


java实现 tf-idf
1、前言
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency)。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
2、原理
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
TF表示词条在文档d中出现的频率。
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力
如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。
但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处
3、公式
TF公式:
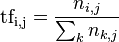
以上式子中  是该词在文件
是该词在文件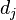 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
IDF公式:
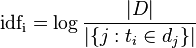
|D|: 语料库中的文件总数
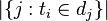 : 包含词语
: 包含词语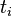 的文件数目(即
的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用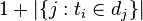
然后

4、java实现


import org.apache.solr.client.solrj.SolrClient; import org.apache.solr.client.solrj.SolrQuery; import org.apache.solr.client.solrj.SolrServerException; import org.apache.solr.client.solrj.impl.HttpSolrClient; import org.apache.solr.client.solrj.request.AbstractUpdateRequest; import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest; import org.apache.solr.client.solrj.response.QueryResponse; import org.apache.solr.client.solrj.response.UpdateResponse; import org.apache.solr.common.SolrDocument; import org.apache.solr.common.SolrDocumentList; import org.apache.solr.common.SolrInputDocument; import java.io.File; import java.io.IOException; import java.text.SimpleDateFormat; import java.util.*; /** * @Author:sks * @Description:根据tfidf理论计算,是一种用于信息检索与数据挖掘的常用加权技术。 * TF意思是词频(Term Frequency), * IDF意思是逆向文件频率(Inverse Document Frequency)。 * @Date:Created in 9:30 2018/1/10 * @Modified by: **/ public class tfidf { private static SolrClient solr; //单个文档中所有分词出现次数总和 private static int singleDocTotalCount = 0; //统计在单一文章中出现次数大于某个数的关键字,默认是3 private static int KEYWORD_MIN_COUNT_IN_SINGLE_DOC = 3; public static void main(String[] args) throws SolrServerException,IOException { List<String> excludeInfo = new ArrayList<String>(); excludeInfo.add("WORD模版"); excludeInfo.add("Page"); String urlString = "http://localhost:8983/solr/test"; String path = "D:/work/Solr/ImportData"; Init(urlString); // indexFilesSolrCell(path,excludeInfo); // try { // Thread.sleep(3000); // } catch (InterruptedException e) { // e.printStackTrace(); // } // //资料库中文档总数 int docmentTotalCount = (int)getDocTotalCount(); // setIdf(docmentTotalCount); //获取重要关键字 getImportanceKeywords(docmentTotalCount); } /** * @Author:sks * @Description:初始化solr客户端 * @Date: */ public static void Init(String urlString){ solr = new HttpSolrClient.Builder(urlString).build(); } /** * @Author:sks * @Description:获取文档总数 * @Date: */ private static long getDocTotalCount() throws SolrServerException,IOException{ long num = 0; try { SolrQuery params = new SolrQuery(); params.set("q", "*:*"); //params.setQuery("*:*"); QueryResponse rsp = solr.query(params); SolrDocumentList docs = rsp.getResults(); num = docs.getNumFound(); } catch (SolrServerException e) { e.printStackTrace(); } return num; } /** * @Author:sks * @Description:索引文件夹fileDirectory(不包含子文件夹)下的所有文件, * @Date: */ private static void indexFilesSolrCell(String fileDirectory,List<String> excludeInfo) throws IOException, SolrServerException{ File file = new File(fileDirectory); File[] files = file.listFiles(); for(File f :files){ singleDocTotalCount = 0; indexFilesSolrCell(f.getName(),f.toString(),excludeInfo); } } /** * @Author:sks * @Description:索引文件, * @Date: * @fileName:文件名 * @path:文件路径(包含文件名) */ private static void indexFilesSolrCell(String fileName, String path,List<String> excludeInfo) throws IOException, SolrServerException { ContentStreamUpdateRequest up = new ContentStreamUpdateRequest("/update/extract"); String contentType = getFileContentType(fileName); up.addFile(new File(path), contentType); String fileType = fileName.substring(fileName.lastIndexOf(".")