys.stderr, """\
There was a problem importing one of the Python modules
required to run yum. The error leading to this problem was:
%s
Please install a package which provides this module, or
verify that the module is installed correctly.
It's possible that the above module doesn't match the
current version of Python, which is:
%s
If you cannot solve this problem yourself, please go to
the yum faq at:
http://yum.baseurl.org/wiki/Faq
""" % (sys.exc_value, sys.version)
sys.exit(1)
sys.path.insert(0, '/usr/share/yum-cli')
try:
import yummain
yummain.user_main(sys.argv[1:], exit_code=True)
except KeyboardInterrupt, e:
print >> sys.stderr, "\n\nExiting on user cancel."
sys.exit(1)
####################################################################
#我们通过type查找到的外部命令可能是一个二进制可执行文件,也有可能是一个脚本文件调用一个
#二进制可执行程序
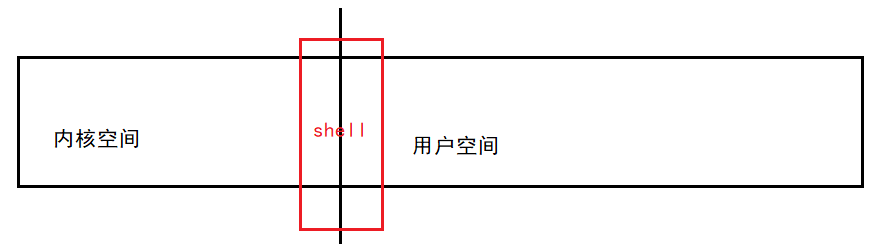
sehll代表的是人机交互的程序
[root@MDNode01 ~]# type cd
cd is a shell builtin
[root@MDNode01 ~]# type echo
echo is a shell builtin
is a shell builtin
代表的是shell内部的命令,可以通过help [命令名]查看文档
root@MDNode01 ~]# help cd
cd: cd [-L|-P] [dir]
Change the shell working directory.
Change the current directory to DIR. The default DIR is the value of the
HOME shell variable.
The variable CDPATH defines the search path for the directory containing
DIR. Alternative directory names in CDPATH are separated by a colon (:).
A null directory name is the same as the current directory. If DIR begins
with a slash (/), then CDPATH is not used.
If the directory is not found, and the shell option `cdable_vars' is set,
the word is assumed to be a variable name. If that variable has a value,
its value is used for DIR.
Options:
-L force symbolic links to be followed
-P use the physical directory structure without following symbolic
links
The default is to follow symbolic links, as if `-L' were specified.
Exit Status:
Returns 0 if the directory is changed; non-zero otherwise
相对的shell外部命令使用man [命令名]查看文档
help查看内部命令的文档
[root@MDNode01 ~]# help
GNU bash, version 4.1.2(1)-release (x86_64-redhat-linux-gnu)
These shell commands are defined internally. Type `help' to see this list.
Type `help name' to find out more about the function `name'.
Use `info bash' to find out more about the shell in general.
Use `man -k' or `info' to find out more about commands not in this list.
A star (*) next to a name means that the command is disabled.
job_spec [&] history [-c] [-d offset] [n] or history -anrw [filename] or history -ps arg [arg...]
(( expression )) if COMMANDS; then COMMANDS; [ elif COMMANDS; then COMMANDS; ]... [ else COMMANDS; ] fi
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs -x command [args]
: kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... or kill -l [sigspec]
[ arg... ] let arg [arg ...]
[[ expression ]] local [option] name[=value] ...
alias [-p] [name[=value] ... ] logout [n]
bg [job_spec ...] mapfile [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]
bind [-lpvsPVS] [-m keymap] [-f filename] [-q name] [-u name] [-r keyseq] [-x keyseq:shell-command> popd [-n] [+N | -N]
break [n] printf [-v var] format [arguments]
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
caller [expr] pwd [-LP]
case WORD in [PATTERN [| PATTERN]...) COMMANDS ;;]... esac read [-ers] [-a array] [-d delim] [-i text] [-n nchars] [-N nchars] [-p prompt] [-t timeout] [-u >
cd [-L|-P] [dir] readarray [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]
command [-pVv] command [arg ...] readonly [-af] [name[=value] ...] or readonly -p
compgen [-abcdefgjksuv] [-o option] [-A action] [-G globpat] [-W wordlist] [-F function] [-C com> return [n]
complete [-abcdefgjksuv] [-pr] [-DE] [-o option] [-A action] [-G globpat] [-W wordlist] [-F funct> select NAME [in WORDS ... ;] do COMMANDS; done
compopt [-o|+o option] [-DE] [name ...] set [--abefhkmnptuvxBCHP] [-o option-name] [arg ...]
