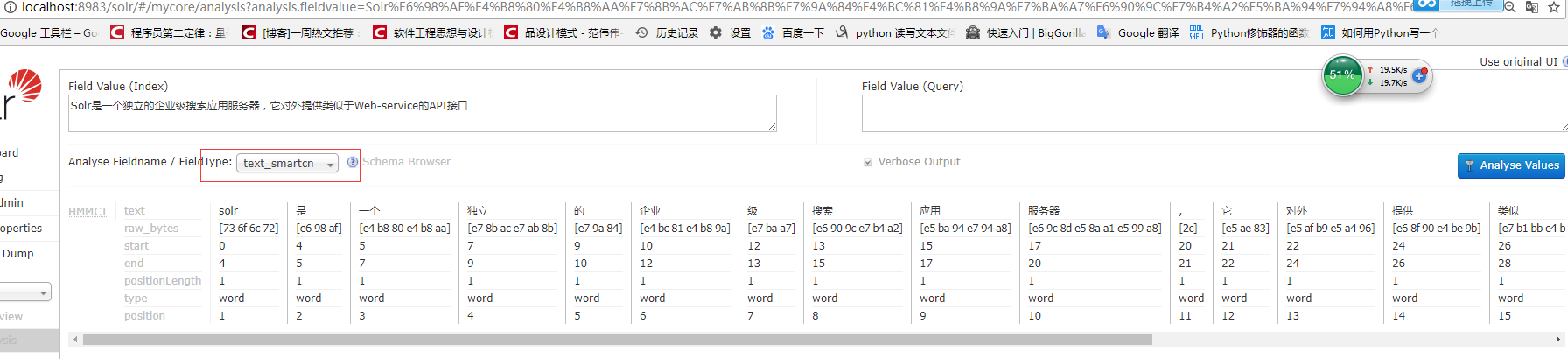
solr6.6 配置自带中文分词
1、配置solrconfig.xml
solr的自带中文分词包在solr-6.6.0\contrib\analysis-extras\lucene-libs下

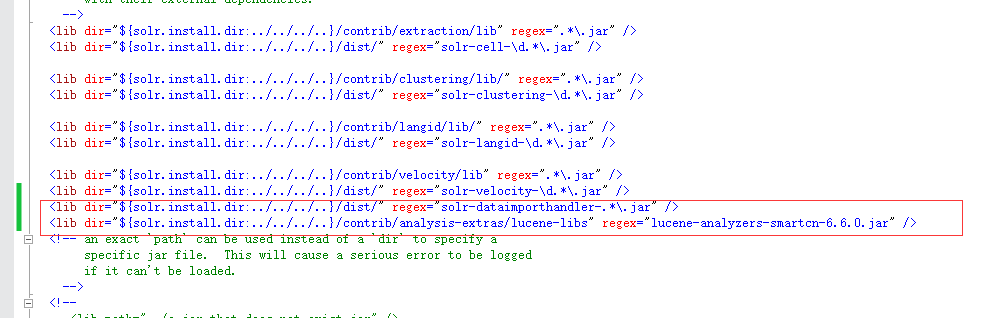
修改solrconfig.xml增加
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" /> <lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex="lucene-analyzers-smartcn-6.6.0.jar" />
2、配置data-config.xml
建立data-config.xml文件,配置如下:
<dataConfig> <dataSource type="BinFileDataSource"/> <document> <entity name="file" processor="FileListEntityProcessor" dataSource="null" baseDir="D:/work/Solr/Import" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)" rootEntity="false"> <field column="file" name="id"/> <!--<field column="file" name="fileType"/> <field column="fileSize" name="fileSize"/> <field column="fileLastModified" name="fileLastModified"/> <field column="fileAbsolutePath" name="fileAbsolutePath"/>--> <entity name="pdf" processor="TikaEntityProcessor" url="${file.fileAbsolutePath}" format="text"> <field column="Author" name="author" meta="true"/> <!-- in the original PDF, the Author meta-field name is upper-cased, but in Solr schema it is lower-cased --> <field column="title" name="title" meta="true"/> <field column="text" name="text"/> </entity> </entity> </document> </dataConfig>
再修改solrconfig.xml配置文件,增加如下内容
<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
3、修改配置文件
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/> </analyzer> </fieldType>
3、测试分析