+1); up.setParam("literal.id", fileName); up.setParam("literal.path", path);//文件路径 up.setParam("fmap.content", "attr_content");//文件内容 up.setAction(AbstractUpdateRequest.ACTION.COMMIT, true, true); solr.request(up); String txt = getTextById(fileName,"attr_content",excludeInfo); if(txt.length()==0) { System.out.println("文件"+fileName+"索引失败"); return; } delIndexByID(fileName); Map<String, String> temp = new HashMap<String, String>(); temp.put("id",fileName);//文档id,用文件名作为ID temp.put("text",txt);//文件文本 temp.put("fileType",fileType);//文件类型 temp.put("fileloadDate",GetCurrentDate());//上传日期 //统计出现次数大于等于3的关键字 String keywords = getTopKeywords(KEYWORD_MIN_COUNT_IN_SINGLE_DOC,txt); temp.put("wordCount",keywords); //统计出现次数大于等于3的关键字频率 String tf =getTopKeywordsFrequency(KEYWORD_MIN_COUNT_IN_SINGLE_DOC,txt); temp.put("tf",tf); updateMultiFieldData(temp); } /** * @Author:sks * @Description:根据id,获取字段field对应的数据 * @Date: */ private static String getTextById(String id,String field,List<String> excludeInfo) throws SolrServerException,IOException { //使用这个对象做查询 SolrQuery params = new SolrQuery(); //查询所有数据 params.setQuery("id:"+id); params.setFields(field); QueryResponse queryResponse = solr.query(params); //拿到数据集合,返回查询结果 List<SolrDocument> list = queryResponse.getResults(); String txt = ""; for(SolrDocument solrDocument :list){ if (solrDocument.size() >0){ txt = solrDocument.get(field).toString(); break; } } txt = txt.replace(" ",""); String[] txts = txt.split("\n"); StringBuilder sb = new StringBuilder(); boolean bcontinue = false; for(String t:txts){ if(t.length()==0){ continue; } bcontinue = false; for(String m:excludeInfo) { if(t.indexOf(m)>-1) { bcontinue = true; break; } } if(bcontinue){ continue; } sb.append(t); sb.append("\n"); } return sb.toString(); } /** * @Author:sks * @Description:获取文本中出现次数较高的关键字 * @Date: * @keywordCount:出现的次数 * @txt:文本信息 */ private static String getTopKeywords(int keywordCount,String txt) throws SolrServerException,IOException{ Map<String, Integer> totalMap = getAllWordsFromText(txt); List<Map.Entry<String,Integer>> result = GetTopvalues(totalMap,keywordCount); String keywords= ""; StringBuilder sb = new StringBuilder(); for (Map.Entry<String,Integer> lt : result) { sb.append(lt.getKey()); sb.append(":"); sb.append(lt.getValue()); sb.append(","); } keywords = sb.toString(); if(result.size()>1){ keywords = keywords.substring(0,keywords.length()-1); } return keywords; } /** * @Author:sks * @Description:获取文本中出现次数较高的关键字及其词频 * @Date: * @keywordCount:出现的次数 * @txt:文本信息 */ private static String getTopKeywordsFrequency(int keywordCount,String txt) throws SolrServerException,IOException{ Map<String, Integer> totalMap = getAllWordsFromText(txt); List<Map.Entry<String,Integer>> result = GetTopvalues(totalMap,keywordCount); StringBuilder sb = new StringBuilder(); for (Map.Entry<String,Integer> lt : result) { sb.append(lt.getKey()); sb.append(":"); float value = (float)lt.getValue()/singleDocTotalCount ; sb.append(String.format("%.8f",value)); sb.append(","); } String keywords = sb.toString(); if(result.size()>1){ keywords = keywords.substring(0,keywords.length()-1); } return keywords; } /** * @Author:sks * @Description:更新多个字段数据, * @Date: * @maps:字段名和值键值对 */ private static void updateMultiFieldData( Map<String, String> maps) throws IOException, SolrServerException{ Set<String> keys = maps.keySet(); SolrInputDocument doc = new SolrInputDocument(); for (String key:keys){ doc.addField(key,maps.get(key)); } solr.add(doc); UpdateResponse rspCommit = solr.commit(); System.out.println("commit doc to index" + " result:" + rspCommit.getStatus() + " Qtime:" + rspCommit.getQTime()); } /** * @Author:sks * @Description:把字符串分词,统计分词的重复次数,把分词和次数存在键值对里面 * @Date: */ private static Map<String, Integer> getAllWordsFromText(String txt) throws SolrServerException, IOException { List<String> wlist = new ArrayList(); //由于文本太长,不能进行分词,所以要把文本拆分开分别进行分词,每500长度的文本作为一组进行分词 int l = txt.length(); if(txt.length()>500) { String[] txts = txt.split("\n"); String words = ""; for (int i = 0; i < txts.length; i++) { if (words.length() < 500) { words += txts[i] + "。"; } else { wlist.add(words); words = txts[i] + "。"