continue [n] shift [n]
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
declare [-aAfFilrtux] [-p] [name[=value] ...] source filename [arguments]
dirs [-clpv] [+N] [-N] suspend [-f]
disown [-h] [-ar] [jobspec ...] test [expr]
echo [-neE] [arg ...] time [-p] pipeline
enable [-a] [-dnps] [-f filename] [name ...] times
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
exec [-cl] [-a name] [command [arguments ...]] [redirection ...] true
exit [n] type [-afptP] name [name ...]
export [-fn] [name[=value] ...] or export -p typeset [-aAfFilrtux] [-p] name[=value] ...
false ulimit [-SHacdefilmnpqrstuvx] [limit]
fc [-e ename] [-lnr] [first] [last] or fc -s [pat=rep] [command] umask [-p] [-S] [mode]
fg [job_spec] unalias [-a] name [name ...]
for NAME [in WORDS ... ] ; do COMMANDS; done unset [-f] [-v] [name ...]
for (( exp1; exp2; exp3 )); do COMMANDS; done until COMMANDS; do COMMANDS; done
function name { COMMANDS ; } or name () { COMMANDS ; } variables - Names and meanings of some shell variables
getopts optstring name [arg] wait [id]
hash [-lr] [-p pathname] [-dt] [name ...] while COMMANDS; do COMMANDS; done
help [-dms] [pattern ...] { COMMANDS ; }
这就是所有的内部命令
shereis
查看命令的位置和帮助文档的位置,方便学校Linux
[root@MDNode01 ~]# whereis ifconfig
ifconfig: /sbin/ifconfig /usr/share/man/man8/ifconfig.8.gz
编码
ASCII表
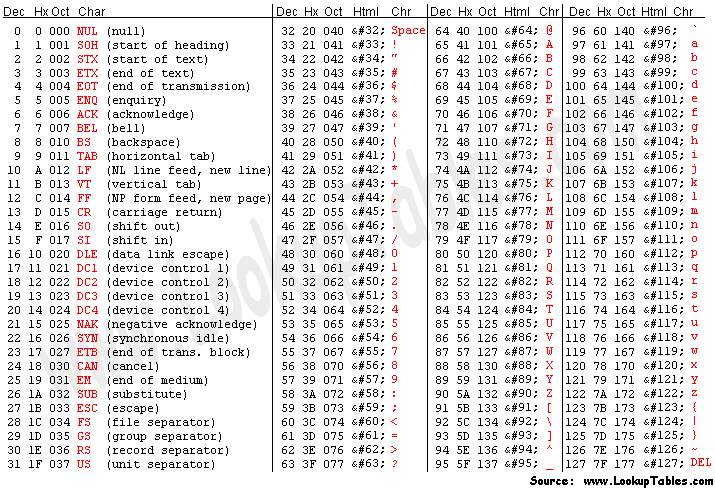
一个字符开辟一个字节,一个字节8个2进制位
2^ 0=1.000000
2^ 1=2.000000
2^ 2=4.000000
2^ 3=8.000000
2^ 4=16.000000
2^ 5=32.000000
2^ 6=64.000000
2^ 7=128.000000
2^ 8=256.000000
2^ 9=512.000000
2^10=1024.000000
2^11=2048.000000
八个二进制位中最高位只能存0代表整数,
即:ASCII表示0到2^7-1个,
[root@MDNode01 ~]# man ascii
ASCII(7) Linux Programmer’s Manual ASCII(7)
NAME
ascii - the ASCII character set encoded in octal, decimal, and hexadecimal
DESCRIPTION
ASCII is the American Standard Code for Information Interchange. It is a 7-bit code. Many 8-bit codes (such as ISO 8859-1, the Linux default character set) contain ASCII as
their lower half. The international counterpart of ASCII is known as ISO 646.
The following table contains the 128 ASCII characters.
C program '\X' escapes are noted.
Oct Dec Hex Char Oct Dec Hex Char
------------------------------------------------------------------------
000 0 00 NUL '\0' 100 64 40 @
001 1 01 SOH (start of heading) 101 65 41 A
002 2 02 STX (start of text) 102 66 42 B
003 3 03 ETX (end of text) 103 67 43 C
004 4 04 EOT (end of transmission) 104 68 44 D
005 5 05 ENQ (enquiry) 105 69 45 E
006 6 06 ACK (acknowledge) 106 70 46 F
007 7 07 BEL '\a' (bell) 107 71 47 G
010 8 08 BS '\b' (backspace) 110 72 48 H
011 9 09 HT '\t' (horizontal tab) 111 73 49 I
012 10 0A LF '\n' (new line) 112 74 4A J
013 11 0B VT '\v' (vertical tab) 113 75 4B K
014 12 0C FF '\f' (form feed) 114 76 4C L
015 13 0D CR '\r' (carriage ret) 115 77 4D M
016 14 0E SO (shift out) 116 78 4E N
017 15 0F SI (shift in) 117 79 4F O
020 16 10 DLE (data link escape) 120 80 50 P
021 17 11 DC1 (device control 1) 121 81 51 Q
022 18 12 DC2 (device control 2) 122 82 52 R
023 19 13 DC3 (device control 3) 123 83 53 S
024 20 14 DC4 (device control 4) 124 84 54 T
025 21 15 NAK (negative ack.) 125 85 55 U
026 22 16 SYN (synchronous idle) 126 86 56 V
027 23 17 ETB (end of trans. blk) 127 87 57 W
030 24 18 CAN (cancel) 130 88 58 X
031 25 19 EM (end of medium) 131 89 59 Y
032 26 1A SUB (substitute) 132 90 5A Z
033 27 1B ESC (escape) 133 91 5B [
034 28 1C FS (file separator) 134 92 5C \ '\\'
035 29 1D GS (group separator) 135 93 5D ]
036 30 1E RS (record separator) 136 94 5E ^
037 31 1F US (unit separator) 137 95 5F _
040 32 20 SPACE 140 96 60 `
041 33 21 ! 141 97 61 a
042 34 22 " 142 98 62 b
043 35 23 # 143 99 63 c
044 36 24 $ 144 100 64 d
045 37 25 % 145 101 65 e
046 38 26 & 146 102 66 f
047 39 27 ´ 147 103 67 g
050 40 28 ( 150 104 68 h
051 41 29 ) 151 105 69 i
052 42 2A * 152 106 6A j
053 43 2B + 153 107 6B k
054 44 2C , 154 108 6C l
055 45 2D - 155 109 6D m
056 46 2E . 156 110 6E n
057 47 2F / 157 111 6F o
060 48 30 0 160 112 70 p
061 49 31 1 161 113 71 q
062 50 32 2 162 114 72 r
063 51 33 3 163 115 73 s
064 52 34 4 164 116 74 t
065 53 35 5 165 117 75 u
066 54 36 6 166 118 76 v
067 55 37 7 167 119 77 w
070 56 38 8 170 120 78 x
071 57 39 9 171 121 79 y
072 58 3A : 172 122 7A z
073 59 3B ; 173 123 7B {
074 60 3C < 174 124 7C |
075 61 3D = 175 125 7D }
076 62 3E > 176 126 7E ~
077 63 3F ? 177 127 7F DEL
Tables
For convenience, let us give more compact tables in hex and decimal.
2 3 4 5 6 7 30 40 50 60 70 80 90 100 110 120
------------- ---------------------------------
0: 0 @ P ` p 0: ( 2 < F P Z d n x
1: ! 1 A Q a q 1: ) 3 = G Q [ e o y
2: " 2 B R b r 2: * 4 > H R \ f p z
3: # 3 C S c s 3: ! + 5 ? I S ] g q {
4: $ 4 D T d t 4: " , 6 @ J T ^ h r |
5: % 5 E U e u 5: # - 7 A K U _ i s }
6: & 6 F V f v 6: $ . 8 B L V ` j t ~
7: ´ 7 G W g w 7: % / 9 C M W a k u DEL
8: ( 8 H X h x 8: & 0 : D N X b l v
9: ) 9 I Y i y 9: ´ 1 ; E O Y c m w
A: * : J Z j z
B: + ; K [ k {
C: , < L \ l |
D: - = M ] m }
E: . > N ^ n ~
F: / ? O _ o DEL
NOTES
History
An ascii manual page appeared in Version 7 of AT&T UNIX.