; } } wlist.add(words); } else { wlist.add(txt); } int count = 0; Map<String, Integer> rawMap = null; List<String> results = null; Set<String> keys = null; Map<String, Integer> totalMap = new HashMap<String, Integer>(); NewsSummary obj = new NewsSummary(); for(String txtline :wlist) { if (txtline != null && txtline.length()>0) { results = obj.IKSegment(txtline); // results = getAnalysis(txtline); rawMap = getWordsCount(results); keys = rawMap.keySet(); for (String key : keys) { singleDocTotalCount++; count = rawMap.get(key); if(totalMap.containsKey(key)) { count += totalMap.get(key); totalMap.remove(key); } else { totalMap.put(key,count); } } } } return totalMap; } /** * @Author:sks * @Description:把列表中的数据存储在键值对里面,重复次数累加 * @Date: */ private static Map<String, Integer> getWordsCount(List<String> txts) throws SolrServerException, IOException { Map<String, Integer> resultMap = new HashMap<String, Integer>(); int count = 1; for(int i = 0;i<txts.size();i++){ String key = txts.get(i) ; if(key.length()>1) { count = 1; if (resultMap.containsKey(key)) { count += resultMap.get(key); } resultMap.remove(key); resultMap.put(key, count); } } return resultMap; } /** * @Author:sks * @Description:给map按照值降序排序,并取值大于topValue的键值对返回 * @Date: */ private static List<Map.Entry<String,Integer>> GetTopvalues(Map<String, Integer> hm,Integer topValue) throws SolrServerException, IOException { Map<String, Integer> temp = new HashMap<String, Integer>(); Set<String> keys = hm.keySet(); int value = 0; for(String key :keys) { value = hm.get(key); if (value >= topValue) { temp.put(key,value); } } //这里将map.entrySet()转换成list List<Map.Entry<String,Integer>> list = new ArrayList<Map.Entry<String,Integer>>(temp.entrySet()); //然后通过比较器来实现排序 Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() { //降序排序 public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); return list; } /** * @Author:sks * @Description:根据文件名获取文件的ContentType类型 * @Date: */ public static String getFileContentType(String filename) { String contentType = ""; String prefix = filename.substring(filename.lastIndexOf(".") + 1); if (prefix.equals("xlsx")) { contentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"; } else if (prefix.equals("pdf")) { contentType = "application/pdf"; } else if (prefix.equals("doc")) { contentType = "application/msword"; } else if (prefix.equals("txt")) { contentType = "text/plain"; } else if (prefix.equals("xls")) { contentType = "application/vnd.ms-excel"; } else if (prefix.equals("docx")) { contentType = "application/vnd.openxmlformats-officedocument.wordprocessingml.document"; } else if (prefix.equals("ppt")) { contentType = "application/vnd.ms-powerpoint"; } else if (prefix.equals("pptx")) { contentType = "application/vnd.openxmlformats-officedocument.presentationml.presentation"; } else { contentType = "othertype"; } return contentType; } /** * @Author:sks * @Description:删除指定ID的索引 * @Date: * @id:索引ID */ public static void delIndexByID(String id) throws SolrServerException, IOException{ UpdateResponse ur = solr.deleteById(id); System.out.println(ur); UpdateResponse c = solr.commit(); System.out.println(c); } /** * @Author:sks * @Description:设置idf * @Date: * @docmentTotalCount:资料库中文档总数 */ private static void setIdf(int docmentTotalCount) throws SolrServerException,IOException { Map<String, String> map = getidKeywordTFMap(docmentTotalCount); Set<String> keys = map.keySet(); String[] words = null; String word = ""; double tf = 0; double idf = 0; StringBuilder sbtfidf = null; StringBuilder sbidf = null; String singleword = ""; // region for(String key:keys){ word = map.get(key); //去掉开头的[和结尾的]符合 word = word.substring(1,word.length()-2); words = word.split(","); sbtfidf = new StringBuilder(); sbidf = new StringBuilder(); for(String w :words) { System.out.println(w); tf = Float.parseFloat(w.split(":")[1]); singleword = w.split(":")[0]; idf = getwordIdf(singleword,docmentTotalCount); sbidf.append(singleword); sbidf.append(":"); sbidf.append(getwordindocCount(singleword,docmentTotalCount)); sbidf.append(","); sbtfidf.append(singleword); sbtfidf.append(";"); sbtfidf.append(String .format("%.12f",tf*idf)); sbtfidf.append(","); } // endregion updateSingleData(key,"wordinDocCount",sbidf.toString()); updateSingleData(key,"tfIdf",sbtfidf.toString()); } } /** * @Author:sks * @Description:获取ID和keyword键值对 * @Date: */ private static Map<String, String> getidKeywordTFMap(int docmentTotalCount) throws SolrServerException,IOException { //使用这个对象做查询 SolrQuery params = new SolrQuery(); //查询所有数据 params.setQuery("*:*"); // params.setQuery("id:5.15%2B袁纯子、王英%2B路透社报告:欧洲七大公共媒体数字化转型进路 (1).docx"); // params.set("q", "*:*"); params.setFields("id,tf"); params.setStart(0); params.setRows(docmentTotalCount); QueryResponse rsp = solr.query(params); // SolrDocumentList docs = rsp.getResults(); List<SolrDocument> list = rsp.getResults(); Map<String, String> idkeywordMap = new HashMap<String, String>(); String result = ""; String id = ""; //循环打印数据集合 for (SolrDocument sd : list) { if(sd.size()>1) { idkeywordMap.put(sd.get("id").toString(), sd.get("tf").toString()); } } return idkeywordMap; } /** * @Author:sks * @Description:获取关键字的idf(inverse docment frequency) = log(文件总数/包含关键字的文件数) * @Date: * @word:关键字 * @docmentTotalCount:资料库中文档总数 */ private static double getwordIdf(String word,int docmentTotalCount) throws SolrServerException,IOException { int count = getwordindocCount(word,docmentTotalCount); double idf = 0 ; if (count>0) { idf = Math.log((double) docmentTotalCount / count); } return idf; } /** * @Author:sks * @Description:获取单词所在文档的个数 * @Date: * @word:关键字 * @docmentTotalCount:资料库中文档总数 */ private static int getwordindocCount(String word,int docmentTotalCount) throws SolrServerException,IOException { //使用这个对象做查询 SolrQuery params = new SolrQuery(); //查询所有数据 // params.setQuery("*:*"); params.setQuery("text:"+word); params.setFields("freq:termfreq(text,'"+word+"')"); //分页,默认是分页从0开始,每页显示10行 params.setStart(0); params.setRows(docmentTotalCount); QueryResponse queryResponse = solr.query(params); //拿到数据集合,返回查询结果 List<SolrDocument> list = queryResponse.getResults(); int count = 0; //循环打印数据集合 for (SolrDocument solrDocument : list) { if(solrDocument.get("freq").toString()!="0"){ count++; } } return count; } /** * @Author:sks * @Description:更新索引中单个属性数据 * @Date: * @id:索引ID * @fieldName:属性名称 * @fieldValue:属性值 */ public static void updateSingleData(String id,String fieldName,Object fieldValue) throws SolrServerException,IOException{ Map<String, Object> oper = new HashMap<String, Object>(); oper.put("set", fieldValue); SolrInputDocument doc = new SolrInputDocument(); doc.addField("id", id); doc.addField(fieldName, oper); UpdateResponse rsp = solr.add(doc); System.out.println("update doc id:" + id + " result:" + rsp.getStatus() + " Qtime:" + rsp.getQTime()); UpdateResponse rspCommit = solr.commit(); System.out.println("commit doc to index" + " result:" + rspCommit.getStatus() + " Qtime:" + rspCommit.getQTime()); } /** * @Author:sks * @Description:根据tf-idf 原理 获取资料库中重要关键字, * @Date: */ private static void getImportanceKeywords(int docmentTotalCount) throws SolrServerException,IOException { Map<String, String> map = getidKeywordTFMap(docmentTotalCount); Set<String> keys = map.keySet(); String[] words = null; String word = ""; double tf = 0; double idf = 0; double tfidf = 0; String singleword = ""; Map<String, Double> keywordidfMap = new HashMap<String, Double>(); // region for(String key:keys){ word = map.get(key); //去掉开头的[和结尾的]符合 word = word.substring(1,word.length()-2); words = word.split(","); for(String w :words) { tf = Float.parseFloat(w.split(":")[1]); singleword = w.split(":")[0]; idf = getwordIdf(singleword,docmentTotalCount); tfidf = tf * idf ; if(keywordidfMap.containsKey(singleword)) { if(keywordidfMap.get(singleword)>tfidf) { keywordidfMap.remove(singleword); keywordidfMap.put(singleword,tfidf); } } else { keywordidfMap.put(singleword,tfidf); } } } List<Map.Entry<String, Double>> sortedSentList = new ArrayList<Map.Entry<String,Double>>(keywordidfMap.entrySet());//按得分从高到底排序好的句子,句子编号与得分 //System.setProperty("java.util.Arrays.useLegacyMergeSort", "true"); Collections.sort(sortedSentList, new Comparator<Map.Entry<String, Double>>(){ // @Override public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) { return o2.getValue() == o1.getValue() ? 0 : (o2.getValue() > o1.getValue() ? 1 : -1); } }); for(Map.Entry<String, Double> entry:sortedSentList) { System.out.println(entry.getKey() + ":" + entry.getValue()); } } /** * @Author:sks * @Description:获取系统当天日期yyyy-mm-dd * @Date: */ private static String GetCurrentDate() throws SolrServerException,IOException { Date dt = new Date(); //最后的aa表示“上午”或“下午” HH表示24小时制 如果换成hh表示12小时制 // SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss aa"); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); String day =sdf.format(dt); return day; } }