On older terminals, the underscore code is displayed as a left arrow, called backarrow, the caret is displayed as an up-arrow and the vertical bar has a hole in the middle.
Uppercase and lowercase characters differ by just one bit and the ASCII character 2 differs from the double quote by just one bit, too. That made it much easier to encode
characters mechanically or with a non-microcontroller-based electronic keyboard and that pairing was found on old teletypes.
The ASCII standard was published by the United States of America Standards Institute (USASI) in 1968.
SEE ALSO
UTF-8
[root@MDNode01 ~]# man utf-8
UTF-8(7) Linux Programmer’s Manual UTF-8(7)
NAME
UTF-8 - an ASCII compatible multi-byte Unicode encoding
DESCRIPTION
The Unicode 3.0 character set occupies a 16-bit code space. The most obvious Unicode encoding (known as UCS-2) consists of a sequence of 16-bit words. Such strings can con-
tain as parts of many 16-bit characters bytes like '\0' or '/' which have a special meaning in filenames and other C library function arguments. In addition, the majority of
Unix tools expects ASCII files and can’t read 16-bit words as characters without major modifications. For these reasons, UCS-2 is not a suitable external encoding of Unicode
in filenames, text files, environment variables, etc. The ISO 10646 Universal Character Set (UCS), a superset of Unicode, occupies even a 31-bit code space and the obvious
UCS-4 encoding for it (a sequence of 32-bit words) has the same problems.
The UTF-8 encoding of Unicode and UCS does not have these problems and is the common way in which Unicode is used on Unix-style operating systems.
Properties
The UTF-8 encoding has the following nice properties:
* UCS characters 0x00000000 to 0x0000007f (the classic US-ASCII characters) are encoded simply as bytes 0x00 to 0x7f (ASCII compatibility). This means that files and strings
which contain only 7-bit ASCII characters have the same encoding under both ASCII and UTF-8.
* All UCS characters greater than 0x7f are encoded as a multi-byte sequence consisting only of bytes in the range 0x80 to 0xfd, so no ASCII byte can appear as part of another
character and there are no problems with, for example, '\0' or '/'.
* The lexicographic sorting order of UCS-4 strings is preserved.
* All possible 2^31 UCS codes can be encoded using UTF-8.
* The bytes 0xfe and 0xff are never used in the UTF-8 encoding.
* The first byte of a multi-byte sequence which represents a single non-ASCII UCS character is always in the range 0xc0 to 0xfd and indicates how long this multi-byte sequence
is. All further bytes in a multi-byte sequence are in the range 0x80 to 0xbf. This allows easy resynchronization and makes the encoding stateless and robust against miss-
ing bytes.
* UTF-8 encoded UCS characters may be up to six bytes long, however the Unicode standard specifies no characters above 0x10ffff, so Unicode characters can only be up to four
bytes long in UTF-8.
Encoding
The following byte sequences are used to represent a character. The sequence to be used depends on the UCS code number of the character:
0x00000000 - 0x0000007F:
0xxxxxxx
0x00000080 - 0x000007FF:
110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF:
1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF:
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0x00200000 - 0x03FFFFFF:
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF:
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
The xxx bit positions are filled with the bits of the character code number in binary representation. Only the shortest possible multi-byte sequence which can represent the
code number of the character can be used.
The UCS code values 0xd800–0xdfff (UTF-16 surrogates) as well as 0xfffe and 0xffff (UCS non-characters) should not appear in conforming UTF-8 streams.
Example
The Unicode character 0xa9 = 1010 1001 (the copyright sign) is encoded in UTF-8 as
11000010 10101001 = 0xc2 0xa9
and character 0x2260 = 0010 0010 0110 0000 (the "not equal" symbol) is encoded as:
11100010 10001001 10100000 = 0xe2 0x89 0xa0
Application Notes
Users have to select a UTF-8 locale, for example with
export LANG=en_GB.UTF-8
in order to activate the UTF-8 support in applications.
Application software that has to be aware of the used character encoding should always set the locale with for example
setlocale(LC_CTYPE, "")
and programmers can then test the expression
strcmp(nl_langinfo(CODESET), "UTF-8") == 0
to determine whether a UTF-8 locale has been selected and whether therefore all plaintext standard input and output, terminal communication, plaintext file content, filenames
and environment variables are encoded in UTF-8.
Programmers accustomed to single-byte encodings such as US-ASCII or ISO 8859 have to be aware that two assumptions made so far are no longer valid in UTF-8 locales. Firstly,
a single byte does not necessarily correspond any more to a single character. Secondly, since modern terminal emulators in UTF-8 mode also support Chinese, Japanese, and
Korean double-width characters as well as non-spacing combining characters, outputting a single character does not necessarily advance the cursor by one position as it did in
ASCII. Library functions such as mbsrtowcs(3) and wcswidth(3) should be used today to count characters and cursor positions.
The official ESC sequence to switch from an ISO 2022 encoding scheme (as used for instance by VT100 terminals) to UTF-8 is ESC % G ("\x1b%G"). The corresponding return
sequence from UTF-8 to ISO 2022 is ESC % @ ("\x1b%@"). Other ISO 2022 sequences (such as for switching the G0 and G1 sets) are not applicable in UTF-8 mode.
It can be hoped that in the foreseeable future, UTF-8 will replace ASCII and ISO 8859 at all levels as the common character encoding on POSIX systems, leading to a signifi-
cantly richer environment for handling plain text.
Security
The Unicode and UCS standards require that producers of UTF-8 shall use the shortest form possible, for example, producing a two-byte sequence with first byte 0xc0 is non-con-
forming. Unicode 3.1 has added the requirement that conforming programs must not accept non-shortest forms in their input. This is for security reasons: if user input is
checked for possible security violations, a program might check only for the ASCII version of "/../" or ";" or NUL and overlook that there are many non-ASCII ways to represent
these things in a non-shortest UTF-8 encoding.
Standards
ISO/IEC 10646-1:2000, Unicode 3.1, RFC 2279, Plan 9.
SEE ALSO
nl_langinfo(3), setlocale(3), charsets(7), unicode(7)
COLOPHON
This page is part of release 3.22 of the Linux man-pages project. A description of the project, and information about reporting bugs, can be found at http://www.ker-
nel.org/doc/man-pages/.
GNU 2001-05-11 UTF-8(7)
文件
df
查询磁盘分区的大小
du
[root@MDNode01 usr]# du -sh ./*
19M ./bin
4.0K ./etc
4.0K ./games
40K ./include
98M ./lib
55M ./lib64
7.8M ./libexec
132K ./local
24M ./sbin
182M ./share
12K ./src
0 ./tmp
统计当前文件夹下面的所以文件的带下
cd ~[用户]
进入用户的家目录
mkdir
深度创建文件夹和广度创建目录
mkdir -p ./a/b/c/d
深度创建一个目录,
mkdir ./abc/{x,y,z}dir
这样就可以在当前目录下面的abc目录下面创建xdir,ydir,zdir文件了
touch
创建一个文件
rm
rm [参数] [文件/文件夹] 这样就可删除了
参数:
-f 强制删除
-r递归删除一个目录
cp
复制文件 cp [要复制的文件] [复制到那个目录/可以给文件重命名]
mv
移动文件 mv [要移动的文件] [复制到那个文件夹/可以重新命名文件]
reboot
重启设备
文本处理
cut
显示切割的行数据
-f 显示的列
-s 弃掉脏数据
-d 分割符
[root@MDNode01 ~]# clear
[root@MDNode01 ~]# cat b.txt
sdaf dsaf sdafdsa
dsa sda sdaf dssaf
dsa
sadf dsaf
fdsaf sad dsaf
dsafdsa fdsaf
dsafdsafdsaf
dsaaaaaaaaaaaaaaaaaaaaaaaa
[root@MDNode01 ~]# cut -s -d' ' -f2 b.txt
#显示b.txt文件内容按照空格分开每一行成不同的列,弃掉脏数据后显示能分成两列的数据
dsaf
sda
dsaf
sad
fdsaf
[root@MDNode01 ~]# cut -s -d' ' -f2,3 b.txt
#显示2列和3列的数据集
dsaf sdafdsa
sda sdaf
dsaf
sad dsaf
fdsaf
[root@MDNode01 ~]# cut -s -d' ' -f2-3 b.txt
#输出2列到3列的数据
dsaf sdafdsa
sda sdaf
dsaf
sad dsaf
fdsaf
[root@MDNode01 ~]#
sort
排序文件的行【顺序由数值排序和字典排序】
-n 按照数值排序
-r 倒叙
-t 自定义分割符
-k 选择排序的序列
-u 合并相同的行
-f 忽略大小写
[root@MDNode01 ~]# cat sort.txt
orange 90
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# sort sort.txt
# 按照字典序排序sour.txt文件,
apple 55
banana 34
orange 90
pumpkino 76
[root@MDNode01 ~]# sort -t' ' -k2 sort.txt
#于-t后面的空格符,分割得到的第二列,按照字典排序输出
banana 34
apple 55
pumpkino 76
orange 90
[root@MDNode01 ~]# sort -t' ' -k2 -n sort.txt
#数值排序
banana 34
apple 55
pumpkino 76
orange 90
[root@MDNode01 ~]# sort -t' ' -k2 -nr sort.txt
#数值排序的倒序
orange 90
pumpkino 76
apple 55
banana 34
wc
统计文件的行数
-c 统计文件的字节
-m 统计文件的字符
-l 统计行数
-L 统计最大的行数
-w 统计单词数
[root@MDNode01 ~]# wc -l sort.txt
4 sort.txt
[root@MDNode01 ~]# wc -w sort.txt
8 sort.txt
[root@MDNode01 ~]# wc -L sort.txt
11 sort.txt
[root@MDNode01 ~]# wc -c sort.txt
41 sort.txt
[root@MDNode01 ~]# wc -m sort.txt
41 sort.txt
sed
sed和vi是相对于的,vi是全屏阻塞编辑,而sed是行编辑器,
sed [options] 'AddressCommand' flie
-n 静默模式,读出的文件不会有显示,
-i 直接修改原文件
-e SCRPT -e SSECRIPT:可以执行多个脚本,
-f /PATH/TO/SED_SCRIP
-r 表示使用扩展的正则表达式
Command
d 删除符合条件的行
p 显示符合条件的行
a \string : 在指定的行后面追加新的行,内容为string
a\n:表示换行
i\string: 在指定的行前面插入新的行,内容为string
r FILE:就阿尼古指定文件的内容添加至符合条件的行处,
w FILE: 讲地址指定的范围内的行另保存到指定的文件中,
s/pattern/string/修饰符:查找并替换,默认只替换每一次第一次被模式匹配的字符串
- g:行内全局替换
- i:忽略大小写,
- s//😒###,s@@@
- \ ( \ ) ,\ 1, \2
sed 行编辑器Address
可以没有,
给定范围
查找指定的行 /str/
[root@MDNode01 ~]# cat sort.txt
orange 90
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# sed -i "1a\hello world" sort.txt
#-i 插入 1第一行 a 追加 \hello world 追加的内容 sort.txt 文件
[root@MDNode01 ~]# cat sort.txt
orange 90
hello world
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# sed "2d" sort.txt
#删除第2行的数据
orange 90
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# cat sort.txt
orange 90
hello world
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# sed "/[0-9]/d" sort.txt
#删除包含0到9数字的行
hello world
[root@MDNode01 ~]# cat sort.txt
orange 90
hello world
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# sed -n "/[0-9]/p" sort.txt
#把包含0到9的行p打印出来
orange 90
apple 55
banana 34
pumpkino 76
[root@MDNode01 ~]# cat inittab
# inittab is only used by upstart for the default runlevel.
#
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# System initialization is started by /etc/init/rcS.conf
#
# Individual runlevels are started by /etc/init/rc.conf
#
# Ctrl-Alt-Delete is handled by /etc/init/control-alt-delete.conf
#
# Terminal gettys are handled by /etc/init/tty.conf and /etc/init/serial.conf,
# with configuration in /etc/sysconfig/init.
#
# For information on how to write upstart event handlers, or how
# upstart works, see init(5), init(8), and initctl(8).
#
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:3:initdefault:
[root@MDNode01 ~]# sed "s/id:[0-6]:initdefault:/id:5initdefault:/" inittab
############ 查找id:3:initdefault:并替换id:5:initdefault:
# inittab is only used by upstart for the default runlevel.
#
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# System initialization is started by /etc/init/rcS.conf
#
# Individual runlevels are started by /etc/init/rc.conf
#
# Ctrl-Alt-Delete is handled by /etc/init/control-alt-delete.conf
#
# Terminal gettys are handled by /etc/init/tty.conf and /etc/init/serial.conf,
# with configuration in /etc/sysconfig/init.
#
# For information on how to write upstart event handlers, or how
# upstart works, see init(5), init(8), and initctl(8).
#
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:5initdefault:
[root@MDNode01 ~]# sed "s/\(id:\)[0-6]\(:initdefault:\)/\15\2/" inittab
#############使用正则表达式替换
# inittab is only used by upstart for the default runlevel.
#
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# System initialization is started by /etc/init/rcS.conf
#
# Individual runlevels are started by /etc/init/rc.conf
#
# Ctrl-Alt-Delete is handled by /etc/init/control-alt-delete.conf
#
# Terminal gettys are handled by /etc/init/tty.conf and /etc/init/serial.conf,
# with configuration in /etc/sysconfig/init.
#
# For information on how to write upstart event handlers, or how
# upstart works, see init(5), init(8), and initctl(8).
#
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:5:initdefault:
awk
是一个强大的文本分析工具
相对于grep的查找,sed的编辑,awk在对数据分析并生成报告时候,显得尤为强大,
简单来说wak就是把文件逐行的读入,(空格和制表符)为默认的分隔符将每片切片,切片的部分再进行各种分析处理。
sek -F '{pattern+action}' {filenames}
支持自定义分隔符
支持正则表达式
支持自定义变量,数组,a[1] a[tom] map(key)
支持内置变量
- ARGC 命令行参数个数
- ARGV 命令行参数排列
- ENVIPON 支持队列中系统环境变量的使用
- FILENAME awk浏览文件名
- FNP 浏览文件的记录数
- FS 设置输入域分隔符
- NF 浏览文件的域的个数
- NR 已读的记录数
- OFS 输出域分隔符
- ORS 输出记录分隔符
- PS 控制记录分割符
支持函数
print、split、substr、sub、gssub
支持控制流程语句,类c语言
if、while、do/while、for、break、continue
[root@MDNode01 ~]# cat passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
nobody:x:99:99:Nobody:/:/sbin/nologin
vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
saslauth:x:499:76:"Saslauthd user":/var/empty/saslauth:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
### 只是显示账号的CUt
[root@MDNode01 ~]# awk -F ':' '{print $1}' passwd
###用 : 做为分割符,显示第一列
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
uucp
operator
games
gopher
ftp
nobody
vcsa
saslauth
postfix
sshd
### 显示账号和账号相对于的shell,而账号和shell之间用以逗号分割,而且在所有的行开始添加列名 name shell,在最后一行添加 "blue,/bin/nost" (cut,sed)
[root@MDNode01 ~]# awk -F ':' 'BEGIN{print "name:\tshell"} {print $1,"\t",$7} END{print "/etc/passwd"}' passwd
name: shell
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
shutdown /sbin/shutdown
halt /sbin/halt
mail /sbin/nologin
uucp /sbin/nologin
operator /sbin/nologin
games /sbin/nologin
gopher /sbin/nologin
ftp /sbin/nologin
nobody /sbin/nologin
vcsa /sbin/nologin
saslauth /sbin/nologin
postfix /sbin/nologin
sshd /sbin/nologin
/etc/passwd
### 查找含有root的行,打印出来
[root@MDNode01 ~]# awk '/root/ {print $0}' passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
######排序成下面的格式输出相对于的内容
[root@MDNode01 ~]# awk -F':' '{print NR"\t"NF"\t"$0}' passwd
1 7 root:x:0:0:root:/root:/bin/bash
2 7 bin:x:1:1:bin:/bin:/sbin/nologin
3 7 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 7 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 7 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 7 sync:x:5:0:sync:/sbin:/bin/sync
7 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 7 halt:x:7:0:halt:/sbin:/sbin/halt
9 7 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 7 uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
11 7 operator:x:11:0:operator:/root:/sbin/nologin
12 7 games:x:12:100:games:/usr/games:/sbin/nologin
13 7 gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
14 7 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
15 7 nobody:x:99:99:Nobody:/:/sbin/nologin
16 7 vcsa:x:69:69:virtual console memory owner:/dev:/sbin/nologin
17 7 saslauth:x:499:76:"Saslauthd user":/var/empty/saslauth:/sbin/nologin
18 7 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 7 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin


 浙公网安备 33010602011771号
浙公网安备 33010602011771号